
经常在网上遇到一些无法复制的文章,那么问题来了,有什么办法可以绕开这种限制,将网页内容轻松下载回来呢?其实既然是网页内容,那么意味着HTML代码是公开的,将相关文本复制下来根本不是问题,一起来看看要怎么做吧。
方法一. 手机拍照识别
难度:●○○○○
效果:●●●●○
这是最简单一个办法了,如今的手机都自带文字识别功能。首先用QQ或微信将要识别的网页截取成图片,发送到你的手机。然后打开手机“扫一扫”,选择刚刚收到的网页截图,最后点击“识别文字”就可以了。一般来说,只要你的照片足够清晰,字体基本标准,那么实现95%以上的识别率还是不成问题的。稍后通读一下文章,将里面的识别错误简单修正一下,就能直接生成文件使用了。
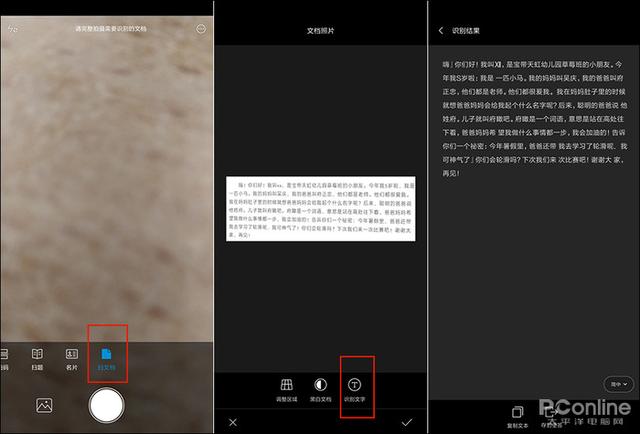
手机OCR识别网页内容
方法二. 切换IE内核
难度:●○○○○
效果:●●●○○
很多小伙伴都忽略过这个办法,如今IE已经被边缘化,绝大多数浏览器都是WebKit内核,网页设计师也是一样,因此当你发现一个网站设置了禁止复制时,不妨将网址拖拽到IE浏览器里试一试,没准会有意外惊喜!
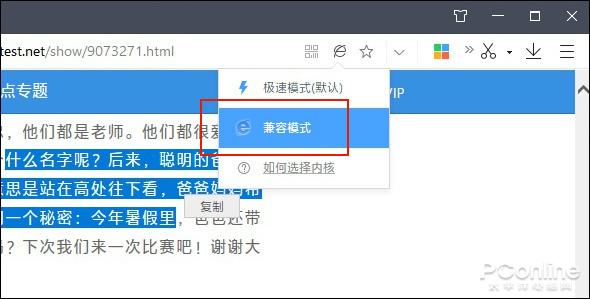
使用IE内核试一试,没准会有意外惊喜
顺便说一句,如今很多国产浏览器都使用了双内核,其中“兼容模式”就是IE核心,点击切换试一试吧,和拷贝到IE里是一个效果!
方法三. 查看源代码
难度:●●●●○○
效果:●●●●○○
如果借助上面这个方法“捡漏”不成功,那么就得动用一些“大招”了!这个方法基本可以搞定90%以上的网站,但操作起来稍微麻烦了一点。
1. 在禁止复制的网页上右击鼠标,选择“查看源代码”;
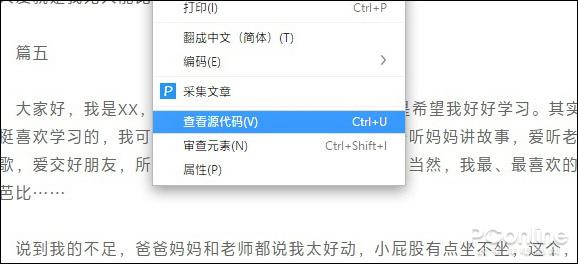
右键选择“查看源代码”
2. 将打开的源码页面下拉,找到带有文字内容的区域。选中这个区域,将内容粘贴到Word文档中;

这就是打开的效果了,下拉页面可以找到文字内容
3. 直接粘贴过来的内容会夹杂很多不必要的代码,这时就是“查找与替换”大显身手的时候了,将其中的代码复制到“查找”框内,然后将“替换为”设空,最后点击“全部替换”按钮,直至代码全部删除为止;
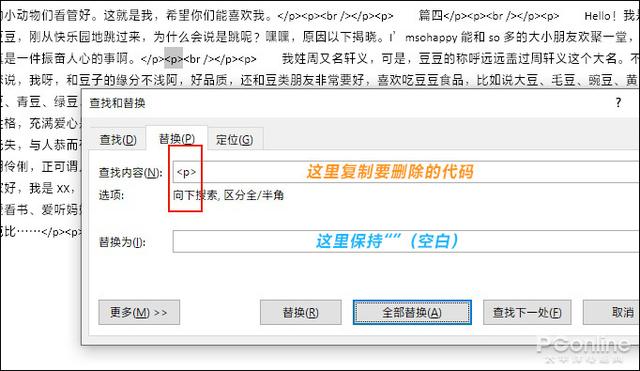
复制过来夹杂的不必要代码,直接用“查找与替换”搞定!很容易的!
方法四. 保存网页格式
难度:●●○○○○
效果:●●●●●○
这其实是上一组方法的“人性化”版,至少没有看起来很头疼的代码页了,而且它可以用在那些禁止鼠标右键的网页中。
1. 打开禁止复制的网页,按下快捷键Ctrl+S;
2. 在弹出的保存对话框中选择“网页,仅HTML”;
3. 双击保存好的网页文件,这时你会发现原本无法复制的内容已经可以正常拷贝了;
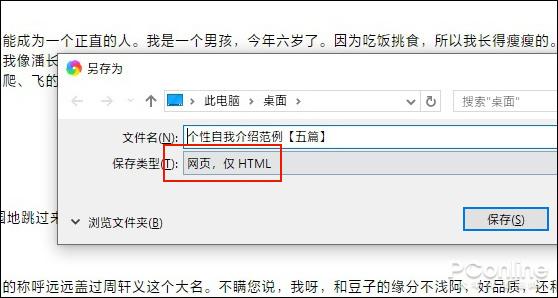
类似于方法三,但操作起来更简便
方法五. 打印法
难度:●●●●●○
效果:●●●●●○
这个方法只能用于WebKit内核浏览器(包括国产多数双核浏览器),只要在禁止复制的网页上按下Ctrl+P,进入打印预览模式,就能直接通过鼠标完成复制操作。
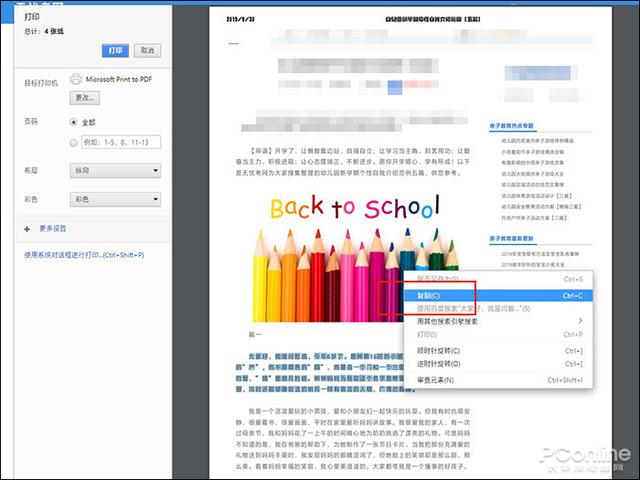
打印预览页面是可以直接复制的
方法六. 插件法
难度:●●●●●○
效果:●●●●●○
如果上面这些方法都不奏效,或者操作步骤太繁琐,这里还有一个终极大法,那就是借助插件完成。类似的插件有很多,比如Enable Copy,操作时只要将它安装到浏览器上,遇到有复制限制的页面点击一下,就能轻松破解这些限制,具体的大家可以自行尝试一下。
插件也是一个很好的选择
 关注微信
关注微信