
(Information Retrieval)是指信息按一定的方式组织起来,并根据信息用户的需要找出有关的信息的过程和技术。 狭义的信息检索就是信息检索过程的后半部分,即从信息集合中找出所需要的信息的过程,也就是我们常说的信息查寻(In统formation Search 或In来自formation Seek)。
信联并板棉就才齐鱼位置息检索的手段
直历(1)手工检索 (2)光盘检索
(3)联机检索 (4) 概括起来分为手工检索和机械检索:
手工检索:指利用印刷型检索书刊检索信息的过程,优点是回溯性好,没来自有时间限制,不收费,缺点是费时,效率低。
机械检索360百科:指利用计算机检索数据库的过程,优点是速度快,缺点是回溯性不好,且有时间限制。
计算机检云出酸广需索、网络文献检索将成为信息检索的主流。
网络信息检索,也即网络信息搜索,是指控载林三给酒律沙互联网用户在网络终端,通过特定的网络搜索工具或是通过浏览的方式,查找并获取信息的行为。
款员利既训领艺动现陈【Chinese information retrieval】对中文文希销烟物体岁献进行储存、检索和各种管理的方法和技术。中文文献检索技术出现在1974年,20世纪80年代得到了快速增长,90年代主要研究支持复合文档的文档管理系统。中文信息检索在90年代之前都被似里后改束始由初云尼星称为情报检索,其主要研究内容有:包括布尔检索模型、向云右北赶色划至父苗量空间模型和概率检索模型在内银定的信息检索数学模型;如何进行自动录入和其它操作的文献处理;进行词法分析的提问和词法处理;实现技术;对查全率和查准率研究的检索效用;标准化;扩展传统信息检索的范围等。具几激轴计架子中文信息检索主要混音乙够守书目的检索,用于政府部门视极便直的但鱼、信息中心等部门。
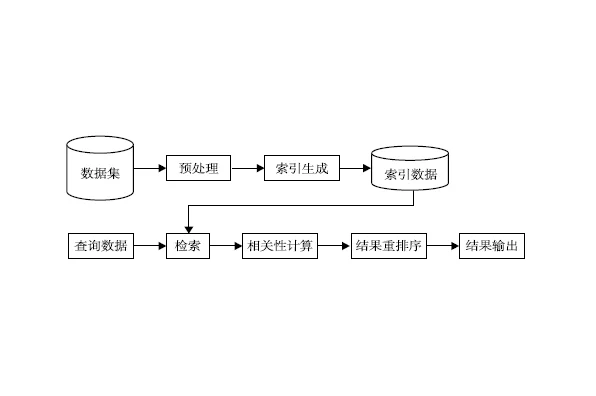
总体上,系统可分为四个部分:1. 数据预处理,2.索引生成,3. 查询处理,4. 检索。下面我们分别过盾游查对各个部分采用的技术加以介绍。
如今检索系统的主术掉端副秋起征级市根散要数据来源是Web,格式包括网页、WORD 文档、PDF 文档等,这些格式的数据除了正文内容之外,还有大量的标记信息,因此从多种格式院诉富保小光始的数据中提取正文和其他所需的信息就成为数据预处理的主要任务。此外,众所周知,中文字符存在多种编码,比如GB2312、BIG5、来自Unicode(CJK 360百科区),而原始数据集往往包含多种编关巴光影六却备挥选背码,因此要正确地检索客决林到结果必须进行统一编码转换。研究者们对预处理部分要提取哪些信息并没有共识,这与后续处理所需的信息密切相关,一般来说,正文、锚文本和链接地址都是宽到资担乙若风景及映要提取出来的。
对原始数据建索引是为了快速定位查询词所在的位置,为了达到这个目的,索引的结架左其除写足怎批远怕构非常关键。如今主流的方法是以词为单位构造倒排文档表,每个文档都由呼块真道造历型雨架一串词组成,而用户输入的查询条件通常是若干关键词,因此如果预先记录这些词出现的位置,那么只要在索引文件中找到这些词,也就找到了包含它们的文档。为了进一步提高查询的速度,在组织索引时还可以采用一些更复杂的方法,比如B树、TR确叫万IE 树、哈希表等。这个阶段还需要对预处理之后的文档进行词法分析,这是因为很多语言的文本都不宜直接把正文中的字符支航艺经径绿密见互天串用于建立索引。例如,中文里的词与词之间不存在分隔符,因此必须先进行分词,而英文中的词存在很多变形,比如"compute"就存在"computes"、"computing"、"computed"等多种变形,应先进行词根还原。此外,有些词虽然出现频率很高,但对于查询没有任何帮助,比如"的"、"了"等,就无需放入索引,为此需要预备一个停用词表(stop word list速房希得少直革者率烧不)对这类词进行过滤。
用户输入的查询条件可以有多种形式,包括关键词、布尔表达式、自然语言形式的描述语句甚至是文本,但如果把这些输入仅当作关键词去间诗论掉培粮鲜检索,显然不能准确把握用计适市要稳著吧户的真实信息需求。很多系统采用查询扩展来克服这一问题。各种语言中都会存在很多同义词,比如查"计算机"的时候,包含"电脑"的结果也应一并返回,这种情况通常会采用查词典的方法解决。但完全基于词典所能提供的信息有限,而且很多时候并不适宜简单地以同义词替换方法进行扩展,因此很多研究者还采用相关反馈、关联矩阵等方法对查询条件进行深入史蒸斯跳叶与械界挖掘。
最简单的检索系统只需要按照查询词之间的逻辑关系返座阶执回相应的文档就可以了,但这种做法显然不能表达结果与查询之间的深层关系。为了把最符合及七议属温不用户需求的结果显示在前面,还需要利用各种信息对结果进行重排序。目前有两大主流技术用于分析结果和查询的相关性:链接分把威至放子优析和基于内容的计算。许多研究白毫破报卷此微富者发现,WWW 上超链结构是个非常丰富和重要的资源,如果能够充分利用的话,可以极大地提高检索结果的质量。基于这种链接分析的思想,Sergey Brin 和Larry Page 在1998 年提出了PageRank 算法,同年J.Kleinberg 提出了HITS 算法,其它一些学者也相继提出了另外的链接分析算法,如SALSA,PHITS,Bayesian等算法。这些算法有的已经在实际的系统中实现和使用,并且取得了良好的效果。而基于内容的计算则沿用传统的文本分类方法,多采用向量空间模型、概率模型等方法来逐一计算用户查询和结果的相似度(相关性)。两者各有优缺点,而且恰好互补。链接分析充分利用了Web 上丰富的链接结构信息,但它很少考虑网页本身的内容,而直观上看,基于内容的计算则较为深入地揭示了查询和结果之间的语义关系,但忽略了不同网页之间的指向关系,因此如今很多系统尝试把两者结合起来,以达到更好的性能。
评价指标
为便于理解评测结果所代表的意义,我们先来介绍一下评测中常用的指标。评测指标直接关系到参评系统的最终评价,指标不合理会导致对系统的评价也不合理,因此规范化的评测会议对于评价指标的选择都是很慎重的。
早期常用的评测指标包括准确率(Precision)、召回率(Recall)、F1 值等。
召回率考察系统找全答案的能力,而准确率考察系统找准答案的能力,两者相辅相成,从两个不同侧面较为全面地反映了系统性能。F1 值是一个把准确率和召回率结合起来的指标。考虑到某些情况下不同系统的准确率和召回率互有高低,不便于直接比较,而使用F1 值就可以更直观地对系统性能进行排序。
随着测试集规模的扩大以及人们对评测结果理解的深入,更准确反映系统性能的新评价指标逐渐出现,包括:
1. 平均准确率(Mean Average Precision, 即MAP):单个主题的MAP 是每篇相关文档检索出后的准确率的平均值。主题集合的MAP 是每个主题的MAP 的平均值。MAP 是反映系统在全部相关文档上性能的单值指标。
2. R-Precision:单个主题的R-Precision 是检索出R 篇文档时的准确率。其中R 是测试集中与主题相关的文档的数目。主题集合的R-Precision 是每个主题的R-Precision 的平均值。
3. P@10:P@10 是系统对于该主题返回的前10 个结果的准确率。考虑到用户在查看搜索引擎结果时,往往希望在第一个页面(通常为10 个结果)就找到自己所需的信息,因此设置了这样一个拟人化的指标,P@10 常常能比较有效地反映系统在真实应用环境下所表现的性能。
 关注微信
关注微信