
一,为什么要冗余数据
互联网数据量很大的业务场景,往往数据库需要进行水平切分来降低单库数据量。
水平切分会有一个patition key,通过patition key的查询能够直接定位到库,但是非patition key上的查询可能就需要扫描多个库了。
此时常见的架构设计方案,是使用数据冗余这种反范式设计来满足分库后不同维度的查询需求。
例如:订单业务,对用户和商家都有订单查询需求:
Order(oid, info_detail);
T(buyer_id, seller_id, oid);
如果用buyer_id来分库,seller_id的查询就需要扫描多库。
如果用seller_id来分库,buyer_id的查询就需要扫描多库。
此时可以使用数据冗余来分别满足buyer_id和seller_id上的查询需求:
T1(buyer_id, seller_id, oid)
T2(seller_id, buyer_id, oid)
同一个数据,冗余两份,一份以buyer_id来分库,满足买家的查询需求;一份以seller_id来分库,满足卖家的查询需求。
如何实施数据的冗余,是今天将要讨论的内容。
二,服务同步双写
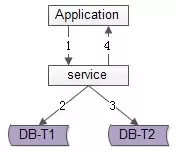
顾名思义,由服务层同步写冗余数据,如上图1-4流程:
优点:
缺点:
如果系统对处理时间比较敏感,引出常用的第二种方案。
三,服务异步双写
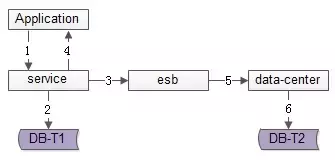
数据的双写并不再由服务来完成,服务层异步发出一个消息,通过消息总线发送给一个专门的数据复制服务来写入冗余数据,如上图1-6流程:
优点:
缺点:
不管是服务同步双写,还是服务异步双写,服务都需要关注“冗余数据”带来的复杂性。如果想解除“数据冗余”对系统的耦合,引出常用的第三种方案。
四,线下异步双写
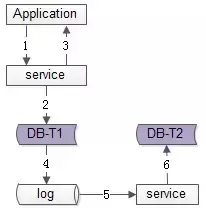
为了屏蔽“冗余数据”对服务带来的复杂性,数据的双写不再由服务层来完成,而是由线下的一个服务或者任务来完成,如上图1-6流程:
优点:
缺点:
五,总结
互联网数据量大的业务场景,常常:
 关注微信
关注微信