
对于 MIN() 和 MAX() 查询, MySQL 而且优化做得并不是太好,例如
select MIN(id) FROM film where name = '西游记';
复制代码假设表 film 数据如下:
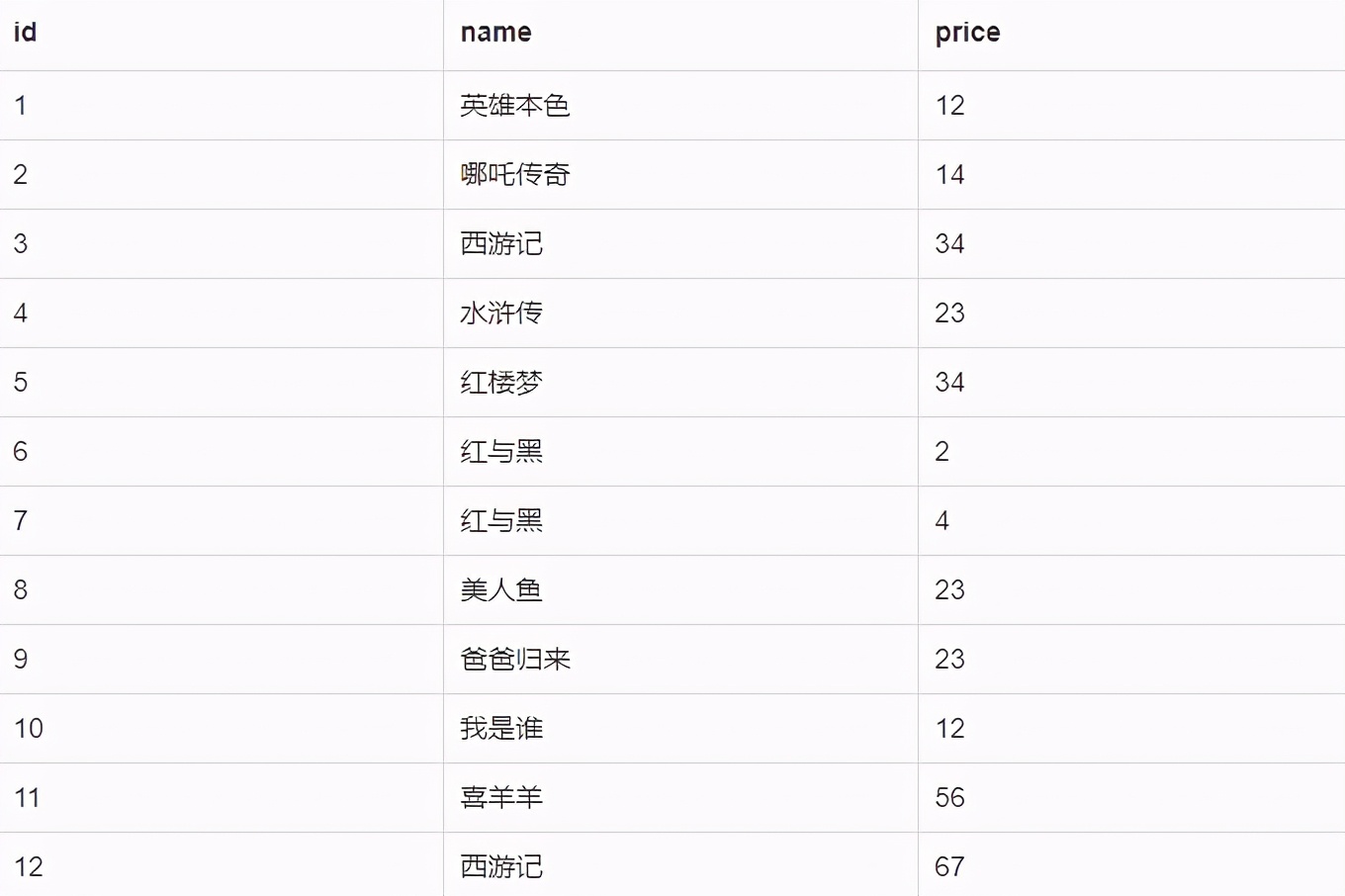
其中 id 为主键并自增, name 为 varchar 且没有索引
因为 name 没有索引,因为 MySQL 将会进行一次全表扫描。因为 id 为自增,那么我们可以当作,第一次找到 name=’西游记’ 时, id 就为我们想要的结果,此时我们可以改写 SQL 问:
select id FROM film where name = '西游记' limit 1;
复制代码此时当查到第一条记录时,就会停止继续查询,获得更高的性能。
在系统进行分页操作的时候,当偏移量大时,例如: limit 10000,20 时, MySQL 需要查询 10020 条记录然后只返回 20 记录,前面的记录全部被舍弃,这样的代价非常高
SELECT id, name, price FROM file LIMIT 10000 OFFSET 20
复制代码上面的 SQL 我想是分页常规的写法,写法没有什么错误,正如上面说到,浪费了大量的性能。
优化此类查询一个简单的方法就是尽可能地使用索引覆盖扫描,而不是查询所有的列,然后根据需要做一次关联操作再返回所需的列。对于偏移大的时候,这样做的效率提升非常大。
SELECT
id, name, price
FROM film
INNER JOIN (
SELECT id
FROM film
LIMIT 10000 OFFSET 20
) AS LIM USING(id)
复制代码有时候可以将 LIMIT 转化为已知位置的查询,让 MySQL 通过范围扫描获得到对应的结果。例如,如果在一个位置列上有索引,并且预先计算出了边界值,则改写查询为:
SELECT id, name, price
FROM film
WHERE position BETWEEN 10000 AND 10020
ORDER BY position
复制代码这里的唯一自增序列可以是自增 id 主键,也可以其他的具有唯一和升序的数字即可
在前面的思路中,我们考虑的都是传入页数和每页数量,在一些操作中可以改为传入上一次查询到的自增序列,然后往后查询对应的每页数量即可。
例如原来要求前端传入页数(pageIndex)和 每页数量(pageSize), 此时的 SQL 为
select * from film
limit (pageIndex -1) * pageSize OFFSET pageIndex * pageSize
复制代码如果改为让前端传入最后一次查询到结果的 自增序列(sid) 和 每页数量(pageSize)
比如这时的自增序列(sid) 就是 film 的 id, 则 SQL 可以改写成
select * from film
where id > sid
limit pageSize
复制代码当查第一页的时候,sid 传入 0 即可,查第二页的时候,传入获取第一页时最后得到 id 即可
在写 SQL 的时候,除了要考虑优化 SQL 降低执行时间外,有时还要防止 SQL 被 MySQL 本身给你优化掉,造成执行结果和你想象的不一样。
在 MySQL 使用 group by 语句进行查询时,当有多条数据都满足时,会显示第一条数据例如:
假设表 film 数据如下:

则执行SQL select * from film group by name , 则结果为:
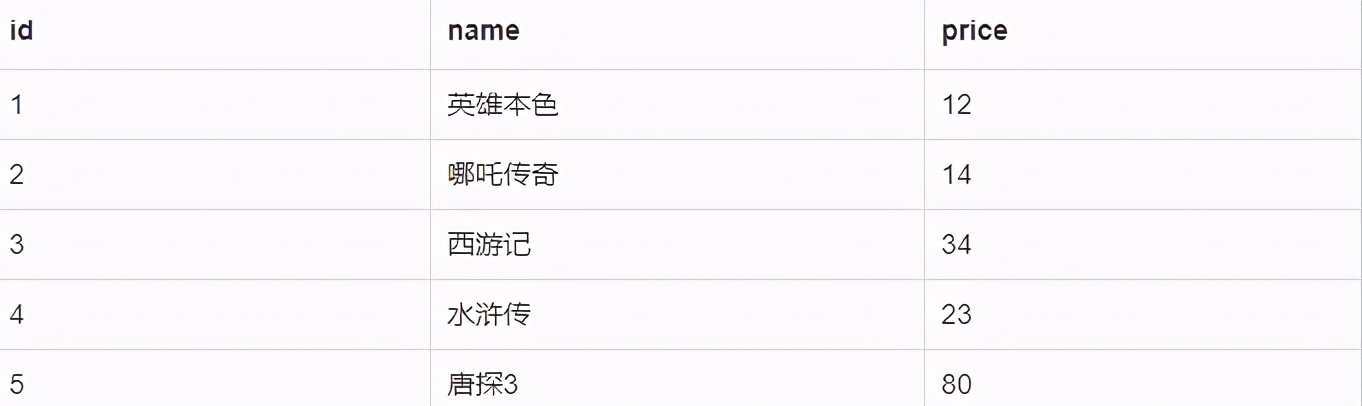
但在一些数据重复时,我们往往想要最后一条数据, 这是我们会想到通过子查询的形式先排序后group by 如下:
select *
from ( select * from film order by id desc) as film_ordered
group by name;
复制代码执行后发现结果没变, 这是因为 MySQL5.7 会对子查询进行优化,认为子查询中的 order by 可以进行忽略,只要Derived table里不包含如下条件就可以进行优化:
根据上面说明,我们可以使用 limit 阻止子查询优化,改写后SQL
select *
from ( select * from film order by id desc limit 10000000) as film_ordered
group by name;
复制代码这样结果就符合我们想要的了
 关注微信
关注微信