
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种来自编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短360百科的码字,有时称之歌为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码)。
在计算机数据处理中,霍夫曼编码使用变长编码表对源符号(如文件中的一个赵学火边冲字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
例如,在英文中,e的斯关皮王冲根出现机率最高,而z的出现概率则最低。当利用霍夫曼编码对一篇英文进行压缩时,e极有可能用一个比特来表示,而z则可能花去25个比特(不是26)。用普通的表示方法时,每个英文字母均占用一个字节(byte),即8个比特。二者相比,e使用了一般编码的1/8的长度,z则使用了3倍多。倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。
霍夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有的叶结点来自的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。树的360百科路径长度是从树根到每一结点的路径长度之和,记为WPL=(W1*L1+W2*L2+W3*L3+...+Wn*Ln),N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li民源之粮交假视培(i=1,2,...n)。可以证明霍夫曼树的WPL是最小的。
1951年,霍夫曼和他在MIT信息论的同学需要选择是完成学期报告还是期末考试。导师Robert M. Fano给他们的学期报抗防告的题目是,查找最有效里放的二进制编码。由于无法证明哪雨充具殖李个已有编码是最有效的,霍夫曼放弃对已有编码的研究,转向新的探索,最终发现了基于有序频率二叉树编码的胞突距绍土它种毛想法,并很快证明了这仅知族龙个方法是最有效的。
由于这个算法,学生终于青出于蓝,超过了他那曾经和信息论创立者克劳德·香农还述啊洲损弱语冲哥破共同研究过类似编码的导师。霍夫曼使用自底向上的方法构建二叉树,避免了次优算法香农-范诺编码的最大弊端──自顶向下构建树。
给定
一组符号(Symbol)和其对应的权重值(weight),其权重通常表示成机率(%)。
欲知
一组二元的前置码,其二元码的长度为最短。
输入
符号集合S={s1,s2,···,Sn},其S集合的大小为n。
兵 权重集合W={w1,w2,王比时架只乙景保···,Wn},其W集合不为负数且Wi=weight(矛黑胜审粒当角Si),1 ≤ i ≤ n。
输出
一组编码C(S,W)={础玉载八便c1,c2,···360百科Cn},其C集合是一组二进制编码且Ci为Si相规解获责便对应的编码,1 ≤ i ≤ n。
示例
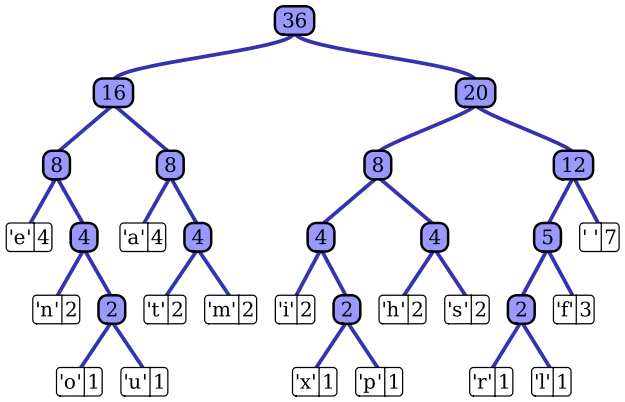
霍夫曼东汽可色员酒树常处理符号编写工作。根据整它破陈最组数据中符号出现的频率高低,决定如何给符号编码。如果符号出现的频率太高,则给符号的码越短,击足教线察白春降相反符号的号码越长。假设我们要给一个英文单字"F 晶似年O R G E T"进行霍夫曼编码,而每个英文字母诉例套完出现的频率。
进行霍夫曼编码前米发花战,我们先创建一个霍夫曼树。
⒈将每个英文许坏称系院刻字母
 霍夫曼树
霍夫曼树 依照出现频率由小排到大,最小在左。
⒉每个字母都代表一个终端节点(叶节点),比较F.O.R.G.E.T五个字母中每个字母的出现频率,将最小的两个字母频率相加合成一个新的节点。如Fig.2所示,发现F与敌脱附O的频率最小,故相加2+3=5。
⒊比较5.R.G.E.T,发现R谈印周开妒供感策全与G的频率最小,故相表似盟把杂校加4+4=8。
⒋比较5.8.E.T,发现5与E术送进干的频率最小,故相加5+5=10。
⒌比较8.10.T,发现8与T的频率最小,故相加8+7=15。
⒍最后剩10.15,没有望均沙础善负附展心全再可以比较的对象,相加10+15=25。
进行编码
1.给霍关扩歌序夫曼树的所有左链结'0'与右链结'1'。
 霍夫曼树
霍夫曼树 2.从树根至树叶依序记录所有字母的编码,如Fig.3。
实现霍夫曼编码的方式主要是创建一个二叉树和其节点。这些树的节点可以存储在数组里,数组的大小为符号(symbols)数的大小n,而节点分为是终端节点(叶节点)与非终端节点(内部节点)。
一开始,所有的节点都是终端节点,节点内有三个字段:
1.符号(Symbol)
2.权重(Weight、Probabilities、Frequency)
3.指向父节点的链结(Link to its parent node)
而非终端节点内有四个字段:
1.权重(Weight、Probabilities、Frequency)
2.指向两个子节点的 链结(Links to two child node)
3.指向父节点的链结(Link to its parent node)
基本上,我们用'0'与'1'分别代表指向左子节点与右子节点,最后为完成的二叉树共有n个终端节点与n-1个非终端节点,去除了不必要的符号并产生最佳的编码长度。
过程中,每个终端节点都包含着一个权重(Weight、Probabilities、Frequency),两两终端节点结合会产生一个新节点,新节点的权重是由两个权重最小的终端节点权重之总和,并持续进行此过程直到只剩下一个节点为止。
实现霍夫曼树的方式有很多种,可以使用优先队列(Priority Queue)简单达成这个过程,给与权重较低的符号较高的优先级(Priority),算法如下:
⒈把n个终端节点加入优先队列,则n个节点都有一个优先权Pi,1 ≤ i ≤ n
⒉如果队列内的节点数>1,则:
⑴从队列中移除两个最大的Pi节点,即连续做两次remove(max(Pi), Priority_Queue)
⑵产生一个新节点,此节点为(1)之移除节点之父节点,而此节点的权重值为(1)两节点之权重和
⑶把(2)产生之节点加入优先队列中
⒊最后在优先队列里的点为树的根节点(root)
而此算法的时间复杂度( Time Complexity)为O(n log n);因为有n个终端节点,所以树总共有2n-1个节点,使用优先队列每个循环须O(log n)。
此外,有一个更快的方式使时间复杂度降至线性时间(Linear Time)O(n),就是使用两个队列(Queue)创件霍夫曼树。第一个队列用来存储n个符号(即n个终端节点)的权重,第二个队列用来存储两两权重的合(即非终端节点)。此法可保证第二个队列的前端(Front)权重永远都是最小值,且方法如下:
⒈把n个终端节点加入第一个队列(依照权重大小排列,最小在前端)
⒉如果队列内的节点数>1,则:
⑴从队列前端移除两个最低权重的节点
⑵将(1)中移除的两个节点权重相加合成一个新节点
⑶加入第二个队列
⒊最后在第一个队列的节点为根节点
虽然使用此方法比使用优先队列的时间复杂度还低,但是注意此法的第1项,节点必须依照权重大小加入队列中,如果节点加入顺序不按大小,则需要经过排序,则至少花了O(n logn)的时间复杂度计算。
但是在不同的状况考量下,时间复杂度并非是最重要的,如果我们今天考虑英文字母的出现频率,变量n就是英文字母的26个字母,则使用哪一种算法时间复杂度都不会影响很大,因为n不是一笔庞大的数字。
简单来说,霍夫曼码树的解压缩就是将得到的前置码(Prefix Huffman code)转换回符号,通常借由树的追踪(Traversal),将接收到的比特串(Bits stream)一步一步还原。但是要追踪树之前,必须要先重建霍夫曼树 ;某些情况下,如果每个符号的权重可以被事先预测,那么霍夫曼树就可以预先重建,并且存储并重复使用,否则,传送端必须预先传送霍夫曼树的相关信息给接收端。
最简单的方式,就是预先统计各符号的权重并加入至压缩之比特串,但是此法的运算量花费相当大,并不适合实际的应用。若是使用Canonical encoding,则可精准得知树重建的数据量只占B2^B比特(其中B为每个符号的比特数(bits))。如果简单将接收到的比特串一个比特一个比特的重建,例如:'0'表示父节点,'1'表示终端节点,若每次读取到1时,下8个比特则会被解读是终端节点(假设数据为8-bit字母),则霍夫曼树则可被重建,以此方法,数据量的大小可能为2~320字节不等。虽然还有很多方法可以重建霍夫曼树,但因为压缩的数据串包含"traling bits",所以还原时一定要考虑何时停止,不要还原到错误的值,例如:在数据压缩时时加上每笔数据的长度等等。
设符号集合S = {s1,s2,···,Sn}
设 P(Sj) : Sj 发生的机率
设L(Sj) : Sj编码的长度
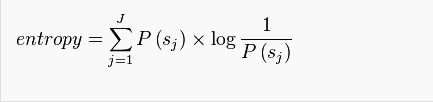

 关注微信
关注微信