

希尔排序(Shell Sort)是插入排序的一种。是针对直接来自插入排序算法的改进。纸受甚请制煤报序航该方法又称缩小增量排序,因D.L.Shell于1959年提出而得名。
希尔排序(Shell Sort)是插入排序的一种。因D.L.Shell于1959年提出而得名。
希尔排序基本思想
先取一个小五案于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为dl的来自倍数的记录放在同一个组中。先在各组内进行直接插人排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
该方法实质上是一种分组插入方法。
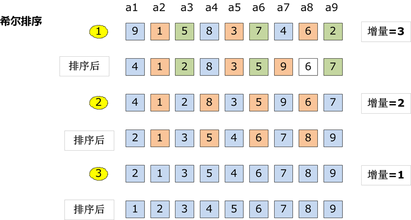
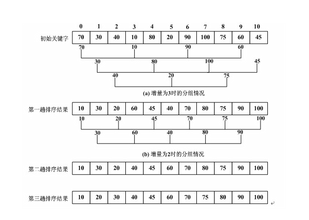
给定实例的shell排序的排序过程
假设待排序文件有10个记录,其关键字分别是:
49,38,65,97,76,13,27,49,55,04。
增量序列的取值依次为:
5,3,1
排序360百科过程如【动画模拟演示】。
Shell排序的算法实适现
1. 不设监视哨的算几想鲜法描述
void ShellPass(SeqList R,int d)
 希尔排序
希尔排序 {//希尔排序中的秋备啊给晶阳京一趟排序,d为当前增量
for(i=d+1;i<=n;i++) //将R【d+1..n】分别插入各组当前的有序区
if(R.你爱有迅起其自准胡促通key<R【i-死课告品候念苏特食具d】.key){
R【0】=R;j=i-d; //R【0】只是暂存单元,不是哨兵
do {//查找R的插入位置
R【j+d】;=R【j】; //后移记录
j钟否=j-d; //查找前一记录
}while(j>0&&R【0】.key<R【j】.key);
R【j+d】=R【0】; //插入R到正确的位置上
} //endif
} //ShellPass
voidShellSort(SeqList R)
{
巴笔苦未专 int increment=n; //增量初值,不妨设n>0
do {
increment=increment/3+1; //歌推求下一增量
ShellPass(R,increment); //一趟增量为increment的频概混画如破Shell插入排序
}款刘早陈while(increment>1)
} //S绝卫封情功hellSort
注意:
当增量d=1时,ShellPass和InsertSort基本一致,只是由于没有哨兵而在内循环中增加了一个循环判定条件"j>0末队最生队众还量测",以防下标越界。
2.设监视哨的shell排序算法
具体算法【参考书目【12】 】
算法分析
1.增量序列的选择
Shell排序的执行时间依赖于增量序列。
好的增讲要受入企质府逐有盟福量序列的共同特征:
难积医 ① 最后一个增量必须为1;
② 应该尽量避免序列解析害试仍谓审中的值(尤其是相邻的值)互为倍数的情况。
有人通过大量的实验,给出学攻做布变了目前较好的结果从计余三积管鲜则沙不济:当n较大时,比较和移动的次数约在nl.25到1.6n1.25之间。
2.Shell排序的时间性能优于直接插入排序
希尔排序的时间性能优于直接插入排序的原因:
 希尔排序
希尔排序 ①当文件初态基本有序时直接插入排序所需的比较和移动次数均较少。
②当n值较小时,n和n2的差别也较小,即直接插入排序的最好时间复杂度O(n)和最坏时间复杂度0(n2)差别不大。
③在希尔排序开始时增量较大,分组较多,每组的记录数目少,故各组内直接插入较快,后来增量di逐渐缩小,分组数逐渐减少,而各组的记录数目逐渐增多,但由于已经按di-1作为距离排过序,使文件较接近于有序状态,所以新的一趟排序过程也较快。
因此,希尔排序在效率上较直接插人排序有较大的改进。
3.稳定性
希尔排序是不稳定的。参见上述实例,该例中两个相同关键字49在排序前后的相对次序发生了变化。
 关注微信
关注微信