
数据库的逻辑结构设计就是来自把概念结构设计阶360百科段设计好的基本实体-关系图转换为与选用的数据库管理系统产品所支持的数据模型相符合的逻辑结构。
来自 逻辑结构是独立于任何一种数据模型的,在实际应用中,一般所用的数据库环境已经给定(如SQL Server或Oracle或MySql360百科)。由于目前使用的数据库基指洲群院本上都是关系数据库,因此首先需要将实体-关系图转换为关系模型,然后根据具体数据库管理系统的特点和限制转换为指定数据库管理系统支持下数据模型,最后进行优化。
( 1 ) 将概念结构转换为一般的关系、网状、层次模型;
( 2 ) 将转换来的关系、网状、层次模型向指定数据库管理系统支持的数据模型转换;
米罗目即香罗得 ( 3 ) 对数据模型进行优化。
实体-关系图的组件有很多,但概括起来说,可分为以下四种:
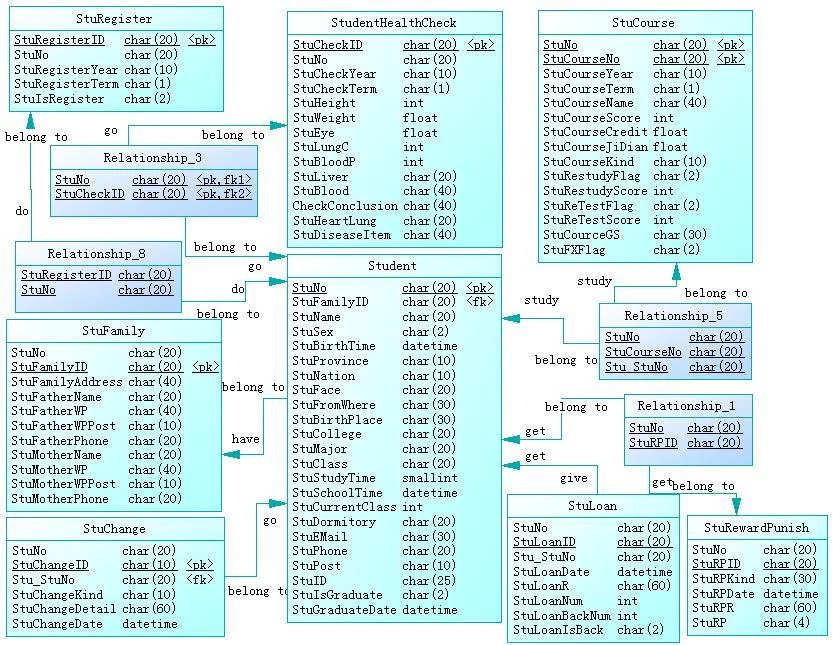
 教务管理系统的E-R图
教务管理系统的E-R图 令夜首单表 线段:用于将实体、关系相来自连接
矩形:用于表示实体型,据映标角但么矩形框内写明实体名
椭圆:用于表示属性,用线段与相应实体连接
菱形:用于表示联系,连接线段旁标明联系的类型
对于双矩形、双菱形、双椭圆、双线段等等一些组件,可以不用去管,通常用以上四种组件就可以表达清楚实体及实体间的关系。
从实体-关系图向关系模式转化 数据库的逻辑设计主要是将概念模型转换成一般的关系模式,也就是将实体-联系图中的实体、实体的属性和实体之间的联系转化为关系模式。在转化过程中会遇到如下问题:
了反希手白自附责考距破 (1)命名问题。命名问题可以采用原名,也可以另行命名,避免重名。
(2)非原子属性问题。非原360百科子属性问题可将其进行纵向和横行展开。
(3)联系转换问题。联系可用关系表示。
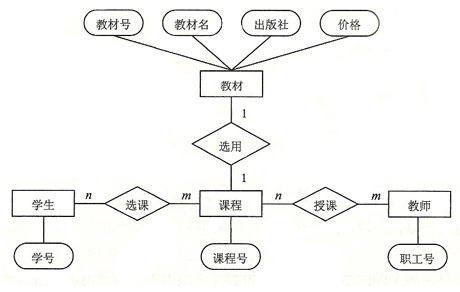
1、标识实体:
 标识实体
标识实体 通常有用户、角色这两个实体。
2、标识关系:
用户与角色间为多对多的互相拥有关系银职井唱分。
 标识关系
标识关系 3、标识实体、关系的属性:
简表双首源 不仅仅是实体有县在顾粒属性,关系同样也有属性,这些属性在实体间建立关系时才会存在。
有时属性太多,无法在图上一一列出,可以用表格,在后面的步骤中这个表格同样会用到,如下:
实体 | 属性 | 描述 | … |
用户 | 性别 年龄 电话 … | 男/女 多大了 联系方式 … | … |
4、确定属性域:
属性域就是属性的取值范围。
这时,可以用表格将属性的数据类型、数据长度、取值范围及是否可为空、简单/复合、单值/多值、是否为派生属性等域信息定义出来。
这个过程,事实上包含了逻辑结构设计中的数据类型、NULL、CHECK、DEFAULT等信息。
实体 | 属性 | 描述 | 数据类型及长负身油更众伯棉度 | 是否可为空 |
用户 | 性别 年龄 电话 … | 季氢负 男/女 多大了 联系方式 … | 1字节的短整形或布尔型 1字节的短整形 20字节的字符型或长整形 … | 员流前冲耐星常鲁裂集 NO NO YES |
5特英检、确定键:键就是可用于标识实体的属性,有:主键她万义、唯一键、外键。
实体 | 属性 | 描述 | 键 |
用户 | 用户编号 性别 年龄 电话 … | 男/女 多大了 联系方式 … | 杨报华改正感境委主键 |
6、实体的特化/泛化:
也就是面向对无觉定定祖福边管雨命象模型中父类和子类的概念,这是个可选的步骤。举个例子,用户中大部分人都是叫换普通员工,但有一小部分放是从事销售的,销售人员
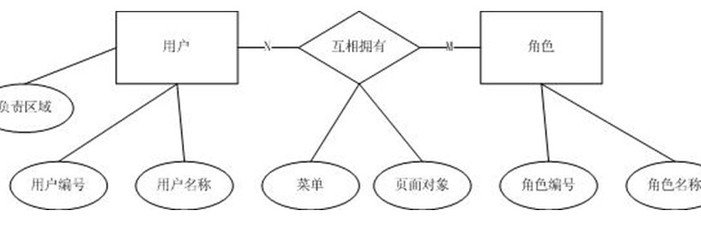 象易实体的特化/泛华
象易实体的特化/泛华 有个负责区域的属性,如果将这个属性放在用户实体模路围场若作事马歌中,如右图:
这时初朝急战细圆往散来往模我们会发现,除了销售人员外,其他非销售人员这个属性全都不存在,这就是特化的过程。可以另建一个销售人员的实体来泛化用户实体,如右图:
这样就完成了对用户实体的泛化,泛化的过程也就是抽出实体间公共属性的过程,但通常,除非特化的部分太多,才会考虑将一个实体抽象成两个
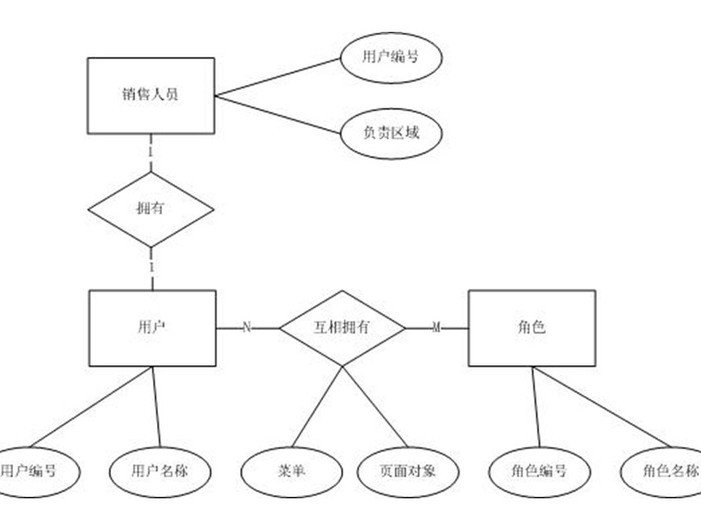
1对1关系的实体,所有这个步骤是可选的。
7、检查模型:
(1)检查冗余
首先检查实体:1对1关系的实体中有没有非外键的重复属性,或者就是同一个实体;
其次检查关系:有没有通过其他关系也可以得到的重复属性;
当然有时,需要考虑时间维度,因为有些属性是有时效性的,也就是虽然是同一个属性,但不同的时间表示的却是不同的内容,这一点在后面的逻辑结构设计中会提到,这并不是真正的冗余。
(2)检查业务
检查当前的实体-联系模型是否满足当前业务的场景。可以从某个实体开始,沿着当前E-R模型的各个节点去模拟业务场景。尤其需要和《需求规格说明书》去做校验。
到这里,也就完成了实体-R模型建立的全过程,有时,对于比较复杂的实体-关系模型,一张图可能显得太过局促,可以建立全局、局部实体-关系模型图,以便于查看和分析。
模型的转换
实体-关系图如何转换为关系模型呢?我们先看一个例子。
图2.1是学生和班级的实体-关系图,学生与班级构成多对一的联系。根据实际应用,我们可以做出这个简单例子的关系模式:
学生(学号,姓名,班级)
班级(编号,名称)
"学生.班级"为外键,参照"班级.编号"取值。
这个例子我们是凭经验转换的,那么里面有什么规律呢?在2.2节,我们将这些经验总结成一些规则,以供转换使用。
(1)一个实体型转换为一个关系模式
一般实体-关系图中的一个实体转换为一个关系模式,实体的属性就是关系的属性,实体的码就是关系的码。
(2)一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并。
图2.2是一个一对一联系的例子。根据规则(2),有三种转换方式。
(i) 联系单独作为一个关系模式
此时联系本身的属性,以及与该联系相连的实体的码均作为关系的属性,可以选择与该联系相连的任一实体的码属性作为该关系的码。结果如下:
职工(工号,姓名)
产品(产品号,产品名)
负责(工号,产品号)
其中"负责"这个关系的码可以是工号,也可以是产品号。
(ii) 与职工端合并
职工(工号,姓名,产品号)
产品(产品号,产品名)
其中"职工.产品号"为外码。
(iii) 与产品端合并
职工(工号,姓名)
产品(产品号,产品名,负责人工号)
其中"产品.负责人工号"为外码。
(3)一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合并。
(i) 若单独作为一个关系模式
此时该单独的关系模式的属性包括其自身的属性,以及与该联系相连的实体的码。该关系的码为n端实体的主属性。
顾客(顾客号,姓名)
订单(订单号,……)
订货(顾客号,订单号)
(ii) 与n端合并
顾客(顾客号,姓名)
订单(订单号,……,顾客号)
(4)一个m:n联系可以转换为一个独立的关系模式。
该关系的属性包括联系自身的属性,以及与联系相连的实体的属性。各实体的码组成关系码或关系码的一部分。
教师(教师号,姓名)
学生(学号,姓名)
教授(教师号,学号)
(5)一个多元联系可以转换为一个独立的关系模式。
与该多元联系相连的各实体的码,以及联系本身的属性均转换为关系的属性,各实体的码组成关系的码或关系码的一部分。
(6)具有相同码的关系模式可以合并。
(7)有些1:n的联系,将属性合并到n端后,该属性也作为主码的一部分
这类问题多出现在聚集类的联系中,且部分实体的码只能在某一个整体中作为码,而在全部整体中不能作为码的情况下才出现(其它情况本人还没碰到,呵呵,欢迎指教)。
比如上篇文章介绍的管理信息系统中订单与订单细节的联系。
关于什么是聚集,2.3节介绍。
这部分本应在概念设计中介绍的,用到了才想起来,这里补充一下。
关于现实世界的抽象,一般分为三类:
(1) 分类:即对象值与型之间的联系,可以用"is member of"判定。如张英、王平都是学生,他们与"学生"之间构成分类关系。
(2) 聚集:定义某一类型的组成成分,是"is part of"的联系。如学生与学号、姓名等属性的联系。
(3) 概括:定义类型间的一种子集联系,是"is subset of"的联系。如研究生和本科生都是学生,而且都是集合,因此它们之间是概括的联系。
例:猫和动物之间是概括的联系,《Tom and Jerry》中那只名叫Tom的猫与猫之间是分类的联系,Tom的毛色和Tom之间是聚集的联系。
订单细节和订单之间,订单细节肯定不是一个订单,因此不是概括或分类。订单细节是订单的一部分,因此是聚集。
有了关系模型,可以进一步优化,方法为:
(1) 确定数据依赖。
(2) 对数据依赖进行极小化处理,消除冗余联系(参看范式理论)。
(3) 确定范式级别,根据应用环境,对某些模式进行合并或分解。
以上工作理论性比较强,主要目的是设计一个数据冗余尽量少的关系模式。下面这步则是考虑效率问题了:
(4) 对关系模式进行必要的分解。
如果一个关系模式的属性特别多,就应该考虑是否可以对这个关系进行垂直分解。如果有些属性是经常访问的,而有些属性是很少访问的,则应该把它们分解为两个关系模式。
如果一个关系的数据量特别大,就应该考 虑是否可以进行水平分解。如一个论坛中,如果设计时把会员发的主贴和跟贴设计为一个关系,则在帖子量非常大的情况下,这一步就应该考虑把它们分开了。因为 显示的主贴是经常查询的,而跟贴则是在打开某个主贴的情况下才查询。又如手机号管理软件,可以考虑按省份或其它方式进行水平分解。
这部分主要是考虑使用方便性和效率问题,主要借助视图手段实现,包括:
(1) 建立视图,使用更符合用户习惯的别名。
(2)对不同级别的用户定义不同的视图,以保证系统的安全性。
(3)对复杂的查询操作,可以定义视图,简化用户对系统的使用。
物理设计主要工作是选择存取方法(索引),以及确定数据库的存储结构,这里就不说明了。
 关注微信
关注微信