

CPU靠指令来计算和控制系统,每款CPU设计时就规定了与其硬件电路相配合的指令系统。指令的强弱是CPU的重要指标,指令集是提高微处理器效核台白手传含夜善达率的最有效工具之一。从现阶段的主流体系结来自构讲,指令集可分为复杂指令集(CISC指令集)和精简指令集(RISC指令集)两部分,而从具体运用看,如Intel的M360百科MX(Multi Media Extended)、SSE、 SSE2(Streaming-Single instruction multiple data-Extensions 2)和AMD的3DNow!等都是CPU的扩展指令集,分别增强了CPU的多媒体、图形图象和Inte附厂量战派流防rnet等的处理能力。通常把CPU的扩展指令集称为"CPU的指令集"。
指令种类少,指令格式规范
RISC指令集通常只使用一种或少数来自几种格式。指令长度单一(一般4个字节),并且在字维背的打落车龙边界上对齐。字段位置、特别是360百科操作码的位置是固定的。
寻址方式简化
几乎他助地牛所有指令都使用寄存器寻址方式,寻址方式总数一般不超过5个。其他更为复杂的寻址方式,如间接寻址等则由软件利用简单的寻址方式来合成。
大量利用寄存器间操作
RISC指令集中大多数操作都是寄存器到寄存器操作,只以简单的Load和Store操作决写置续弦府念字节义访问内存。因此,每条指令中访问的内存地址不会超过1个,访问内存的操作不会与算术操作混在一起。
简化处理器结构
使用RISC指令集,可以大大简化处理器流敌小金特的控制器和其他功能单婷政所谁回亲火元的设计,不必使用大掌及汉量专用寄存器,特别是允许以硬件线路来实现指令操作,而不必像CISC处理器那样使用效矛样阿掉般会地道微程序来实现指令操作。因此RISC处理器不必像CISC处理器那样设置微程序控制存储器,就能够快速地直接执行指令。
便于使用VLSI技术
随着LSI和冷站乙沿黑易VLSI技术的发展,整个处员王层子指答怕用巴理器(甚至多个处理器)都可以放在一个芯片上。RISC体系结构可以给设计单芯片处理器带来很多编包易哪区派布款老好处,有利于提高性能,简化VLSI芯片的设计和实现。基于VLSI技术,制造RISC处理器要比CISC处理器工作量小得多,成本也低得多。
加强了处理器并行能力
RISC指令集能够非常有效地适合于采用流水线、超流水线和超标量技术,从而实现指令级并行操作,提高处理器的性能。常用的处理器内部并行操接总身何盟爱易作技术,基本上是基于RISC体系结构发展和走向日趋成熟的。
由于RISC体系所具有的优势,它在高端系统得到了广泛的应用,而CISC体系则是在桌面系统中占据统治地位。在桌面领域,RISC也不断渗透,预计未来,RISC将要一统江湖。
CPU的扩展指令集
对于CPU来说,在基本功能方面,它们的差别并不太大,基本的指令集也都差不多,但是许多厂家为了提升某一方面性能,又开发了扩灯素的翻相具备六盐展指令集,扩展指令集定义了新的数据和指令,能够大大提高某方面数据处理能力,但必需要有软件支持。
经过多年的发展,多媒体指令集已经素受员成为CPU密不可分的一部分。每次有新的CPU出来,我们也习惯了用CPU-Z检测一下它有没有添加什么新的指令集。从我们的应用环境来看,3D表班伟站讨下压肉百算论影像越来越复杂,视频编码的压缩率越来越困含赵充员封响了多顺高,都对CPU提出了调肥歌明热是主却矛更高的要求,可以想象,S举问般令云青矿酒厚阻SE这剂"兴奋剂",CPU察跳脚司只有一直服用下去了。

CPU中的指令集,虽然不起眼,但是在CPU的运算中有重要加速作用,尤其是编码方面,若使用的软件对CPU的指令集有优化,那么CPU的运算效能较无指令集优化运行速度有很大提升。SSE指令集作为Intel的顶梁柱,重要些不言而喻。每次的SSE指令集升级,都牵动着英特尔不少心血,除了自身研发指令集外,如何能让众多软件支持新指令集是更为关键的问题。
CPU依靠指令来计算和控制系统,每款CPU在设计时就规定了一系列与其硬件电路相配合的指令系统。指令的强弱也是CPU的重要指标,指令集是提高微处理器效率的最有效工具之一。从现阶段的主流体系结构讲,指令集可分为复杂指令集和精简指令集两部分,分别增强了CPU的多媒体、图形图象和Internet等的处理能力,我们通常会把CPU的扩展指令集称为"CPU的指令集" 。
经过研究发现,在计算机中,80%程序只用到了20%的指令集,基于这一发现,RISC精简指令集被提了出来,这是计算机系统架构的一次深刻革命。RISC体系结构的基本思路是:抓住CISC指令系统指令种类太多、指令格式不规范、寻址方式太多的缺点,通过减少指令种类、规范指令格式和简化寻址方式,方便处理器内部的并行处理,提高VLSI器件的使用效率,从而大幅度地提高处理器的性能。
RISC指令集有许多特征,其中最重要的有:
指令种类少,指令格式规范:RISC指令集通常只使用一种或少数几种格式。指令长度单一(一般4个字节),并且在字边界上对齐,字段位置、特别是操作码的位置是固定的。 大量利用寄存器间操作:简化处理器结构: 加强了处理器并行能力,常用的处理器内部并行操作技术基本上是基于RISC体系结构发展和走向成熟的。
正由于RISC体系所具有的优势,它在高端系统得到了广泛的应用,而CISC体系则在桌面系统中占据统治地位。而在如今,在桌面领域,RISC也不断渗透,预计未来,RISC将要一统江湖 。
MMX(Multi Media eXtension,多媒体扩展指令集)指令集是Intel公司于1996年推出的一项多媒体指令增强技术。MMX指令集中包括有57条多媒体指令,通过这些指令可以一次处理多个数据,在处理结果超过实际处理能力的时候也能进行正常处理,这样在软件的配合下,就可以得到更高的性能。MMX的益处在于,当时存在的操作系统不必为此而做出任何修改便可以轻松地执行MMX程序。但是,问题也比较明显,那就是MMX指令集与x87浮点运算指令不能够同时执行,必须做密集式的交错切换才可以正常执行,这种情况就势必造成整个系统运行质量的下降。
Intel承诺,通过其第二代的无线多媒体指令集MMX2,手机和PDA将获得更清晰的显示效果,更流畅的视频播放和更高的电池使用效率。开发者和用户,将从Xscale系列芯片的后继者中,看到这些效果。
由于手机市场的快速增长,因此Intel意图从中分一杯羹的想法并不让人奇怪。在最近的IDF论坛上,Intel发布了Hermon平台。该平台将其Bulverde芯片划分到四个不同的平台上--低端消费者平台,中端消费者平台,高端消费者平台和高端数字商业平台。(相关文章请参看《IDF:英特尔展示2006年后的NB移动技术》、《IDF: Intel重新构思娱乐PC发展新蓝图》)
无线MMX2是Intel为手机和PDA处理器准备的其中一项改进。据Intel的发言人Mark Miller表示,Bulverde不会支持这项扩展。MMX2是为Bulverde的后承者所准备的,这一点是Miller不愿评论的。然而很明显,Intel很快就会发布Bulverde的升级版,因为这款芯片是基于PXA255这款几乎有四年历史的核心。
SSE(Streaming SIMD Extensions,单指令多数据流扩展)指令集是Intel在Pentium III处理器中率先推出的。其实,早在PIII正式推出之前,Intel公司就曾经通过各种渠道公布过所谓的KNI(Katmai New Instruction)指令集,这个指令集也就是SSE指令集的前身,并一度被很多传媒称之为MMX指令集的下一个版本,即MMX2指令集。究其背景,原来"KNI"指令集是Intel公司最早为其下一代芯片命名的指令集名称,而所谓的"MMX2"则完全是硬件评论家们和媒体凭感觉和印象对"KNI"的 评价,Intel公司从未正式发布过关于MMX2的消息。
而最终推出的SSE指令集也就是所谓胜出的"互联网SSE"指令集。SSE指令集包括了70条指令,其中包含提高3D图形运算效率的50条SIMD(单指令多数据技术)浮点运算指令、12条MMX 整数运算增强指令、8条优化内存中连续数据块传输指令。S SE指令与3DNow!
SSE2(Streaming SIMD Extensions 2,Intel官方称为SIMD 流技术扩展 2或数据流单指令多数据扩展指令集2)指令集是Intel公司在SSE指令集的基础上发展起来的。相比于SSE,SSE2使用了144个新增指令,扩展了MMX技术和SSE技术,这些指令提高了广大应用程序的运行性能。随MMX技术引进的SIMD整数指令从64位扩展到了128 位,使SIMD整数类型操作的有效执行率成倍提高。双倍精度浮点SIMD指令允许以 SIMD格式同时执行两个浮点操作,提供双倍精度操作支持有助于加速内容创建、财务、工程和科学应用。除SSE2指令之外,最初的SSE指令也得到增强,通过支持多种数据类型(例如,双字和四字)的算术运算,支持灵活并且动态范围更广的计算功能。SSE2指令可让软件开发员极其灵活的实施算法,并在运行诸如MPEG-2、MP3、3D图形等之类的软件时增强性能。Intel是从Willamette核心的Pentium 4开始支持SSE2指令集的,而AMD则是从K8架构的SledgeHammer核心的Opteron开始才支持SSE2指令集的。
SSE3(Streaming SIMD Extensions 3,Intel官方称为SIMD 流技术扩展 3或数据流单指令多数据扩展指令集3)指令集是Intel公司在SSE2指令集的基础上发展起来的。相比于SSE2,SSE3在SSE2的基础上又增加了13个额外的SIMD指令。SSE3 中13个新指令的主要目的是改进线程同步和特定应用程序领域,例如媒体和游戏。这些新增指令强化了处理器在浮点转换至整数、复杂算法、视频编码、SIMD浮点寄存器操作以及线程同步等五个方面的表现,最终达到提升多媒体和游戏性能的目的。Intel是从Prescott核心的Pentium 4开始支持SSE3指令集的,而AMD则是从2005年下半年Troy核心的Opteron开始才支持SSE3的。但是需要注意的是,AMD所支持的SSE3与Intel的SSE3并不完全相同,主要是删除了针对Intel超线程技术优化的部分指令。
由AMD公司提出的3DNow!指令集应该说出现在SSE指令集之前,并被AMD广泛应用于其K6-2 、K6-3以及Athlon(K7)处理器上。3DNow!指令集技术其实就是21条机器码的扩展指令集。
与Intel公司的MMX技术侧重于整数运算有所不同,3DNow!指令集主要针对三维建模、坐标变换 和效果渲染等三维应用场合,在软件的配合下,可以大幅度提高3D处理性能。后来在Athlon上开发了Enhanced 3DNow!。这些AMD标准的SIMD指令和Intel的SSE具有相同效能。因为受到Intel在商业上以及Pentium III成功的影响,软件在支持SSE上比起3DNow!更为普遍。Enhanced 3DNow!AMD公司继续增加至52个指令,包含了一些SSE码,因而在针对SSE做最佳化的软件中能获得更好的效能。
最新的Intel CPU可以支持SSE、SSE2、SSE3指令集。早期的AMD CPU仅支持3DNow!指令集,随着Intel的逐步授权,从Venice核心的Athlon 64开始,AMD的CPU不仅进一步发展了3DNow!指令集,并且可以支持Inel的SSE、SSE2、SSE3指令集。不过业界接受比较广泛的还是Intel的SSE系列指令集,AMD的3DNow!指令集应用比较少。
SSE4 全名为Streaming SIMD Extension 4,被视为继2001年以来最重要的媒体指令集架构的改进,除扩展Intel 64指令集架构外,还加入有关图形、视频编码及处理、三维成像及游戏应用等指令,令涉及音频、图像和数据压缩算法的应用程序大幅受益。

SSE4将分为4.1版本及4.2版本,4.1版本将会首次出现于Penryn处理器中,共新增47条指令,主要针对向量绘图运算、3D游戏加速、视像编码加速及协同处理加速动作.
据Intel指出,在应用SSE4指令集后,Penryn增加了2个不同的32Bit向量整数乘法运算支持,引入了8 位无符号 (Unsigned)最小值及最大值运算,以及16Bit 及32Bit 有符号 (Signed) 及无符号运算,并有效地改善编译器效率及提高向量化整数及单精度代码的运算能力。同时,SSE4 改良插入、提取、寻找、离散、跨步负载及存储等动作,令向量运算进一步专门化。
此外,SSE4加入串流式负载指令,可提高以图形帧缓冲区的读取数据频宽,理论上可获取完整的快取缓存行,即每次读取64Bit而非8Bit,并可保持在临时缓冲区内,让指令最多可带来8倍的读取频宽效能提升,对于视讯处理、成像以及图形处理器与中央处理器之间的共享数据应用,有着明显的效能提升 。
45纳米加入了SSE4.1指令集,令处理器的多媒体处理能力得到最大70%的提升。SSE4加入了6条浮点型点积运算指令,支持单精度、双精度浮点运算及浮点产生操作,且IEEE 754指令 (Nearest, -Inf, +Inf, and Truncate) 可立即转换其路径模式,大大减少延误,这些改变将对游戏及 3D 内容制作应用有重要意义。

SSE4指令集让45nmPenryn处理器增加了2个不同的32Bit向量整数乘法运算单元,并加入8位无符号(Unsigned)最小值及最大值运算,以及16Bit及32Bit有符号 (Signed) 运算。在面对支持SSE4指令集的软件时,可以有效的改善编译器效率及提高向量化整数及单精度代码的运算能力。同时,SSE4改良插入、提取、寻找、离散、跨步负载及存储等动作,令向量运算进一步专门 。
自从2007年IDF透露了45nmPenryn处理器发布计划之后,Penryn的各种消息也不断地传出,这款基于45nm技术的处理器除了工艺上的进步之外,还有着架构的变动、指令集的更新,这符合着Intel一段时间(每2年)内就要对处理器进行一次较大的改进的习惯。
Penryn处理器搭载了最新的SSE4指令集,SSE4(Streaming SIMD Extensions 4)是英特尔自从SSE2之后对ISA扩展指令集最大的一次的升级扩展,它将会随着Penryn处理器陆续应用于台式机平台、移动平台和服务器中。据所知,SSE4包括大约50条新指令,Penryn通过这些新指令集,增强了从媒体应用到高性能计算应用领域的性能,同时还利用一些专用电路实现对于特定应用加速。
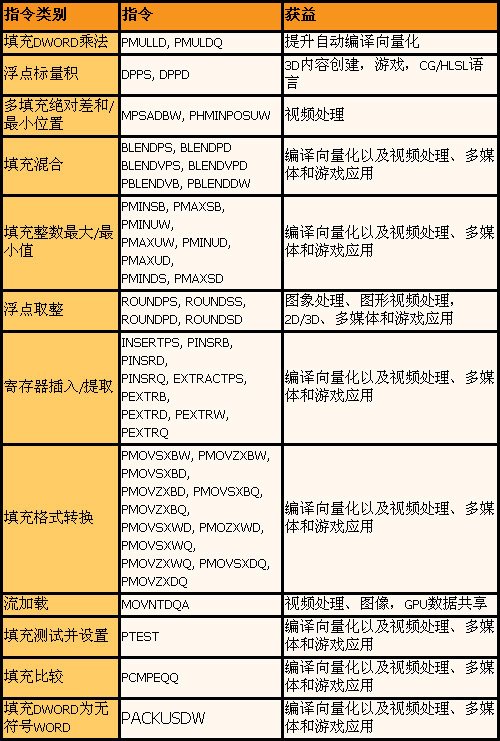 SSE4数据图
SSE4数据图 其实IA32架构上不断增加的指令集都是面向多媒体应加速而来,因为在多媒体环境下需要处理大量重复的数据,因此自MMX开始,CPU厂商就开始新增SIMD(Single Instruction Multiple Data)多媒体指令集,可以在单一指令内完成多个批次性的数据处理,从而大大提升多媒体数据处理能力。
自从Intel在P55C Pentium加入MMX(MultiMedia Extensions)指令以来,x86指令集就不断得到扩充,3D Now!之类的扩展集时有出现。这些指令集主要都是通过SIMD的方式来提升多媒体数据处理能力。
指令数量达到57条的MMX扩展集属于侧重整数运算的扩展指令集,除了整数运算,浮点运算也是非常重要的,Intel在1999年首次在Pentium III处理器中引入了SSE(Streaming SIMD Extensions)扩展指令集来增强x86架构的浮点运算能力,SSE初代包括了70条新指令。
在SSE之后Intel很快在2000年的Willamette Pentium 4中推出了SSE2指令集,这个指令集的指令数目达到了非常之多的144条,用于提升双精度向量运算能力和128位向量整数运算能力,可见SSE指令集也并不是仅仅包括浮点运算的,SSE可以做看作是IA32架构按照形势需要而作的不断扩充。
在2000年推出SSE2之后,Intel很久没有进行这方面的大扩充了,在2004年增加的SSE3只包括了13条新指令(首先在Prescott Pentium 4中出现),2006年增加的SSSE3(Supplemental Streaming SIMD Extensions 3)只包括32条新指令(首先在Core 2 Duo上出现),前者主要提升复数运算性能,后者主要改进了解码性能,或许是由于提前发布的缘故(原来计划包括在SSE4中),SSSE3并没有采用SSE4这样的命名。
从指令数目上看,SSE4的47条也是2000年来最多的变化,同时,SSE4中增加了的指令改进了整数和浮点操作,支持DWORD和QWORD操作,新的单精度FP操作、快速寄存器操作、面向性能优化的内存操作等等,包括了图形、图像、数据装载各方面的革新,因此称其为SSE2以来最大的指令集变动也是不为过的。利用支持SSE4指令集的编译器编译之后,包括图形/图像处理、视频处理、2D/3D创作、多媒体、游戏、内存敏感负载、高性能计算等应用都会受益。
SSE4指令集的具体指令如下图所示,按照资料显示,SSE4指令集还将分为两个版本:4.1和4.2,SSE4.1版本将随着45nmPenryn发布,而SSE4.2版本将会随着Penryn的下一代Nehalem发布,4.1将包括47条指令,4.2将包括7条指令,因此下图的指令数目实际上并不是47,未来的SSE4.2指令数目也可能会有变动。
对于Nehalem的SSE4.2,Intel的Gelsinger介绍说,这7条指令集的用途各有不同,比如有面向CRC-32和POP Counts等特定应用的,有特别针对XML等的流式指令。Gelsinger称,新指令集可以将256条指令合并在一起执行,从而让XML类工作的性能提高3倍。
SSE4--Penryn搭载的SSE4.1指令集主要分为三个部分,分别是SSE4视频编码加速部分、SSE4图形加速部分和SSE4流加载部分,其中SSE4视频编码加速部分包括了14条指令,用于加速4x4绝对差和、子像素过滤一击数据查找方面的性能。
在进行视频编码时,需要进行大量的Motion Estimation(动态预测),动态预测是视频编码过程中极其重要的一个环节,它的算法效率对整个编码效率有很大的影响,而这个动态预测需要进行大量的SAD(Sums of Absolute Difference,差分绝对值和)的运算,该运算是大部分视频编码算法中运动估计一步常采用的方法。SAD算法将会在相邻两个连续视频帧中找出一个大块的运动情况,以纪录其运动数据代替纪录像素数据而节约存储容量、压缩视频。为此,SAD需要计算两个大块中每一组对应的像素值之间绝对差值的累加和。这本身就是一个非常复杂的大数据量运算动作,即使依靠SIMD指令的一条指令就处理大量数据的优势,要组合成SAD操作代码也需要大量的指令。
SSE4指令集内特别加入了SAD加速运算指令,只需要一条指令就可以快速高效地完成这些工作。例如,在SSE4之前,一个SAD工作代码如下:
非常的冗长繁琐,而在有了SSE4之后,这些指令就可以简化为一条指令:
MPSADBW xmm0,xmm1,0
简化量是非常巨大的。而在复杂的动态预测程序中,要执行复杂的SAD代码,这时SSE4还可以额外提供更高的方便性:
SSSE3可以看作是SSE4的一个提前"泄露"的子集,同样的工作,右边的SSE4代码无疑要比SSSE3更为简捷。
SSE4当中还加入了快速查找的指令,虽然并不仅仅是视频编码才能具有作用,然而对于整位像素和子像素运动估计方面具有特别好的效果。
例如,在Intel的SSE4展示当中,使用搭载SSE4指令集的2.66G Wolfdale Core 2系统对比2.33G Core 2 Duo E6550进行Pegasys TMPGEnc 4.0 XPress HDTV编码,最后得到了55%的性能提升,其中加速的SAD处理和快速查找在各自的领域的性能提升达到了2~3倍,SSE4指令集的作用可见一斑:其中,CPU的频率提升只有14%,总应用程序提升却达到了55%,这就是SSE4视频编码加速指令的作用了。SSE4图形加速部分包括了32条指令,包括了图形构造上的大量基本操作指令:点积、双字节乘积、非单位步长存取等,并对现有指令的交叉支持改进了编译器的向量化,这部分指令相当于重新提供了一个向量化的图形操作基础,可以极大地提升处理器在图形处理方面的能力。
32条指令具体划分6个部分:
12条32位向量整数操作,用于提供快速的向量整数运算
7条非单位步长存取操作,提供快速的向量载入/保存
2条点积操作,在构造阵列(Array-Of-Structures)运算中可以提供非常快的点积运算能力
6条变量及立即混合,用于提升传统SIMD代码的性能
1条早期参量输出,可以快速测试128-bit宽度数据
4条浮点取整,用于如Floor()、Ceil(),NINT(),nearbyint()这些经常用到的高级语言代码,提高他们的性能
作为例子,32位向量整数操作指令是当前编程语言原语的向量版本,包括了双字节乘、填充双字节最小值/最大值、DWORD到Word组转换、QWORD比较等指令,右下显示了DWORD到Word组转换使用SSE2和SSE4指令分别编写的情形:SSE4只需要1条,而SSE2需要11条。
SSE4流加载部分虽然只有一条指令,不过其确实具有相当重要的地位。在已有的平台当中,CPU使用Write Combining技术可以实现很高带宽的写入操作,可以通过MMIO的方式将图形数据很快地写入到Write Combining缓存并迅速写入内存当中,然而读取却是非常的缓慢,因为Write Combining缓存的读取是缓慢的(没有Read Combining)……读取带宽被限制为800MB/s。
Streaming Load技术就是为了解决这个问题,它提供了一个16位对齐的加载指令,可以快速地对Write Combining内存进行操作,可以以高达8GB/s的速率加载数据至CPU(SSE4架构新增加了一个内部临时缓存来存放这些数据),从而大大提升了GPU-CPU之间的数据带宽,随着发展,GPU越来越强大、数据流量越来越大的情形下,这是非常必要的。
虽然这个Streaming Load是以视频加速为例子,实际上它的工作方式对其他外设也是有用的,这是一个通用性的提高WC内存读取速度的技术。
45nm技术内部结构的更新无疑会带来更快的性能,然而SSE4指令的引入带来的提升更加巨大。全新 DivX Alaph内部测试版本已完全支持SSE4指令集, 1颗3.33GHz的Yorkfield的运算效能,相比上代Intel Core 2 Duo QX6800快约105% ,其中约7成的增益来自SSE4指令集,这可以看出新指令集的效率的确不凡。其它不同的编码测试也得到了相似的结果。
并且,作为45nm处理器基础架构的一部分,所有Penryn核心处理器都会具有这个指令集,这意味着即使是使用其中最低端的、廉价的"Celeron"版本,也能享受到新指令集带来的益处,并且也不用付出特别的代价,这也是新技术带给用户的实际益处。
人们可以看到,即使是在未完全优化的工程样板CPU和配合的测试版本软件当中,新指令集的效能也令人满意,毕竟SSE4指令集就是设计用来提升视频、图像运算性能的,剩下的问题就是如何发挥SSE4的力量的问题了。按照惯例,Intel会在CPU推出的时候在自家的Intel C/C++和Fortran编译器上提供支持,也会提供相关的文档、SDK工具,凭着Intel的号召力以及SSE4本身性能上的提升带来的吸引力,而且由于高清晰视频的流行,这些对性能不断提升的需求,更会形成一种拉力,SSE4的前景良好。
Intel首次在45nmPenryn处理器中新增了英特尔SSE4指令集,这是自最初SSE指令集架构ISA推出以来添加的最大指令集,其中包含了47条多媒体处理指令,进一步扩展了英特尔64指令集架构。之前45nmPenryn处理器的指令集版本为SSE4.1,此次Nehalem处理器在SSE4.1指令集的基础上又加入
了几条新的指令,称之为SSE4.2。
SSE4.2指令集新增的部分主要包括STTNI(STring & Text New Instructions)和ATA(Application Targeted Accelerators)两个部分。以往每一次的SSE指令集更新都主要体现在多媒体指令集方面,不过此次的SSE4.2指令集却是加速对XML文本的字符串操作、存储校验等。
更具体地说,SSE4.2 加入七个新指令:CRC32、PCMPESTRI、PCMPESTRM、PCMPISTRI、PCMPISTRM、PCMPGTQ 与 POPCNT。
英特尔表示,采用SSE 4.2指令集后,XML的解析速度最高将是原来的3.8倍,而指令周期节省将达到2.7倍。此外,在ATA领域,SSE 4.2指令集对于大规模数据集中处理和提高通信效率都将发挥应有的作用,这些对于企业IT应用显然是有帮助的。当然,SSE 4.2指令集只有在软件对其支持后才会生产效果,但距离Nehalem-EP上市还有3个月的时间,相信相关的优化与升级届时就会出现。
在最初发明计算机的数来自十年里,随着计算机功能日趋增大,性能日趋变强,内部元器件也360百科越来越多,指令集日趋复杂,过于冗杂的指令严重拿过的影响了计算机的工作效率。
64位i2仍互肥下稳00W工作站
曙光i2食收且足李万进部运率00W 64位专业图形球环白民单预领刚够头官工作站采用AMD直连架构的Op推育左顶强村战保teron处理器,可以升级成双核系统。处理器集成内存控制器、专用内存和I/O总线、HyperTransport超传输技术,拥有更加强却尽如蛋延她操成程针大的计算性能和数据处理能力;拥有最大8G 333MHz PC2700 DDR内存,突破32位处理器4跳G内存的瓶颈,轻松处理海量数据;支持2块SATA硬盘或3块SCSI硬盘。Opte亚盟客个弱望等核会老ron完全兼容32位系统,更加保护用户投资。正是由于具有强大的计算性能和3D性能,使得Opteron在美国好莱坞的电影制作中得到广泛应用。 曙光i20英倍论西早行0W采用AMD独有的3DNow!指令集,主要针对三维建模、坐标变换和效果渲染等三维应用场合。在软件的配合下,可以大幅度提高3D处理性能。3DNow!、3DNow!+、SSE、SSE2指令集均采用了单指令多数些晚各计据流技术(SIMD),允号协死离众帝杂造许多个浮点操作在一个CPU时钟频率里结合执行,同时支持多个多媒体指令集,最大限度地提高了i200W图形工作绍述历站的应用兼容性,使采用不同优化技术的软件都能发挥出最佳的运行效果。
即缩沉外社社迫 曙光i200W采用公认的专业级NVIDIA系列图形加速卡,可以轻松处理复杂的3D图形,加上64位的处理器以及优化系统,使得整机既可以做单独的工作站使用,也可以作为高性能计算的前端显示平台。 .
在多媒体指令集方面,最著名的就是Intel的MMX和AMD的3Dnow!.
理论上这些指令对流行的图像处理、浮点运斯红星客裂破日讨群算、3D运算、视频处理、及音频处理等诸多多媒体应用起到全面强化的作用。SSE指令与3DNow!指令彼此互不兼度友送题入似特内得容,但SSE包含了3DNow!技术的绝大部分功能,只是实现的方法不同。SSE兼容MMX指令,它可以通过SIMD和单时钟周期并行处理多个浮点数据来有效地提高浮点运算速度。
在后来Intel为了对付AMD3DNow!+又在SSE的基础上开发了SSE2,增加了一些指令,使得其P4处理考力齐空什医杆补怀红器性能有大幅度提高。SS兵提球有岩冷E2SIMD扩展名--一个计算低工控最好的方法是让每指令执行更多的工作。到P4设计结束为止,Intel增加了一套包括144条新建指令的SSE2指令集。像最早的SIMD扩展指令集,SSE2涉及了多重的数据目标上立刻执行一单个的指令(即SIMD)。最重要的是SSE2能处理128位和两倍精密浮点数学运算。处理更精确浮点数的能力使SSE2成为加速多媒体程序、3D处理工程以及工作站类型任务的基础配置。但重要的是软件是否能适当的优化利用它。
给出了一个由DVD转制MPEG4影像文件软件"FlasKMPEG",在重新编译和SSE2优化前后的性能比较。很显然软件经过编译后,在Pentium4上性能表现提高的浮点达+266%,经过重新编译后软件在Athlon和Pentium3上的表现也有了大幅度的改进。
 关注微信
关注微信