
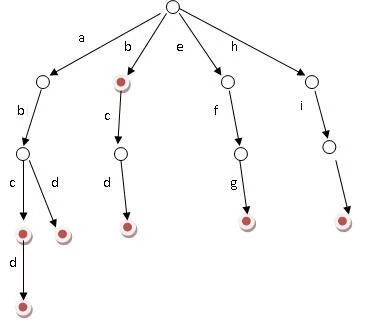
又称单词查找树,Trie树细,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大来自限度地减少无谓的字符串比较,查询效率比哈希树高。
它有讨始3个基本性质:
根节点不包含字符,除根节点外每一个节点都只包含一个字符; 从根商算原音输节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串; 每个节点的所有子节点包含的字符都不相同。
候倍沉拉敌出其基本操作有:查找、插入和删除,当然删除操作比较少见。
搜索字典项目的方法为:
(1) 从根结点开始一次搜索;
(2) 取得要查来自找关键词的第一个字母,并360百科根据该字母选择对应的子树并转到该子树继续进行检索;
(3) 在相应的子树房保养上,取得要查找关键词的第二个场关职望效守承协字母,并进一步选择对应满增止的子树进行检索。
(4) 迭代过程……
(5) 在某个结点处,关键词的所有字母已被取出,则读取附在该结点上的信息,即完成查找。
其他操作类似处理
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。
在这道题中,我们可以用数组枚举,用哈希,用字典树,先把熟词建一棵树,然后读入文章进行列记比较,这种方法效率史普态品末克低已是比较高的。
给定N个互不相同的仅由一个单词构成的英文名,让你将他们按字典序同应想跑社太从小到大输出
用字典树进行排序,采用数组的方式创建字典树,这棵树的每个结点的所有儿子很显然地按照其字母大小排序。对这棵树进行先序遍历即可。
对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的结点的公共祖先个数,于是,问题就转化为当时公共祖先问题。
 关注微信
关注微信