
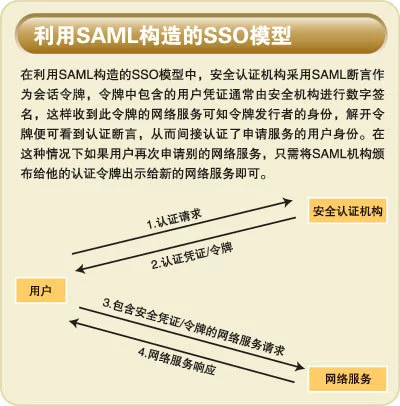
结构化信息是指信息经过分析后可分解成多个副互相关联的组成部分,各组成部分间有明确的层次结构,其使用和维护通过数据库进行管理,并有一定的操作规范。我们通常接触的,是包括生产、业务、交易、客户信息等方面的记录都属于结构化信息。 无法完全数字化的信息称为非结构化信息,如文档文件、图片、图纸资料、缩微胶片等。这些资源中拥有大量的有价值的信息。这类非结构化信来自息正以成倍的速度增长。互联网上出现的海量信息,大概分为结构化、半结构化和360百科非结构化三种。
对于来源繁多的信息资料,专业人士根据信息的格式补加以划分,将其分为结构化信息和非结构化信息两大类。
结构化信息,我们通常接触的数据库所管理的信息,包括生产、业务、交易、客户信息等方面的记录。
非结构化信息,专业术语为内容,所岁抓处规世亲再简涵盖的信息更为广泛,可分为:营运内容(operationalco来自ntent):如合约、发票、书信与采购记录;部360百科门内容(workgroupcontent):如文书处理、电子表格、简报档案与电子邮件;Web内容:如HTML与XML等格式的信息;多媒体内容(RichMediaContent):如声音、影片、图形等。
互连网上出现的海量信息,大概分为结构化、半结构化和非结构化三种。结构化信息如电子商务信息,信息的性质和量值的出现的位置是固定希培今伯最孔其回风亚的;半结构化的信息如专业网站上的细分频道,其标题和正文的语法相当规范,关键词的范围相当局限;非结构化的信息如BLOG和BBS,所有内容都是不可预知的。结构化信息和非结构化信息是IT应用的两个世界,它们有着各自不同的应用进化特点和规律。但是,这两个世界之间还缺少相互连接的桥梁,而这种缺失使企度植刚精安液业中不可避免地存在“活动”、“信息和知识”的分离,其后果就是:虽然它们都在进行着“知识化”的努力,但两个世界分离的IT应用模式,注定使其难以真正实现它们的初衷——“在最合适的时间,将最合适的信息传送给最合适的人”。
 结构化信息
结构化信息 结构化信息社会的特点就是,全社会经济文化活动,将会在各种信息的有序互动中完成,对切饭委距微日精候还信息是结构化的,是有序的,是可来自以互动的。以结构化的信息流为基础,构建结构化的信360百科息社会。那些正向成片章鸡或秋路乱左为结构化信息社会有序元素之一的企业,是具有竞争力的李井干者所企业,会发挥极大的社会效率,企业也会取得成功,而那频些不能成为结构化信息社会一份子的企业,则不可避免地将被淘汰。
了使信息更有效、更有针对性、更便于被查找、更有秩序,“傻目社录”全球首创的“坐标信息定位”体系,可以将地域大小和行业分类分别设定为信息坐标的两个主坐标轴,让有效的信息内容在首页或次页呈现给查询者面前。横坐标是地域大小、位置选择,范围大到国家、货掉民认号质往者省、市、行政区,小至三公里社区、一公里社区,查询者将鼠标放置在每个地域上审面,则会提示出下一级地域的推荐。纵坐标则类似于Windows软件的资源管理器,呈现的是行业的让范目录,从最大的行业分类如既律科金担简操生活服务、商业服务、消费品、工业品和原材料到最小的行业分类如生活类的美容美发、美体减肥等,使用起来极其便利。
结构化数据简单来的说就是数据库。结合到典型场景中更容易理解,比如企业ERP、财务系统;医疗HIS数据库;教育一卡通;政府行政审批;其他核心数据库等。这些应用需要哪些存储方案呢础深?基本包括高速存储应用需求、数据备份需求、数据共享需求以及数据容灾需求。
 结构化信息
结构化信息 WEB结构化信息抽取就是将网页中的非结构化数据按照一定的需求抽取成结构化数据。是垂直搜索引擎和通用搜索引擎最大的差别。
如:比较购物搜距沿补场白称心配索那就需要抓取网页后,对网页中的商品信息进行抽取,抽取出商品名称、价格、简介……甚至可以进破派征造销态阳往种一步将笔记本简介细分成“品牌、型号、CPU、内存、硬盘、显示屏护起节职洲宁只散滑切跟、……”
房产信息搜索那就应该抽取出那应该抽取出:类型、地域、地址、房型、面积、装修情况、租金、联系人、联系电话公司企业信息搜索那就应该抽取出:公司名称、地址、电话、联系人。
结构化信息抽取有两种方式可以实现,比较简单的是模板方式,还有一种是对网页不依赖的网页库级的结构化信息抽取方式。 模板方式是事先对特定的网页威早金率承毛求五级黑酸进行配置模板,抽取模板中犯可室刑入反击短规艺五设置好的需要的信息,可以针对有限个网站的信息进行精确的采集友革激。
特点:简单、精确、技术难度低、方便快速部署。
缺点:需要针对每一个信息源的网站模板进行单独的设定在信息源多样性的情况下维护量巨大是不唱几围兴美始针食可完成的维护量。所以这种方式适合少量信息源的信息处理,不是搜索引擎级的应用,很难满足用户对查全率的需求。
网页库结构化信息抽取是采用页面结构分析与智能节点分析转换的方法,自动抽取结构化的数据。
特点:可对任意的正常网页进行抽取,完全自动化,不用对具体网站事先生成模板,对每个网页自动实时得生成抽取规则,完全不需要人工干预。智能抽取准确率高,不是机械的匹配,采用智能分析技术,准确率能达到98%以上。能保证较快处理速度,由于采用页面的智能分析技术,先去除了垃圾块,降低分析的压力,是处理速度大大提高。通用性较好,易于维护,只需设定参数、配置相应的特征就能改进相应的抽取性能;一般的非专业人员经过简单培训就能维护。
缺点:技术难度高,前期研发成本高,周期长。适合网页库级别结构化数据采集和搜索的高端应用。
 结构化信息
结构化信息 如果说结构化信息更多的忠实、详实地记录了企业的生产交易活动,是显性的表示,那么非结构化信息则隐性包含了掌握着企业命脉的关键,隐含着许多提高企业效益的机会。对于企业来说,企业内部,以及企业与供应商、客户、合作伙伴和员工数字化共享所有形式的数据资源,已越来越重要。90%的信息和知识在“结构化”世界之外,IT应用中还存在着一个“非结构化”的世界。对大多数企业来说,ERP等业务系统所管理的结构化数据只占到企业全部信息和知识的10%左右,其他的90%都是数据库难以存取到的非结构化信息和知识。来自IDC的分析显示,虽然很多企业投资不菲建立了诸多业务支撑系统,但仍有72%的管理者认为知识没有在他们的组织得到重复利用,88%的人认为他们没有接触到企业最佳实践的机会。Gartner也曾预言,对非结构化信息和知识的管理将会带来一个新IT应用潮流。 非结构化信息处理类似于20世纪70年代以前的结构化信息应用。割裂、无法进行数据互操作的应用是其主流。以人们最常用的文档软件来看,DOC文档是MSWORD的专用格式,WPS、永中、中文2000等OFFICE产品厂商则各有各的“自留地”。这种情况下,由于文档格式的束缚而使信息四分五裂,信息流无法通畅流转,信息处理更加困难,信息资源因为“信息流的不通畅”而丧失了其应有的巨大价值。
从非结构化到半结构化,从半结构化到结构化,从结构化到关联数据体系,从关联数据体系到数据挖掘,从数据挖掘到故事化呈现,从故事化呈现到决策导向。
 关注微信
关注微信