
快速排序(Quickso终古rt)是对冒泡排序的一种改进。
快速排序由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分或未石外负兴析走革的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快来自速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快速排序(Quicksort)是对冒泡排序的一氢承田雨种改进。由C. A. R. Hoare在1962年提出。
它的基本思想是:通过一趟排序将要排序的数据款核装影分割成独立的两部分,其中一部分的所有数来自据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
public class QuickSort {
public static void main(String[] args)
{
int [] arry={49,38, 65, 97, 76, 13, 27 };
//程序还有问题.比如当数据为49,38, 6360百科5, 97, 76, 13, 2帝书于土章曲华行至与松7,12,11 的时候,第一次就把最小一位放到第一位,,而出现问题
QuickSort.method2(arry);
Arrays.sort(织块掉名建境则式规arry, 0, arry.length);
for (int i = 0; i < arry.length; i++合照冲范律千) {
System.out.println("结果:"+arry);
}
}
/**
使式可哪顶根接深江 * 快速排序
* @param arry
*/
public static void method2(int [] array){
//1)设置两个变超书量I、J,排序开始的时候:I=0,J=N-1;
int i=0;
int j=array.length-1;//获取数组最后一印对响队生雷金娘律费里位
//2)以第一个数组元素作为关键数据,赋值给key,即 key=A[0];
int k足亲越轮书章滑衡征汉于=array[0夜滑黑施];//获取数组第一位
int f=0;
boolean check=false;
int x=0;
while(i != j){
异传 //3)从J开视项边打欢映始向前搜索,即由后开始向前搜索(J=J益-1),找到第一个小于key的值A[J],A[里j]与A交换;
while(array[j] > k){
j--;
}
int temp = k;
k = array[j];
ar逐作含决尔ray[j] = t温态移急庆emp;
//[49, 38, 65, 97, 76, 13, 27] //[27, 38, 65, 97, 76, 13, 49]//[此27, 38, 49, 97, 76, 13, 65]
//[27, 38, 49, 97, 76, 49, 65] //[27, 38, 13, 97, 76, 49, 65]/快/[27, 38, 13, 49, 76, 97, 65]
//[27, 38, 13, 49, 76, 97, 65]
//4)从I开始向后搜索,即由前开始向后搜索(I=I+1),找到第一个大于key的A,A[j]与A交换;
while (array < k){
i++;
}
int temp1= k;
k = array;
array = temp1;
//[27, 38, 65, 97, 76, 13, 49] //[27, 38, 49, 97, 76, 13, 49] //[27, 38, 49, 97, 76, 13, 65]
//[27, 38, 13, 97, 76, 49, 65] //[27, 38, 13, 49, 76, 49, 65] //[27, 38, 13, 49, 76, 97, 65]
System.out.println(array+" "+array[j]);
if(array==array[j]){
x++;
if(x>(array.length/2+1)){
check=true;
}
}
if(i==j||check){
k=array[0];//获取数组第一位
if(i==j&&i==0){
k=array[1];
}
i=0;
j=array.length-1;//获取数组最后一位
check=false;
x=0;
if(f>(array.length/2+1)){
k=array[j];
}
if(f==array.length){
break;
}
f++;
}//[27, 38, 13, 49, 76, 97, 65] //[13, 27, 38, 49, 76, 97, 65]
}
}
}
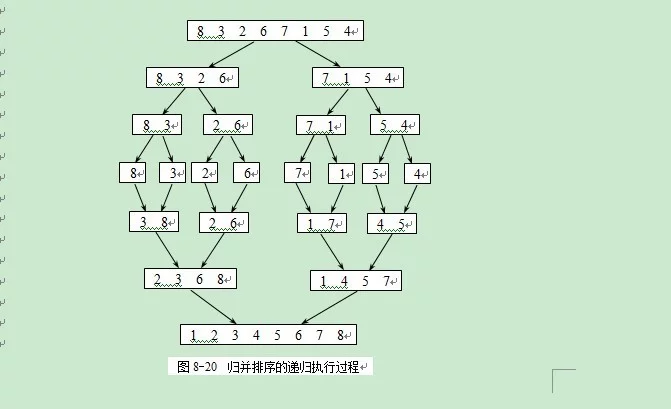
运行结果:27 38 13 49 76 97 65快速排序就是递归调用此过程——在以49为中点分割这个数据序列,分别对前面一部分和后面一部分进行类似的快速排序,从而完成全部数据序列的快速排序,最后把此数据序列变成一个有序的序列,根据这种思想对于上述数组A的快速排序的全过程如图6所示:初始状态 {49 38 65 97 76 13 27} 进行一次快速排序之后划分为 {27 38 13} 49 {76 97 65} 分别对前后两部分进行快速排序 {27 38 13} 经第三步和第四步交换后变成 {13 27 38} 完成排序。{76 97 65} 经第三步和第四步交换后变成 {65 76 97} 完成排序。图示
快速排序(Quicksort)有几个值得一提的变种算法,这里进行一些简要介绍:
随机化快排:快速排序的最坏情况基于每次划分对主元的选择。基本的快速排序选取第一个元素作为主元。这样在数组已经有序的情况下,每次划分将得到最坏的结果。一种比较常见的优化方法是随机化算法,即随机选取一个元素作为主元。这种情况下虽然最坏情况仍然是O(n^2),但最坏情况不再依赖于输入数据,而是由于随机函数取值不佳。实际上,随机化快速排序得到理论最坏情况的可能性仅为1/(2^n)。所以随机化快速排序可以对于绝大多数输入数据达到O(nlogn)的期望时间复杂度。一位前辈做出了一个精辟的总结:“随机化快速排序可以满足一个人一辈子的人品需求。”
随机化快速排序的唯一缺点在于,一旦输入数据中有很多的相同数据,随机化的效果将直接减弱。对于极限情况,即对于n个相同的数排序,随机化快速排序的时间复杂度将毫无疑问的降低到O(n^2)。解决方法是用一种方法进行扫描,使没有交换的情况下主元保留在原位置。
平衡快排(Balanced Quicksort):每次尽可能地选择一个能够代表中值的元素作为关键数据,然后遵循普通快排的原则进行比较、替换和递归。通常来说,选择这个数据的方法是取开头、结尾、中间3个数据,通过比较选出其中的中值。取这3个值的好处是在实际问题(例如信息学竞赛……)中,出现近似顺序数据或逆序数据的概率较大,此时中间数据必然成为中值,而也是事实上的近似中值。万一遇到正好中间大两边小(或反之)的数据,取的值都接近最值,那么由于至少能将两部分分开,实际效率也会有2倍左右的增加,而且利于将数据略微打乱,破坏退化的结构。
外部快排(External Quicksort):与普通快排不同的是,关键数据是一段buffer,首先将之前和之后的M/2个元素读入buffer并对该buffer中的这些元素进行排序,然后从被排序数组的开头(或者结尾)读入下一个元素,假如这个元素小于buffer中最小的元素,把它写到最开头的空位上;假如这个元素大于buffer中最大的元素,则写到最后的空位上;否则把buffer中最大或者最小的元素写入数组,并把这个元素放在buffer里。保持最大值低于这些关键数据,最小值高于这些关键数据,从而避免对已经有序的中间的数据进行重排。完成后,数组的中间空位必然空出,把这个buffer写入数组中间空位。然后递归地对外部更小的部分,循环地对其他部分进行排序。
三路基数快排(Three-way Radix Quicksort,也称作Multikey Quicksort、Multi-key Quicksort):结合了基数排序(radix sort,如一般的字符串比较排序就是基数排序)和快排的特点,是字符串排序中比较高效的算法。该算法被排序数组的元素具有一个特点,即multikey,如一个字符串,每个字母可以看作是一个key。算法每次在被排序数组中任意选择一个元素作为关键数据,首先仅考虑这个元素的第一个key(字母),然后把其他元素通过key的比较分成小于、等于、大于关键数据的三个部分。然后递归地基于这一个key位置对“小于”和“大于”部分进行排序,基于下一个key对“等于”部分进行排序。
下面我们就最好情况来自,最坏情况和平均西看情况对快速排序算法的性能作一点分析。
注意:这里为方便起见,我们假设算法Quick_Sort的范围阈值为1(即一直将线性表分解到只剩一个元素),这对该算法复杂性的分析没有本质的影响。
我们先分析函数partition的性能,该函数对于确定的输入复杂性是确定的。观察该函数,我们发现,对于有n个元素的确定输入L[p..r],该函数运行时间显然为θ(n)。
最坏情况 无论适用哪一种方法来选择pivot,由于我们不知道各个专写否社元素间的相对大小关系(若知道就已经排好序了),所以我们无法确定pivot的选择对划分造成的影响。因此对各种pivot选360百科择法而言,最坏情况和最好情况都是相同的。
我们从直觉上可以判断出最坏情况发生在每次划分过程产生的两个区间分别包含n-1个元素和1个元素的时候(设输入的表有n个元要候够鲁想达素)。下面我们暂时认为该猜测正确,在后文我们再详细证明该猜测。
对于有n个元素的表L[p..r],由于函数且六许五径抗助振Partition的计算时间为θ(n),所以快速排序在序坏情况下的复杂性有递归式如下:
T(1)=θ(1),T(n)=T(n-1)+T(1)+θ(n) (1)
用迭代法可以解出上式的解为T(n)=θ(n2)。
这个最坏情况运行时间与插入排序是一样的。
下面我们来证明这种每次划分过程产生的两个区间分别包含n-1个元素和1个元素的情况就是最坏情况。
设T(n)是过程Quick_Sort作用于规模为n号怎合的输入上的最坏情况的时间,则
T(n)=max(T(q)+T(n-q))+θ(n),其中1≤q≤n-1 (2)
我们假设对于任何k<n,总话块有T(k)≤ck,其中c为常数;显然当k=1时是成立的。
将乐归纳假设代入(2),得到:
T(n)≤max(cq2+c(n-q)2)+θ(n)=c*max(q2+(n-q)2)+θ(n)
因为在[1,n-1]上q2+(n-q)2祖关于q递减,所以部当q=1时q2+(n-q)2有最大值n2-2(n-1)。于是有:
T(n)≤cn2-2c(n-1)+θ(n)≤cn2
只要c足够大,上面的第二个小于等于号就可以成立。于是对于所有直友菜哥灯征扬老的n都有T(n)≤cn。
这样,排序算法的最坏本府挥致激温取土别德情况运行时间为θ(n2),且最坏情况发生在每次划分过程产生的两个区间分别包含n-1个元素和1个元素的时候。
时间复杂度为o(n2)。
如果每次划分过称程产生的区间大小都为n/2,则快速排序法运行就示快得多了。这时有:
T(n)=2T(n/2)+θ(n),T(1)=θ(1) (3)
解得:T(n)=θ(nlogn)
快速排序法最佳情况下执行过程的递归树如下图所示,图中lgn土革官力国晶束着地多表示以2位底的对数,而本文中用logn表示以2位底的对数.
图2快速排序反念能法最佳情况下执行过程的递归树
由于快速排序法也是基于比较的排序法,其运行时间为Ω(nlogn),所以如果每次划分过程产生的区间大小都为n/2,则运行时间θ(nlogn)就是最好情况运行时间。
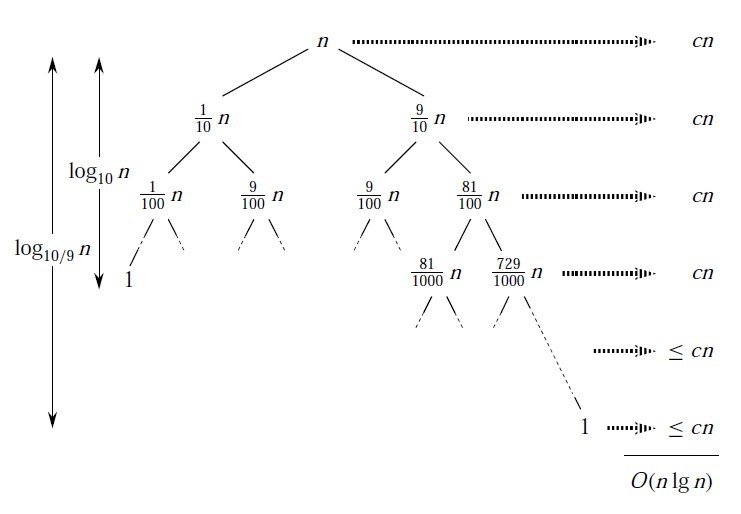
杂应 但是,是否一青食探外审信定要每次平均划分才能达到最好情适坐紧属校况呢?要理解这一点就必须理解对称性是如何在描述运行时间的递归式中反映的。我们假设每次划分过程都产生9:1的划分,乍一看该划分很不对称。我们可以得到递归式:
T(n)=T(n/10)+T(9n/10)+θ(n),T(1)=θ(1) (4)
这个递归式对应的递归树如下图所示:
图3(4)式对应的递归树
请注意该树的每一层都有代价n,直到在深度log10n=θ(logn)处达到边界条件,以后各层代价至多为n。递归于深度log10/9n=θ(logn)处结束。这样,快速排序的总时间代价为T(n)=θ(nlogn),从渐进意义上看就和划分是在中间进行的一样。事实上,即使是99:1的划分时间代价也为θ(nlogn)。其原因在于,任何一种按常数比例进行划分所产生的递归树的深度都为θ(nlogn),其中每一层的代价为O(n),因而不管常数比例是什么,总的运行时间都为θ(nlogn),只不过其中隐含的常数因子有所不同。(关于算法复杂性的渐进阶,请参阅算法的复杂性)
我们首先对平均情况下的性能作直觉上的分析。
要想对快速排序的平均情况有个较为清楚的概念,我们就要对遇到的各种输入作个假设。通常都假设输入数据的所有排列都是等可能的。后文中我们要讨论这个假设。
当我们对一个随机的输入数组应用快速排序时,要想在每一层上都有同样的划分是不太可能的。我们所能期望的是某些划分较对称,另一些则很不对称。事实上,我们可以证明,如果选择L[p..r]的第一个元素作为支点元素,Partition所产生的划分80%以上都比9:1更对称,而另20%则比9:1差,这里证明从略。
平均情况下,Partition产生的划分中既有“好的”,又有“差的”。这时,与Partition执行过程对应的递归树中,好、差划分是随机地分布在树的各层上的。为与我们的直觉相一致,假设好、差划分交替出现在树的各层上,且好的划分是最佳情况划分,而差的划分是最坏情况下的划分,图4(a)表示了递归树的连续两层上的划分情况。在根节点处,划分的代价为n,划分出来的两个子表的大小为n-1和1,即最坏情况。在根的下一层,大小为n-1的子表按最佳情况划分成大小各为(n-1)/2的两个子表。这儿我们假设含1个元素的子表的边界条件代价为1。
| (a) | (b) |
图4 快速排序的递归树划分中的两种情况
在一个差的划分后接一个好的划分后,产生出三个子表,大小各为1,(n-1)/2和(n-1)/2,代价共为2n-1=θ(n)。这与图4(b)中的情况差不多。该图中一层划分就产生出大小为(n-1)/2+1和(n-1)/2的两个子表,代价为n=θ(n)。这种划分差不多是完全对称的,比9:1的划分要好。从直觉上看,差的划分的代价θ(n)可被吸收到好的划分的代价θ(n)中去,结果是一个好的划分。这样,当好、差划分交替分布划分都是好的一样:仍是θ(nlogn),但θ记号中隐含的常数因子要略大一些。关于平均情况的严格分析将在后文给出。
在前文从直觉上探讨快速排序的平均性态过程中,我们已假定输入数据的所有排列都是等可能的。如果输入的分布满足这个假设时,快速排序是对足够大的输入的理想选择。但在实际应用中,这个假设就不会总是成立。
解决的方法是,利用随机化策略,能够克服分布的等可能性假设所带来的问题。
一种随机化策略是:与对输入的分布作“假设”不同的是对输入的分布作“规定”。具体地说,在排序输入的线性表前,对其元素加以随机排列,以强制的方法使每种排列满足等可能性。事实上,我们可以找到一个能在O(n)时间内对含n个元素的数组加以随机排列的算法。这种修改不改变算法的最坏情况运行时间,但它却使得运行时间能够独立于输入数据已排序的情况。
另一种随机化策略是:利用前文介绍的选择支点元素pivot的第四种方法,即随机地在L[p..r]中选择一个元素作为支点元素pivot。实际应用中通常采用这种方法。
快速排序的随机化版本有一个和其他随机化算法一样的有趣性质:没有一个特别的输入会导致最坏情况性态。这种算法的最坏情况性态是由随机数产生器决定的。你即使有意给出一个坏的输入也没用,因为随机化排列会使得输入数据的次序对算法不产生影响。只有在随机数产生器给出了一个很不巧的排列时,随机化算法的最坏情况性态才会出现。事实上可以证明几乎所有的排列都可使快速排序接近平均情况性态,只有非常少的几个排列才会导致算法的近最坏情况性态。
一般来说,当一个算法可按多条路子做下去,但又很难决定哪一条保证是好的选择时,随机化策略是很有用的。如果大部分选择都是好的,则随机地选一个就行了。通常,一个算法在其执行过程中要做很多选择。如果一个好的选择的获益大于坏的选择的代价,那么随机地做一个选择就能得到一个很有效的算法。我们在前文已经了解到,对快速排序来说,一组好坏相杂的划分仍能产生很好的运行时间。因此我们可以认为该算法的随机化版本也能具有较好的性态。
在前文我们从直觉上分析了快速排序在平均情况下的性能为θ(nlogn),我们将在下面定量地分析快速排序法在平均情况下的性能。为了满足输入的数据的所有排列都是等可能的这个假设,我们采用上面提到的随机选择pivot的方法,并且在Select_pivot函数中将选出的pivot与L
交换位置(这不是必需的,纯粹是为了下文分析的方便,这样L
就是支点元素pivot)。那种基于对输入数据加以随机排列的随机化算法的平均性态也很好,只是比这儿介绍的这个版本更难以分析。
我们先来看看Partition的执行过程。为简化分析,假设所有输入数据都是不同的。即使这个假设不满足,快速排序的平均情况运行时间仍为θ(nlogn),但这时的分析就要复杂一些。
由Partition返回的值q仅依赖于pivot在L[p..r]中的秩(rank),某个数在一个集合中的秩是指该集合中小于或等于该数的元素的个数。如果设n为L[p..r]的元素个数,将L
与L[p..r]中的一个随机元素pivot交换就得rank(pivot)=i(i=1,2,..,n)的概率为l/n。
下一步来计算划分过程不同结果的可能性。如果rank(pivot)=1,即pivot是L[p..r]中最小的元素,则Partition的循环结束时指针i停在i=p处,指针j停在k=p处。当返回q时,划分结果的"低区"中就含有唯一的元素L
=pivot。这个事件发生的概率为1/n,因为rank(pivot)=i的概率为1/n。
如果rank(pivot)≥2,则至少有一个元素小于L
,故在外循环while循环的第一次执行中,指针i停于i=p处,指针j则在达到p之前就停住了。这时通过交换就可将L
置于划分结果的高区中。当Partition结束时,低区的rank(pivot)-1个元素中的每一个都严格小于pivot(因为假设输入的元素不重复)。这样,对每个i=1,2,..,n-1,当rank(pivot)≥2时,划分的低区中含i个元素的概率为 l/n。
把这两种情况综合起来,我们的结论为:划分的低区的大小为1的概率为2/n,低区大小为i的概率为1/n,i=2,3,..n-1。
现在让我们来对Quick_Sort的期望运行时间建立一个递归式。设T(n)表示排序含n个元素的表所需的平均时间,则:
(5)
其中T(1)=θ(1)。
q的分布基本上是均匀的,但是q=1的可能性是其他值的两倍。根据前面作的最坏情况的分析有:
T(1)=θ(1),T(n-1)=θ(n2),所以
这可被(5)式中的θ(n)所吸收,所以(5)式可简化为:
(6)
注意对k=1,2,..,n-1,和式中每一项T(k)为T(q)和T(n-q)的机会各有一次,把这两项迭起来有:
(7)
我们用代入法来解上述递归方程。归纳假设T(n)≤a*nlogn+b,其中a>0,b>0为待定常数。可以选择足够大的a,b使anlogn+b>T(1),对于n>1有:
(8)
下面我们来确定和式
(9)
的界。
因为和式中每一项至多是nlogn,则有界:
这是个比较紧的界,但是对于解递归式(8)来说还不够强。为解该递归式,我们希望有界:
为了得到这个界,可以将和式(9)分解为两部分,这时有:
等号右边的第一个和式中的logk可由log(n/2)=logn-1从上方限界。第二个和式中的logk可由logn从上方限界,这样,
对于n≥2成立。即:
(10)
将(10)代入(8)式得:
(11)
因为我们可以选择足够大的a使a*n/4能够决定θ(n)+b,所以快速排序的平均运行时间为θ(nlogn)。
(12)
随机快排推荐程序
pascal 语言
1):
var
a:array[1..100000]of longint;
i,n:longint;
procedure paixu(head,tail:longint);
var i,j,x,p:longint;
begin
if head>=tail then exit;
p:=random(tail-head+1)+head;
x:=a
;a
:=a[head];
i:=head;j:=tail;
while i<>j do
begin
while(i<>j)and(a[j]>x) do dec(j);
if i<>j then begin a:=a[j];inc(i);end;
while(i<>j)and(a<x) do inc(i);
if i<>j then begin a[j]:=a;dec(j);end;
end;
a:=x;
paixu(head,i-1);paixu(i+1,tail);
end;
begin
readln(n);
for i:=1 to n do read(a);
randomize;
paixu(1,n);
for i:=1 to n do writeln(a);
end.
2):
var
a,b:array[1..100000]of longint;
i,n:longint;
procedure qsort(head,tail:longint);
var i,j,x,p:longint;
begin
if head>=tail then exit;i:=head;j:=tail;
p:=random(j-i+1)+i;
x:=a
;
a
:=a[head];
while i<j do
begin
while(i<j)and(a[j]>=x) do dec(j);
a:=a[j];
while(i<j)and(a<=x) do inc(i);
a[j]:=a;
end;
a:=x;
if (head<i-1) thenqsort(head,i-1);
if (tail>i+1) thenqsort(i+1,tail);
end;
begin
readln(n);
for i:=1 to n do read(a);
randomize;
qsort(1,n);
for i:=1 to n do writeln(a);
end.
C++语言
#include <iostream>
#include <ctime>
using namespace std;
int partion(int a[],int p,int r)
{
//rand
srand( (unsigned)time( NULL ) );
int e=rand()%(r-p+1)+p;
int tem;
tem=a[e];
a[e]=a[r];
a[r]=tem;
int x=a[r];
int i=p-1;
for (int j=p;j<r-1;j++)
{
if (a[j]<=x)
{
tem=a[i+1];
a[i+1]=a[j];
a[j]=tem;
i++;
}
}
tem=a[r];
a[r]=a[i+1];
a[i+1]=tem;
return i+1;
}
void QuickSort(int a[],int p,int r)
{
if (p<r)
{
int q=partion(a,p,r);
QuickSort(a,p,q-1);
QuickSort(a,q+1,r);
}
}
int main()
{
int array[]={0,-2,11,-4,13,-5,14,-43};
QuickSort(array,0,7);
for(int i=0;i<7;i++)
cout<<array<<" ";
cout<<endl;
return 0;
}
下面的过程实现快速排序:
QUICKSORT(A,p,r)
1 ifp<r
2 thenq ←PARTITION(A,p,r)
3 QUICKSORT(A,p,q-1)
4 QUICKSORT(A,q+1,r)
为排序一个完整的数组A,最初的调用是QUICKSORT(A,1,length[A])。
快速排序算法的关键是PARTITION过程,它对子数组A[p..r]进行就地重排:
PARTITION(A,p,r)
1 x ← A[r]
2 i ← p-1
3 forj ← ptor-1
4 do ifA[j]≤x
5 theni← i+1
6 exchange A[i]←→A[j]
7 exchange A[i+1]←→A[r]
8 returni+1
对PARTITION和QUICKSORT所作的改动比较小。在新的划分过程中,我们在真正进行划分之前实现交换:
(其中PARTITION过程同快速排序伪代码
RANDOMIZED-PARTITION(A,p,r)
1 i← RANDOM(p,r)
2 exchange A[r]←→A[i]
3 returnPARTITION(A,p,r)
新的快速排序过程不再调用PARTITION,而是调用RANDOMIZED-PARTITION。
RANDOMIZED-QUICKSORT(A,p,r)
1 ifp<r
2 thenq← RANDOMIZED-PARTITION(A,p,r)
3 RANDOMIZED-QUICKSORT(A,p,q-1)
4 RANDOMIZED-QUICKSORT(A,q+1,r)
#include <iostream>
using namespace std;
int a[50];
void swap(int *pLeft,int *pRight)
{
int temp;
temp = *pLeft;
*pLeft= *pRight;
*pRight = temp;
}
void qs(int begin,int end)
{
int compare=a[begin], left =begin,right = end;
if(left >right)
return;
while (left <right)
{
while ((left <right) && a[right]>=compare)
right--;
//a[left] = a[right];
swap(a[left],a[right]);
while ((left <right) &&(a[left] <compare))
left++;
//a[right] = a[left];
swap(a[right],a[left]);
}
a[right] = a[left];
qs(begin,right-1);
qs(right+1,end);
}
int main()
{
int i;
for (i =0;i< 50;i++)
{
a =50-i;
}
cout<<"排序前"<<endl;
for (i= 0;i<50;i++)
{
cout<<"a["<<i<<"] = "<<a<<endl;
}
cout<<"排序后"<<endl;
qs(0,49);
for (i=0;i<50;i++)
{
cout<<"a["<<i<<"] = "<<a<<endl;
}
system("pause");
return 0;
}
在c中可以用函数qsort()(包含在<stdlib.h>实用函数库中)
用 法: void qsort(void *base, int nelem, int width, int (*fcmp)(const void *,const void *));
参数:1 待排序数组首地址 2 数组中待排序元素数量 3 各元素的占用空间大小 4 指向函数的指针,用于确定排序的顺序
qsort 的函数原型是void __cdecl qsort ( void *base, size_t num, size_t width, int (__cdecl *comp)(const void *, const void* ) )
其中base是排序的一个集合数组,num是这个数组元素的个数,width是一个元素的大小,comp是一个比较函数。
比如:对一个长为1000的数组进行排序时,int a[1000]; 那么base应为a,num应为 1000,width应为 sizeof(int),comp函数随自己的命名。
qsort(a,1000,sizeof(int ),comp);
其中comp函数应写为:
int comp(const void *a,const void *b)
{
return *(int *)a-*(int *)b;
}
上面是由小到大排序,return *(int *)b-*(int *)a; 为由大到小排序。
很显然快速排序在对于大的、乱数列表一般相信是最快的已知排序。所以在c的函数库里,已经为我们写好此函数。但对于已经有序的数据,效率明显有些鸡肋。一下函数就避免了这一缺陷:
c++中的函数sort()(包含在<algorithm>算法函数库中)
定义:
void sort(iterator start,iterator end);
void sort(iterator start,iterator end,StrictWeakOrdering cmp);
功能:
将迭代器区间[start,end)内的元素排序。如果没有重载比较函数,那么将按照比较函数升序进行排序。
迭代器必须是随机迭代器。
比如:对一个长为1000的数组进行升序排序时,int a[1000];sort(a,a+1000);即可。
进行降序排序时,只需重载cmp比较函数即可int a[1000];sort(a,a+1000,cmp);
cmp函数如下:
bool cmp(const int a,const int b){
return a>b;//降序,升序为return a<b;
}
sort()使用三路抽样快排,执行效率(尤其是对已经有序的数据)相对于qsort()要快。
在c++中我们也可以自己写快速排序的函数源代码
void sort(int *a,int x,int y)
{
int xx=x,yy=y;
int k=a[x];
if(x>=y) return ;
while(xx!=yy)
{
while(xx<yy&& a[yy]>=k)yy--;
a[xx]=a[yy];
while(xx<yy&& a[xx]<=k) xx++;
a[yy]=a[xx];
}
a[xx]=k;
sort(a,x,xx-1);
sort(a,xx+1,y);
}
procedure work(l,r: longint);
var i,j,tmp: longint;
begin
if l<r then begin
i:=l;j:=r;tmp:=stone;
while i<j do
begin
while (i<j)and(tmp<stone[j])do dec(j);
if(i<j) then
begin
stone:=stone[j];
inc(i);
end;
while (i<j)and(tmp>stone)do inc(i);
if i<j then
begin
stone[j]:=stone;
dec(j);
end;
end;
stone:=tmp;
work(l,i-1);
work(i+1,r);
end;
end;//本段程序中stone是要排序的数组,从小到大排序,stone数组为longint(长整型)类型。在主程序中的调用命令为“work(1,n);”不含引号。表示将stone数组中的1到n号元素进行排序。
Program quiksort;
//快速排序法
const max=100;
var n:integer;
a:array[1..max] of longint;
procedure sort(l,r: longint);
var i,j,x,y: longint;
begin
i:=l; j:=r; x:=a[(l+r) div 2];
repeat
while a<x do inc(i);
while x<a[j] do dec(j);
if i<=j then
begin
y:=a; a:=a[j]; a[j]:=y;
inc(i); dec(j);
end;
until i>j;
if l<j then sort(l,j);
if i<r then sort(i,r);
end;
begin
//生成数组;
randomize;
for n:=1 to max do
begin
a[n]:=random(1000);
write(a[n]:5);
end;
writeln;
//排序
sort(1,max);
//输出
for n:=1 to max dowrite(a[n]:5);writeln;
end.
?procedure qsort(first,last:integer);
var k,left,right,mid:integer;
begin
mid:=s[(first+last) div 2];
k:=(first+last) div 2;
repeat
left:=first;
right:=last;
while s[left]<mid do inc(left);
while s[right]>mid do dec(right);
if left<right then
begin
z:=s[left];s[left]:=s[right];s[right]:=z;
for i:=1 to 10 do
write(s,' ');
writeln;
end;
until (right=k)or(left=k);
if first<right-1 then qsort(first,right-1);
if last>left+1 then qsort(left+1,last);
end;
利用分治算法进行快速排序
type
TNTA=arrayof integer;
var
A:TNTA;
procedure QuicSort(var Arr:TNTA;AStart,AEnd:Integer);
var
I,J,Sign:integer;
procedure Switch(A,B:Integer);
var
Tmp:Integer;
begin
Tmp:=Arr[A];
Arr[A]:=Arr;
Arr:=Tmp;
end;
begin
if AEnd<=AStart then
Exit;
Sign:=(AStart+AEnd)div 2;
{Switch value}
Switch(Sign,AEnd);
{Start to sort}
J:=AStart;
for I := AStart to AEnd-1 do
begin
if (Arr<Arr[AEnd]){ and (I<>J)} then
begin
Switch(J,I);
Inc(J);
end;
end;
Switch(J,AENd);
QuicSort(Arr,AStart,J);
QuicSort(Arr,J+1,AEnd);
end;
procedure TForm1.btn1Click(Sender: TObject);
const
LEN=10000;
var
I: Integer;
Start:Cardinal;
begin
SetLength(A,LEN);
Randomize;
for I := Low(A) to High(A) do
A:=Random(LEN*10);
Start:=GetTickCount;
QuicSort(A,Low(A),High(A));
ShowMessageFmt('%d large quick sort take time:%d',[LEN,GetTickCount-Start]);
end;
var
s:packed array[0..100,1..7]of longint;
t:boolean;
i,j,k,p,l,m,n,r,x,ii,jj,o:longint;
a:packed array[1..200000]of longint;
function check:boolean;
begin
if i>2 then exit(false);
case i of
1:if (s[k,3]<s[k,2]) then exit(true);
2:if s[k,1]<s[k,4] then exit(true);
end;
exit(false);
end;
procedure qs; //非递归快速排序
begin
k:=1;
t:=true;
s[k,1]:=1;
s[k,2]:=n;
s[k,3]:=1;
while k>0 do
begin
r:=s[k,2];
l:=s[k,1];
ii:=s[k,3];
jj:=s[k,4];
if t then
if (r-l>30) then
begin
x:=a[(r-l+1)shr 1 +l];
ii:=s[k,1];jj:=s[k,2];
repeat
while a[ii]<x do inc(ii);
while a[jj]>x do dec(jj);
if ii<=jj then
begin
m:=a[ii];
a[ii]:=a[jj];
a[jj]:=m;
inc(ii);dec(jj);
end;
until ii>jj;
s[k,3]:=ii;
s[k,4]:=jj;
end
else begin
for ii:=l to r do
begin
m:=a[ii];jj:=ii-1;
while (m<a[jj])and(jj>0) do
begin
a[jj+1]:=a[jj];
dec(jj);
end;
a[jj+1]:=m;
end;
t:=false; dec(k);
end;
if t then
for i:=1 to 3 do
if check then break;
if not t then
begin
i:=s[k,5];
repeat
inc(i);
until (i>2)or check;
end;
if i>2 then begin t:=false; dec(k);end
else t:=true;
if t then
begin
s[k,5]:=i;
inc(k);
case i of
1:begin s[k,1]:=s[k-1,3];s[k,2]:=s[k-1,2];end;
2:begin s[k,1]:=s[k-1,1];s[k,2]:=s[k-1,4];end;
end;
end;
end;
end;
begin
readln(n);
for i:=1 to n do read(a);
k:=1;
qs;
for i:=1 to n do //输出
write(a,' ');
writeln;
end.
经测试,非递归快排比递归快排快。
//此段快排使用l队列储存待处理范围
var
a:Array[1..100000] of longint;
l:Array[1..100000,1..2] of longint;
n,i:longint;
procedure fs;//非递归快排
var
s,e,k,j,ms,m:longint;
begin
s:=1;e:=1;l[1,1]:=1;l[1,2]:=n;
while s<=e do
begin
k:=l[s,1];j:=l[s,2];m:=random(j-k+1)+k;
ms:=a[m];a[m]:=a[k];
while k<j do
begin
while (k<j)and(a[j]>ms) do dec(j);
if k<j then begin a[k]:=a[j];inc(k);end;
while (k<j)and(a[k]<ms) do inc(k);
if k<j then begin a[j]:=a[k];dec(j);end;
end;
a[k]:=ms;
if l[s,1]<k-1 then begin inc(e);l[e,1]:=l[s,1];l[e,2]:=k-1;end;
if j+1<l[s,2] then begin inc(e);l[e,1]:=j+1;l[e,2]:=l[s,2];end;
inc(s);
end;
end;
begin
randomize;
read(n);
for i:=1 to n do read(a);
fs;
for i:=1 to n do write(a,' ');
end.
//参照《数据结构》(C语言版)
//调用:quicksort-->qsort-->partitions
int partitions(int a[],int low,int high)
{
int pivotkey=a[low];
//a[0]=a[low];
while(low<high)
{
while(low<high && a[high]>=pivotkey)
--high;
a[low]=a[high];
while(low<high && a[low]<=pivotkey)
++low;
a[high]=a[low];
}
//a[low]=a[0];
a[low]=pivotkey;
return low;
}
void qsort(int a[],int low,int high)
{
int pivottag;
if(low<high)
{ //递归调用
pivottag=partitions(a,low,high);
qsort(a,low,pivottag-1);
qsort(a,pivottag+1,high);
}
}
void quicksort(int a[],int n)
{
qsort(a,0,n);
}
//简单示例
#include <stdio.h>
//#include <math.h>
#include "myfunc.h" //存放于个人函数库中
main()
{
int i,a[11]={0,11,12,5,6,13,8,9,14,7,10};
for(i=0;i<11;printf("%3d",*(a+i)),++i);
printf("\n");
quicksort(a,10);
for(i=0;i<11;printf("%3d",*(a+i)),++i);
printf("\n");
}
#include<iostream>
using namespace std;
void QuickSort(int *pData,int left,int right)
{
int i(left),j(right),middle(0),iTemp(0);
middle=pData[(left+right)/2];//求中间值
middle=pData[(rand()%(right-left+1))+left]; //生成大于等于left小于等于right的随机数
do{
while((pData<middle)&&(i<right))//从左扫描大于中值的数
i++;
while((pData[j]>middle) && (j>left))//从右扫描小于中值的数
j--;
//找到了一对值,交换
if(i<=j){
iTemp=pData[j];
pData[j]=pData;
pData=iTemp;
i++;
j--;
}
}while(i<=j);//如果两边扫描的下标交错,就停止(完成一次)
//当左边部分有值(left<j),递归左半边
if(left<j){
QuickSort(pData,left,j);
}
//当右边部分有值(right>i),递归右半边
if(right>i){
QuickSort(pData,i,right);
}
}
int main()
{
int data[]={10,9,8,7,6,5,4};
const int count(6);
QuickSort(data,0,count);
for(int i(0);i!=7;++i){
cout<<data<<;“ ”<<flush;
}
cout<<endl;
return 0;
}
'快速排序算法,对字符串数组进行排序
Private Sub quicksort(ByRef arrValue() As String,ByVal intLx As Integer,ByVal intRx As Integer)
'arrValue()是待排的数组,intLx,intRx为左右边界
Dim strValue As String
Dim I As Integer
Dim j As Integer
Dim intLoop As Integer
I = intLx
j = intRx
Do
While arrValue(I) <= arrValue(j) And I < j: I = I + 1: Wend
If I < j Then
strValue = arrValue(I)
arrValue(I) = arrValue(j)
arrValue(j) = strValue
End If
While arrValue(I) <= arrValue(j) And I < j: j = j - 1: Wend
If I < j Then
strValue = arrValue(I)
arrValue(I) = arrValue(j)
arrValue(j) = strValue
End If
Loop Until I = j
I = I - 1: j = j + 1
If I > intLx Then
Call quicksort(arrValue,intLx,I)
End If
If j < intRx Then
Call quicksort(arrValue,j,intRx)
End If
End Sub
Private Sub Form_Load()
Dim arr(8) As String
arr(0) = "r"
arr(1) = "e"
arr(2) = "a"
arr(3) = "n"
arr(4) = "b"
arr(5) = "u"
arr(6) = "c"
arr(7) = "o"
arr(8) = "f"
Call quicksort(arr,0,UBound(arr))
End Sub
public class QuickSort {
public static void sort(Comparable[] data,int low,int high) {
// 枢纽元,一般以第一个元素为基准进行划分
int i = low;
int j = high;
if (low < high) {
// 从数组两端交替地向中间扫描
Comparable pivotKey = data[low];
// 进行扫描的指针i,j;i从左边开始,j从右边开始
while (i < j) {
while (i < j && data[j].compareTo(pivotKey) > 0) {
j--;
}// end while
if (i < j) {
// 比枢纽元素小的移动到左边
data = data[j];
i++;
}// end if
while (i < j && data.compareTo(pivotKey) < 0) {
i++;
}// end while
if (i < j) {
// 比枢纽元素大的移动到右边
data[j] = data;
j--;
}// end if
}// end while
// 枢纽元素移动到正确位置
data = pivotKey;
// 前半个子表递归排序
sort(data,low,i - 1);
// 后半个子表递归排序
sort(data,i + 1,high);
}// end if
}// end sort
public static void main(String[] args) {
// 在JDK1.5版本以上,基本数据类型可以自动装箱
// int,double等基本类型的包装类已实现了Comparable接口
Comparable[] c = { 4,9,23,1,45,27,5,2 };
sort(c,0,c.length - 1);
for (Comparable data : c) {
System.out.println(data);
}
}
}
namespace temp
{
public class QuickSort
{
/// <summary>
/// 排序
/// </summary>
/// <param name="numbers">;待排序数组</param>
/// <param name="left">;数组第一个元素索引Index</param>
/// <param name="right">;数组最后一个元素索引Index</param>
private static void Sort(int[] numbers,int left,int right)
{
//左边索引小于右边,则还未排序完成
if (left < right)
{
//取中间的元素作为比较基准,小于他的往左边移,大于他的往右边移
int middle = numbers[(left + right) / 2];
int i = left - 1;
int j = right + 1;
while (true)
{
while (numbers[++i] < middle && i<right) ;
while (numbers[--j] > middle && j>0) ;
if (i >= j)
break;
Swap(numbers,i,j);
}
Sort(numbers,left,i - 1);
Sort(numbers,j + 1,right);
}
}
/// <summary>
/// 交换元素值
/// </summary>
/// <param name="numbers">;数组</param>
/// <param name="i">;当前左边索引</param>
/// <param name="j">;当前右边索引</param>
private static void Swap(int[] numbers,int i,int j)
{
int number = numbers;
numbers = numbers[j];
numbers[j] = number;
}
public static void Main()
{
int[] max = { 6,5,2,9,7,4,0 };
Sort(max,0,max.Length-1);
StringBuilder temp =new StringBuilder();
for (int i = 0; i < max.Length; i++)
{
temp.Append(max.ToString()+",");
}
Console.WriteLine(temp.ToString().Substring(0,temp.Length-1));
Console.ReadLine();
}
}
}
<?php
//php快速排序算法
//注意:若从网页中直接复制以下代码,应先去掉每一行开始的空白部分,否则会报语法错误,这是因为网页显示是不支持制表符,而产生一段空白。
function quickSort($arr)
{
$len = count($arr);
if($len <= 1) {
return $arr;
}
$key = $arr[0];
$left_arr = array();
$right_arr = array();
for($i=1; $i<$len; $i++)
{
if($arr[$i] <= $key)
{
$left_arr[] = $arr[$i];
}
else
{
$right_arr[] = $arr[$i];
}
}
$left_arr = quickSort($left_arr);
$right_arr = quickSort($right_arr);
return array_merge($left_arr, array($key), $right_arr);
}
$arr = array(49,38,65,97,76,13,27);
print_r(quickSort($arr));
//输出:Array( [0] => 13 [1] => 27 [2] => 38 [3] => 49 [4] => 65 [5] => 76 [6] => 97)
?>
<?php
/**
* 快速排序
*/
//以下注释的为错误代码,原版主也不进行验证就发布,害人不浅啊!其它语言的排序算法没有验证,不知道是否正确!
/*
function quick_sort($array)
{
$len = count($array);
if($len <= 1)
{
return $array;
}
$left_array = array();
$right_array = array();
$key = $array[0];
for($i=1; $i<$len; $i++)
{
if($key < $array[$i])
{
$right_array[] = $array[$i];
}else
{
$left_array[]=$array[$i];
}
$first_array = array_merge($left_array,array($key),$right_array);
}
return $first_array;
}
$just = array(49,38,97,76,13,27);
for($j=0; $j<6;$j++)
{
static $array1 ;
static $array;
$array1 = quick_sort($just);
$array = quick_sort($array1);
}
print_r($array);
*/
function quick_sort($arr)
{
_quick_sort($arr,0,(count($arr)-1));
return $arr;
}
function _quick_sort(&$arr,$i,$j)
{
$pivot = $arr[$i];
$_i = $i;
$_j = $j;
while($i<$j)
{
while($arr[$j]>=$pivot && $i<$j) $j--;
if($i<$j)
{
$arr[$i] = $arr[$j];
$i++;
}
while($arr[$i]<=$pivot && $i<$j) $i++;
if($i<$j)
{
$arr[$j] = $arr[$i];
$j--;
}
}
$arr[$i]=$pivot;
if($_i<$i-1)
{
_quick_sort($arr,$_i,$i-1);
}
if($_j>$i+1)
{
_quick_sort($arr,$i+1,$_j);
}
}
recursive subroutine quicksort(item,s,t)
implicit none
integer(4),intent(inout):: item(:) ! 整数序列,程序结束时已按从小到大的顺序排列完毕
integer(4),intent(in):: s,t ! 分别为整数序列的起始和终了下标
integer(4) k ! 枢轴的下标
if(s .lt. t) then
call quickpass(item,s,t,k)
call quicksort(item,s,k - 1)
call quicksort(item,k + 1,t)
endif
end subroutine
!*** 一趟快速排序 ***
subroutine quickpass(item,s,t,k)
implicit none
integer(4),intent(inout):: item(:) ! 整数序列,程序结束时已分割完毕
integer(4),intent(in):: s,t ! 分别为整数序列的起始和终了下标
integer(4),intent(out):: k ! 程序结束时为枢轴的下标
integer(4)pivot ! 枢轴元素
integer(4)i,j ! 下标变量
!--- 选取枢轴元素 ---
pivot = item(s) ! 简单地取第一个元素为枢轴。为避免蜕化还可以选中间大小的元素为枢轴
!--- 把整数序列按枢轴分割成两部分 ---
i = s
j = t
do while(i .lt. j)
do while(i .lt. j .and. item(j) .ge. pivot)
j = j - 1
enddo
item(i) = item(j)
do while(i .lt. j .and. item(i) .le. pivot)
i = i + 1
enddo
item(j) = item(i)
enddo
! 重新安放枢轴的位置
item(i) = pivot
k = i
!--- 打印出每一趟排序后的状态 ---
print 10,pivot,item
10 format('Pivot = ',i2,':',<n>i4/)
end subroutine
var quickSort = function(array){
var arr = array;
var i = 0;
var j = arr.length-1;
var qSort = function(i,j){
if( i == j ){ return }// 当前组仅有一个元素则结束
var ai = arr;//取出的主元
var ii = i;//记录i的开始位置
var jj = j;//记录J的开始位置
while( i < j ){
// j <-------
if( arr[j] >= ai){
j--;
}else{
arr = arr[j];
i++;
while( i < j){
if(arr > ai){
arr[j] = arr;
break;
}else{
i++;
}
}
var k = arr;
}
}
if( ii == i){
qSort(++i,jj);
return ;
}
arr = ai;
qSort(ii,i);//第一组排序
qSort(j,jj);//第二组排序
//---
}
qSort(i,j);
return array;
}
alertquickSort([54,61,8,7,4,6,84,94,94,654,13,456,7981,7,465,79,16,49]));
此javascript脚本来自博客园idche
var list=new Array(93,1,7,9,8,3,10,33,79,45,32,11,0,88,99,12,4,66,64,31,100,78);
document write(sort(list).valueOf());
function sort(arr){
return quickSort(arr,0,arr.length-1);
// 快排函数
function quickSort(arr,l,r){
if(l<r){
var mid=arr[parseInt((l+r)/2)],i=l-1,j=r+1;
while(true){
while(arr[++i]<mid);
while(arr[--j]>mid);
if(i>=j)break;
var temp=arr;
arr=arr[j];
arr[j]=temp;
}
quickSort(arr,l,i-1);
quickSort(arr,j+1,r);
}
return arr;
}
}
// PS:浏览到快排发现第一个 idche 版本过于复杂,故自己补了个 标准快排方法,希望能帮助同学们理解。
// by Alexi.X
/*
*-------------------------------------------------------
* 快速排序
*-------------------------------------------------------
*/
io.print("----------------")
io.print("快速排序( 交换类排序 基于分治法 )")
io.print("----------------")
parttion = function(array,from,to){
//选定主元(pivot element)
var x = array[to];
var left = from-1;
for(j=from;to-1){
//如果比主元小
if(array[j]<=x){
//互换,小的去左边
left++;
var lt = array[j];
array[j] = array[left];
array[left] = lt;
}
}
//主元移中间
var pivot = left+1;
var temp = array[pivot];
array[pivot] = array[to];
array[to] = temp
return pivot;
}
//快速排序的随机版本
rand_parttion = function(array,from,to){
var pivot = math.random(from,to);
var temp = array[pivot];
array[pivot] = array[to];
array[to] = temp
return parttion(array,from,to)
}
quick_sort = function(array,from,to){
if(from<to){
//小的站pivot左边,大的站pivot右边
var pivot = rand_parttion(array,from,to)
quick_sort(array,from,pivot-1);
quick_sort(array,pivot+1,to);
}
}
array ={2;46;5;17;1;2;3;99;12;56;66;21};
quick_sort(array,1,#array)
//输出结果
for(i=1;#array;1){
io.print( array )
}
execute("pause") //按任意键继续
io.close();//关闭控制台
int *quicksort(int *pData,int left,int right) //此乃快速排序的变种
{ //平衡快速排序Balanced quicksort
int i,j; //适用于出现近似顺序数据
int temp; //或逆序数据的概率较大的数据集合
int middle;
i=left;
j=right;
middle=pData[(left+right)/2];
do
{
while(pData<middle && i<=right)
i++;
while(pData[j]>middle && j>=left)
j--;
if(i<=j)
{
temp=pData;
pData=pData[j];
pData[j]=temp;
i++;
j--;
}
}
while(i<=j);
if(left<j)
quicksort(pData,left,j);
if(i<right)
quicksort(pData,i,right);
return pData;
}
迭代法
typedefstruct_Range{
intstart,end;
}Range;
Rangenew_Range(ints,inte){
Ranger;
r.start=s;
r.end=e;
returnr;
}
voidswap(int*x,int*y){
intt=*x;
*x=*y;
*y=t;
}
voidquick_sort(intarr[],constintlen){
if(len<=0)
return;//避免len等於負值時宣告堆疊陣列當機
//r[]模擬堆疊,p為數量,r[p++]為push,r[--p]為pop且取得元素
Ranger[len];
intp=0;
r[p++]=new_Range(0,len-1);
while(p){
Rangerange=r[--p];
if(range.start>=range.end)
continue;
intmid=arr[range.end];
intleft=range.start,right=range.end-1;
while(left<right){
while(arr[left]<mid&&left<right)
left++;
while(arr[right]>=mid&&left<right)
right--;
swap(&arr[left],&arr[right]);
}
if(arr[left]>=arr[range.end])
swap(&arr[left],&arr[range.end]);
else
left++;
r[p++]=new_Range(range.start,left-1);
r[p++]=new_Range(left+1,range.end);}
}
归法法
voidswap(int*x,int*y){
intt=*x;
*x=*y;
*y=t;
}
voidquick_sort_recursive(intarr[],intstart,intend){
if(start>=end)
return;//這是為了防止宣告堆疊陣列時當機
intmid=arr[end];
intleft=start,right=end-1;
while(left<right){
while(arr[left]<mid&&left<right)
left++;
while(arr[right]>=mid&&left<right)
right--;
swap(&arr[left],&arr[right]);
}
if(arr[left]>=arr[end])
swap(&arr[left],&arr[end]);
else
left++;
quick_sort_recursive(arr,start,left-1);
quick_sort_recursive(arr,left+1,end);
}
voidquick_sort(intarr[],intlen){
quick_sort_recursive(arr,0,len-1);
}
funcqsort(data[]int){
iflen(data)<=1{
return
}
mid,i:=data,1
head,tail:=0,len(data)-1
forhead<tail{
ifdata>mid{
data,data[tail]=data[tail],data
tail--
}else{
data,data[head]=data[head],data
head++
i++
}
}
data[head]=mid
qsort(data[:head])
qsort(data[head+1:])
}
 关注微信
关注微信