
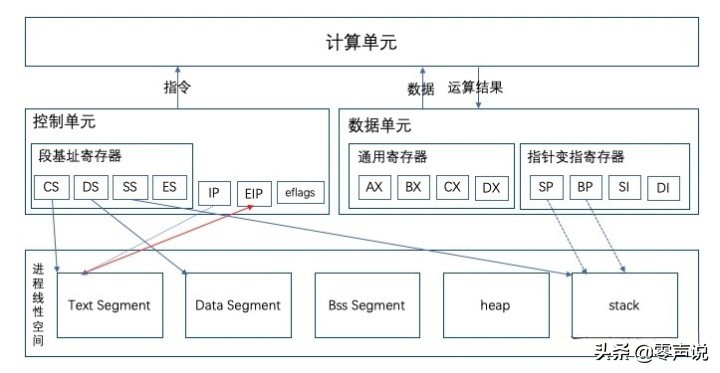
CPU包括3个部分:运算单元,数据单元,控制单元
总线上主要有两类数据,一类是地址数据(要拿内存中哪个位置的数据),这类总线是地址总线;另一类是真正的数据,这类总线是数据总线
32位CPU包含的寄存器
PS:视频相关学习文档,后台私信(Linux)

主板上的ROM固化了一段初始化程序BIOS(Basic Input and Output System,基本输入输出系统)
Grub2是一个linux启动管理器 ,Grub2把boot.img共512字节安装到启动盘的第一个扇区,这个扇区称为MBR(Master Boot Record,主引导记录扇区)
0号进程 -> 1号内核进程 -> 1号用户进程(init进程) -> getty进程 -> shell进程 -> 命令行执行进程。
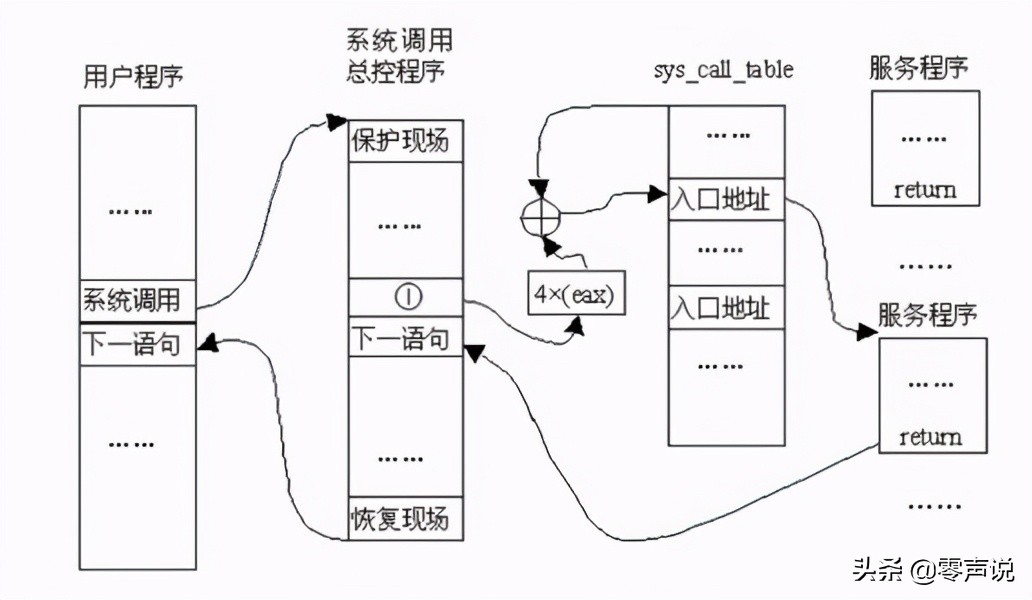
int指令将CS中的CPL改为0,从而进入内核,这是用户程序发起调用内核代码的唯一方式
系统调用核心
Linux的PCB是task_struct结构

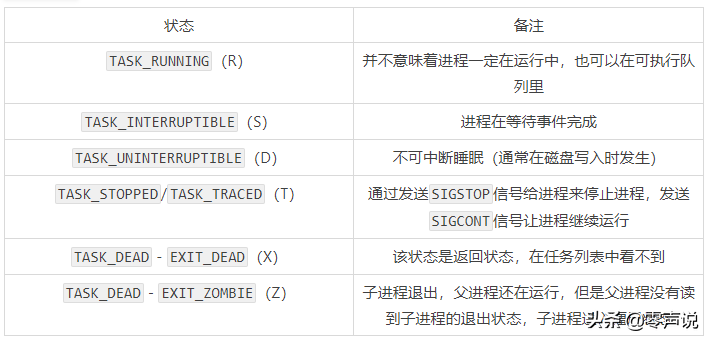
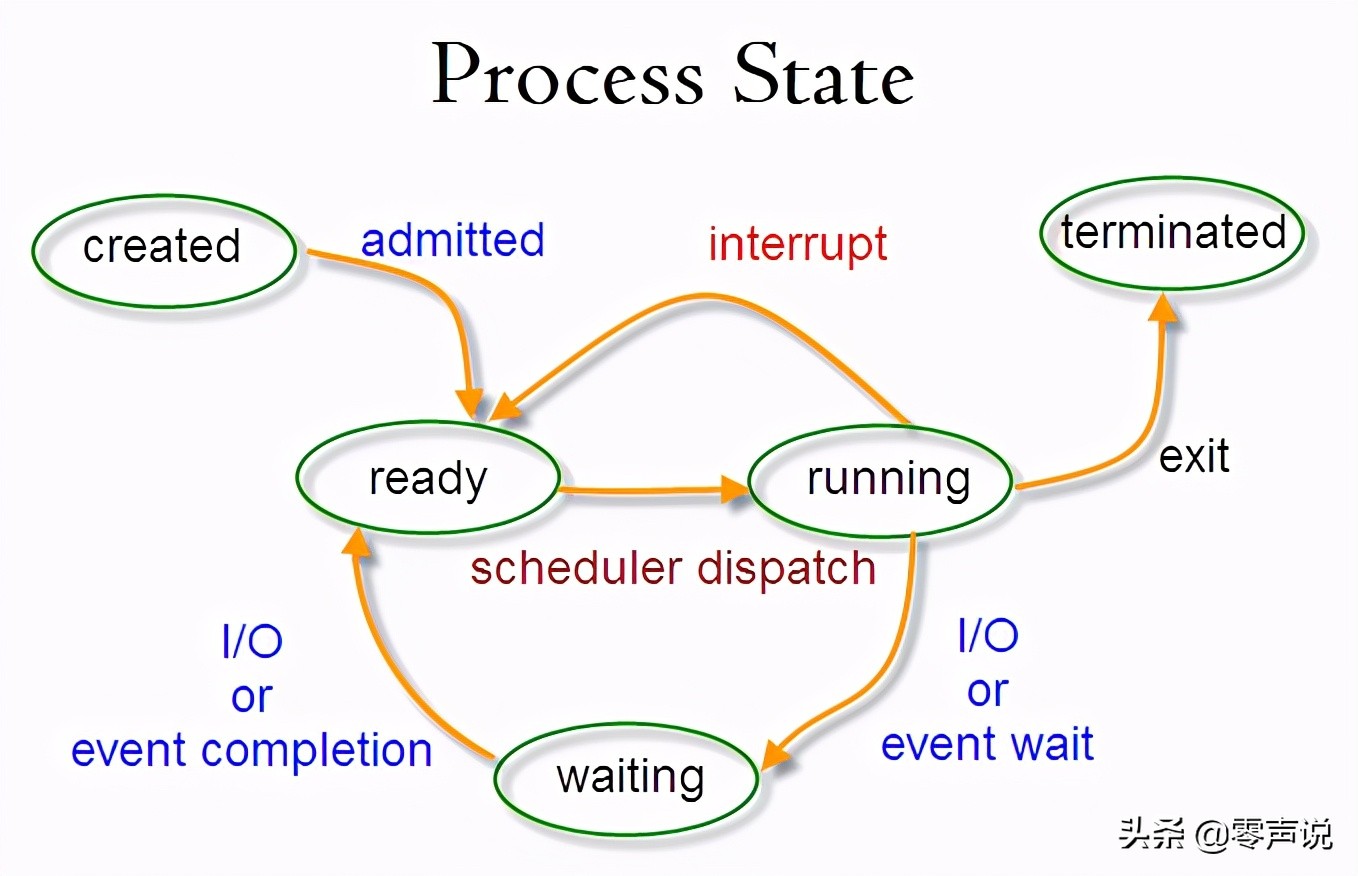
很多操作系统教科书将正在CPU上执行的进程定义为RUNNING状态,而将可执行但是尚未被调度执行的进程定义为READY状态,这两种状态在linux下统一为TASK_RUNNING状态
在Linux系统中,一个线程组中的所有线程使用和该线程组的领头线程相同的pid,并被存放在tgid成员中。只有线程组的领头线程的pid成员才会被设置为与tgid相同的值
注意,getpid()系统调用返回的是当前进程的tgid值而不是pid值
内核在创建进程的时候,在创建task_struct的同时,会为进程创建相应的堆栈。每一个进程都有两个栈,一个用户栈,存在于用户空间;一个内核栈,存在于内核空间
当进程在用户空间运行时,CPU堆栈指针寄存器里面的内容都是用户栈地址,使用用户栈;当进程在内核空间运行时,CPU堆栈指针寄存器里面的内容是内核栈地址,使用内核栈
当进程因为中断或者系统调用陷入到内核态时,进程所使用的堆栈也要从用户栈转到内核栈。
进程陷入到内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;当进程从内核态恢复到用户态时,在内核态之后的最后将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈向用户栈的转换
在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为当进程在用户态运行时使用用户栈,当进程陷入到内核态时,内核保存进程在内核态运行的相关信息,但是一旦进程返回到用户态后,内核栈中保存的信息全部无效,因此每次进程从用户态陷入内核的时候得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了
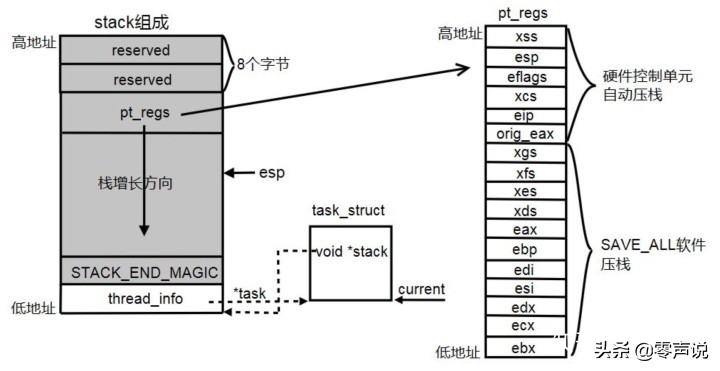
task_struct->stack指向进程的内核栈,大小为8K
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};整个内核栈用union表示,thread_info和stack共用一段存储空间,thread_info占用低地址。在pt_regs和STACK_END_MAGIC之间,就是内核代码的运行栈。当内核栈增长超过STACK_END_MAGIC就会报内核栈溢出
thread_info:存储内核态运行的一些信息,如指向task_struct的task指针,使得陷入内核态之后仍然能够找到当前进程的task_struct,还包括是否允许内核中断的preemt_count开关等等
pt_regs:存储用户态的硬件上下文,用户态进入内核态后,由于使用的栈、内存地址空间、代码段等都不同,所以用户态的eip、esp、ebp等需要保存现场,内核态恢复到用户态时再将栈中的信息恢复到硬件。由于进程调度一定会在内核态的schedule函数,用户态的所有硬件信息都保存在pt_regs中了。SAVE_ALL指令就是将用户态的cpu寄存器值保存如内核栈,RESTORE_ALL就是将pt_regs中的值恢复到寄存器中,这两个指令在介绍中断的时候还会提到
TSS(task state segment):这是intel为上层做进程切换提供的硬件支持,还有一个TR(task register)寄存器专门指向这个内存区域。当TR指针值变更时,intel会将当前所有寄存器值存放到当前进程的tss中,然后再讲切换进程的目标tss值加载后寄存器中
这里很多人都会有疑问,不是有内核栈的pt_regs存储硬件上下文了吗,为什么还要有tss?前文说过,进程切换都是在内核态,而pt_regs是保存的用户态的硬件上下文,tss用于保存内核态的硬件上下文
但是linux并没有买账使用tss,因为linux实现进程切换时并不需要所有寄存器都切换一次,如果使用tr去切换tss就必须切换全部寄存器,性能开销会很高。这也是intel设计的败笔,没有把这个功能做的更加的开放导致linux没有用。linux使用的是软切换,主要使用thread_struct,tss仅使用esp0这个值,用于进程在用户态 -> 内核态时,硬件会自动将该值填充到esp寄存器。在初始化时仅为每1个cpu仅绑定一个tss,然后tr指针一直指向这个tss,永不切换。
thread_struct:一个和硬件体系强相关的结构体,用来存储内核态切换时的硬件上下文
内存空间切换
将curr_task设置为新进程的task
将cpu寄存器保存到旧进程的thread_struct结构
将新进程的thread_struct的寄存器的值写入cpu
切换栈顶指针
PS:文章福利后台私信(Linux)获取


task_struct {
unsigned int policy // 调度策略
int prio, static_prio, normal_prio; // 优先级
unsigned int rt_priority;
const struct sched_class* sched_class; // 调度器类
}// 调度策略定义
#define SCHED_NORMAL 0 // 普通进程
#define SCHED_FIFO 1 // 相同优先级先来先服务
#define SCHED_RR 2 // 相同优先级轮流调度
#define SCHED_BATCH 3 // 后台进程
#define SCHED_IDLE 5 // 空闲进程
#define SCHED_DEADLINE 6 // 相同优先级电梯算法(deadline距离当前时间点最近)// 调度器类定义
stop_sched_class // 优先级最高的任务会使用这种策略,中断所有其他线程,且不会被其他任务打断
dl_sched_class // 对应deadline调度策略
rt_sched_class // 对应RR算法或者FIFO算法的调度策略,具体调度策略由进程的task_struct->policy指定
fair_sched_class // 普通进程的调度策略
idle_sched_class // 空闲进程的调度策略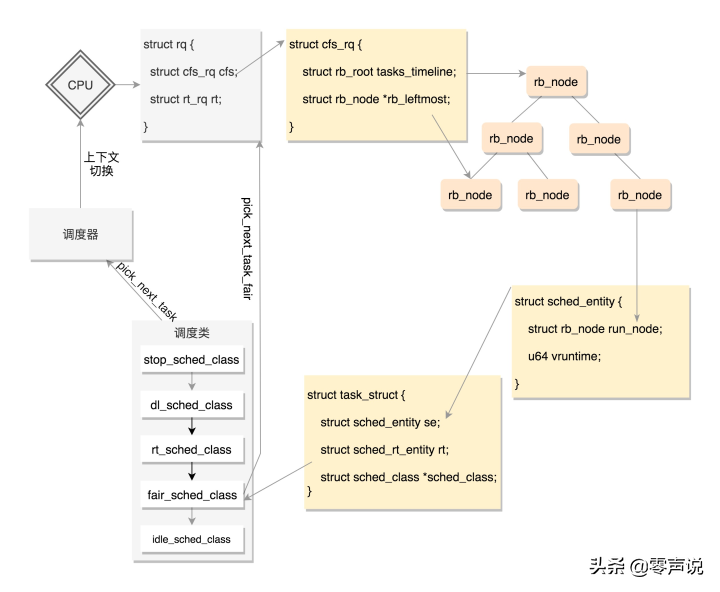
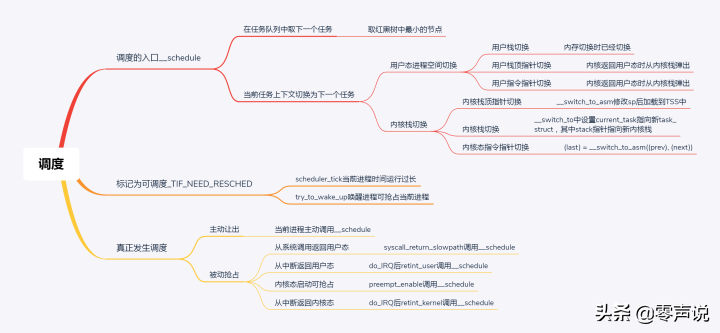
主动调度
抢占式调度(**先标记为应该被抢占,等到调用__schedule函数时才调度**)
用户态的抢占时机
内核态的抢占时机
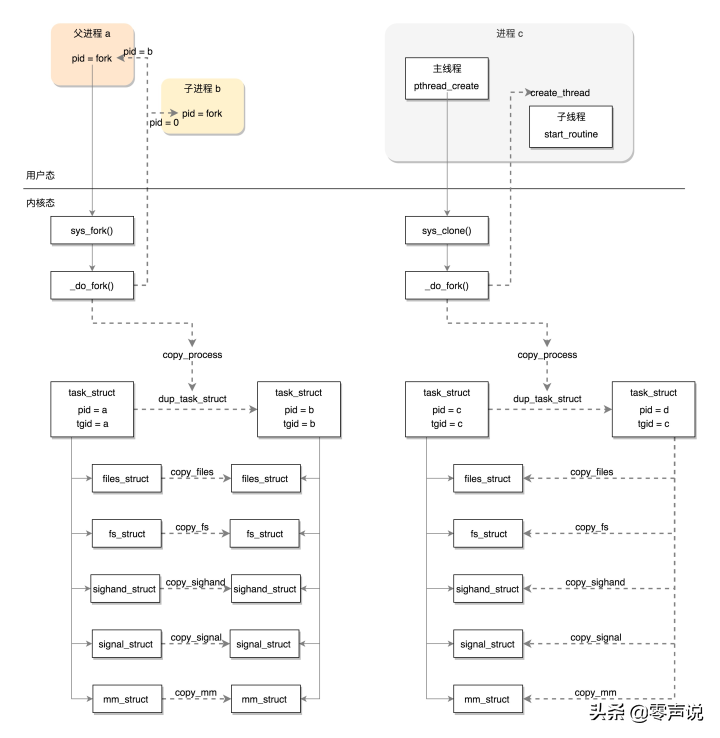
fork系统调用最终调用_do_fork函数
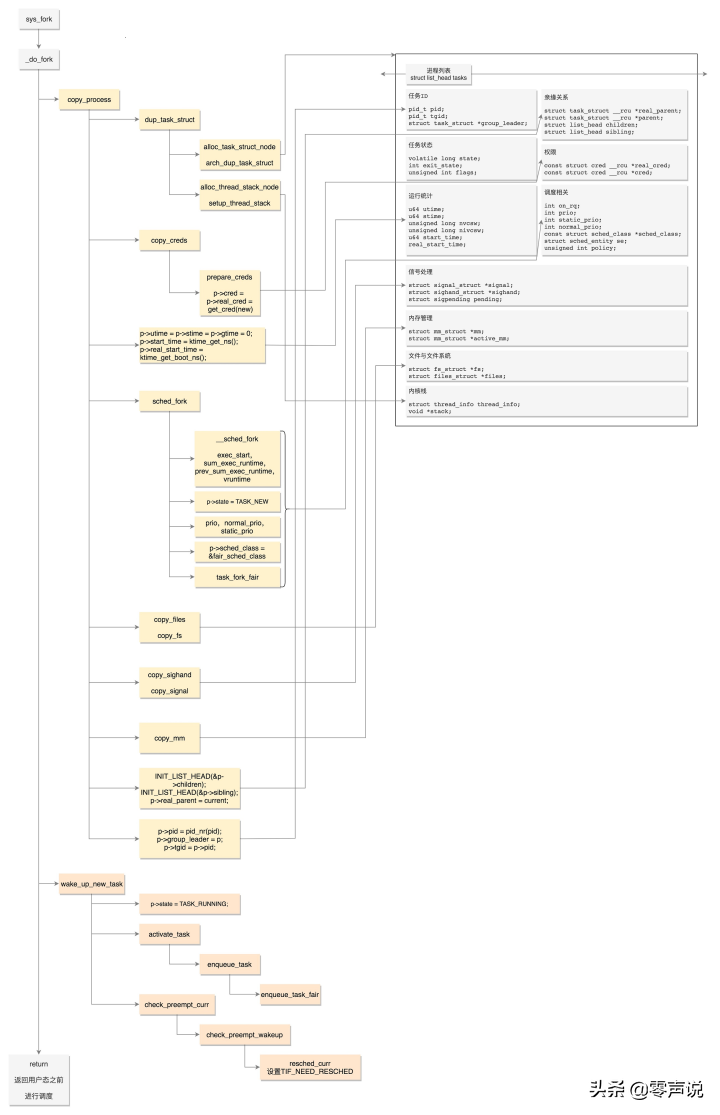
线程不是一个完全由内核实现的机制,它是由内核态和用户态合作完成的
调用clone系统调用
创建进程调用的系统调用是fork,在copy_process函数里面,会将五大结构files_struct、fs_struct、sighand_struct、signal_struct、mm_struct都复制一遍,从此父进程和子进程各用各的数据结构
创建线程调用的系统调用是clone,在copy_process函数里面,五大结构仅仅是引用计数加一,即线程共享进程的数据结构
Shell进程在读取用户输入的命令之后会调用fork复制出一个新的Shell进程,然后新的Shell进程调用exec执行新的程序
3个重要的寄存器
栈帧
每个函数每次调用,都有自己独立的栈帧,ESP指向当前栈帧的栈顶,EBP指向当前栈帧的栈底
栈从高地址向低地址扩展
push eax; == esp=esp-4;eax->[esp];
pop eax; == [esp]->eax;esp=esp+4;在main()里调用A(a, b)
CPU上下文:CPU相关寄存器
CPU上下文切换:保存前一个任务的CPU上下文,加载新任务的CPU上下文,然后运行新任务
根据任务不同,CPU上下文切换分成不同场景
进程可以在用户空间运行,也可以在内核空间运行,用户态和内核态的转变通过系统调用完成;
系统调用过程发生了CPU上下文切换
进程的切换发生在内核态,进程的上下文不仅包括了虚拟内存,栈,全局变量等用户空间的资源,还包括内核堆栈,寄存器等内核空间的状态
进程上下文切换比系统调用多了一步
当虚拟内存更新后,TLB也需要更新,内存访问会随之变慢,影响所有处理器的进程
线程上下文切换
中断上下文只包括内核中断服务程序执行所必需的的状态,包括CPU寄存器,内核堆栈,硬件中断参数等
过多的上下文切换,会把CPU时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正运行的时间,导致系统的整体性能大幅下降
# 每隔5s输出1组数据
vmstat 5
# cs(context switch)是每秒上下文切换的次数
# in(interrupt)则是每秒中断的次数
# r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待CPU的进程数
# b(Blocked)则是处于不可中断睡眠状态的进程数
# 每隔5s输出1组数据
pidstat -wt 5
# cswch 每秒自愿上下文切换的次数
# nvcswch 每秒非自愿上下文切换的次数Linux下只有一种类型的进程,就是task_struct
一个进程由于其运行空间的不同, 从而有内核线程和用户进程的区分, 内核线程运行在内核空间, 之所以称之为线程是因为它没有虚拟地址空间,只能访问内核的代码和数据。而用户进程则运行在用户空间,但是可以通过中断, 系统调用等方式从用户态陷入内核态
用户进程运行在用户空间上, 而一些通过共享资源实现的一组进程我们称之为线程组。linux下内核其实本质上没有线程的概念,linux下线程其实上是与其他进程共享某些资源的进程而已。但是我们习惯上还是称他们为线程或者轻量级进程
中断导致系统从用户态转为内核态
软件中断
用户进程调用系统调用时,会触发软件中断(第128号中断),该中断使得系统转到内核态,并执行相应的中断处理程序,中断处理程序根据系统调用号调用对应的系统调用
硬件中断
CPU收到硬件中断后,就会通知操作系统,每个硬件中断有对应一个中断号,并对应一个中断处理程序(ISR)
中断处理程序一般分为两部分(top half,bottom half),执行前面部分时会禁止所有中断,做一些有严格时限的工作,在执行后面部分时则允许被打断
Linux2.6之后,每个处理器都拥有一个中断栈专门用来执行中断处理程序
中断处理流程
用户态和内核态
系统调用、异常、外围设备中断会导致系统进入内核态
系统调用:malloc内存分配
异常:缺页异常
外围设备中断:鼠标键盘
从用户态转入内核态时,系统需要先保存进程上下文,切换到内核栈,更新寄存器,将权限修改为特权级,转而去执行相应指令
进程
线程
线程和进程的区别
协程
协程是用户态的轻量级线程,其调度由用户控制,共享进程的地址空间,协程有自己的栈和寄存器,在切换时需要保存/恢复状态,切换时减少了切换到内核态的开销. 一个进程和线程都可以有多个协程. 相比函数调用, 协程可以在遇到IO阻塞时交出控制权
多进程适用于CPU密集型,或者多机分布式场景中, 易于多机扩展
多线程模型的优势是线程间切换代价较小,因此适用于I/O密集型的工作场景,因此I/O密集型的工作场景经常会由于I/O阻塞导致频繁的切换线程。同时,多线程模型也适用于单机多核分布式场景
协程(coroutine)又叫微线程、纤程,完全位于用户态,一个程序可以有多个协程
协程的执行过程类似于子例程,允许子例程在特定地方挂起和恢复
协程是一种伪多线程,在一个线程内执行,由用户切换,由用户选择切换时机,没有进入内核态,只涉及CPU上下文切换,所以切换效率很高
缺点:协程适用于IO密集型,不适用于CPU密集型
对于单处理器系统,每次只允许一个进程运行,任何其他进程必须等待,直到CPU空闲能被调度为止,多道程序的目的是在任何时候都有某些进程在运行,以使CPU使用率最大化。
CPU密集转为IO密集
饥饿(starvation)是什么,如何解决
饥饿是指某进程因为优先级的关系一直得不到CPU的调度,可能永远处于等待/就绪状态;定期提升进程的优先级
 关注微信
关注微信