

1、第一个示例,我们要来进行简单的爬虫来爬别人的网页
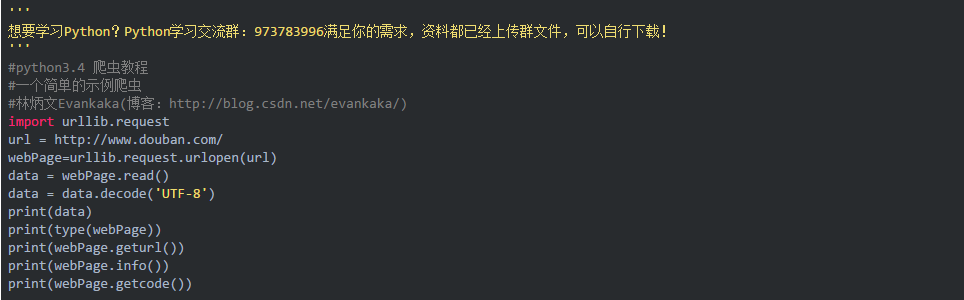
这是爬回来的网页输出:
这中间到底发生了什么事呢?让我们打开Fiddler来看看吧:
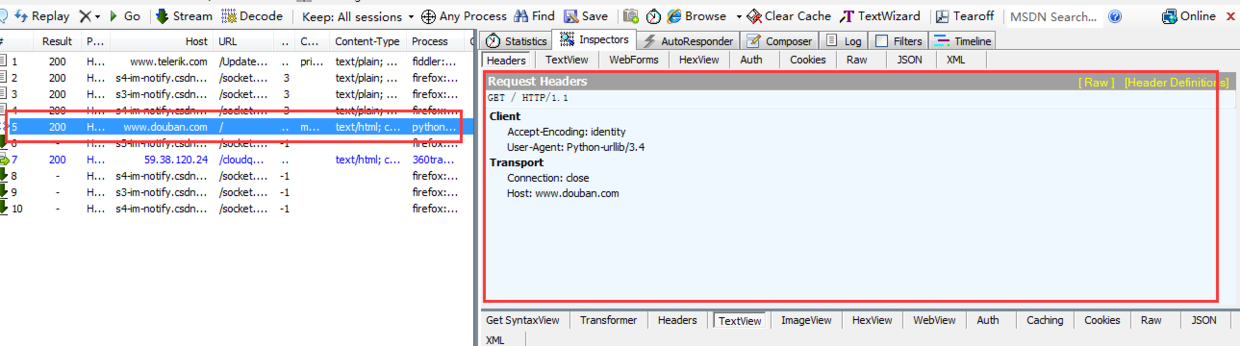
左边标红的就表示我们本次访问成功,为http 200
右边上方这是python生成 的请求报头,不清楚看下面:
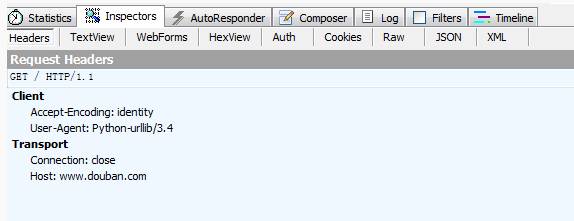
很简单的一个报头,然后再来看看响应回来的html
这里响应回来的就是我们上面在python的idle中打印出来的网页了!
2、伪装成浏览器来爬网页
有些网页,比如登录的。如果你不是从浏览器发起的起求,这就不会给你响应,这时我们就需要自己来写报头。然后再发给网页的服务器,这时它就以为你就是一个正常的浏览器。从而就可以爬了!
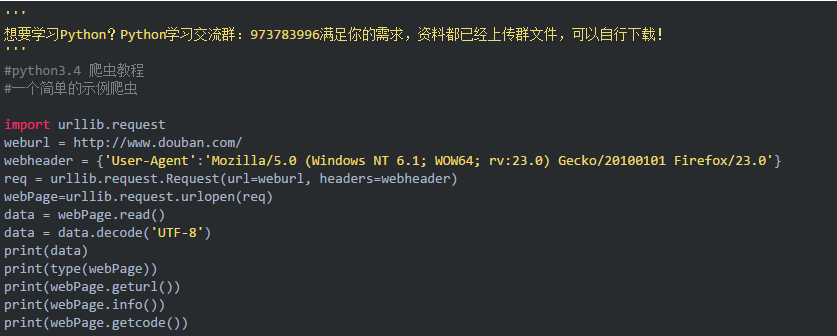
3、爬取网站上的图片
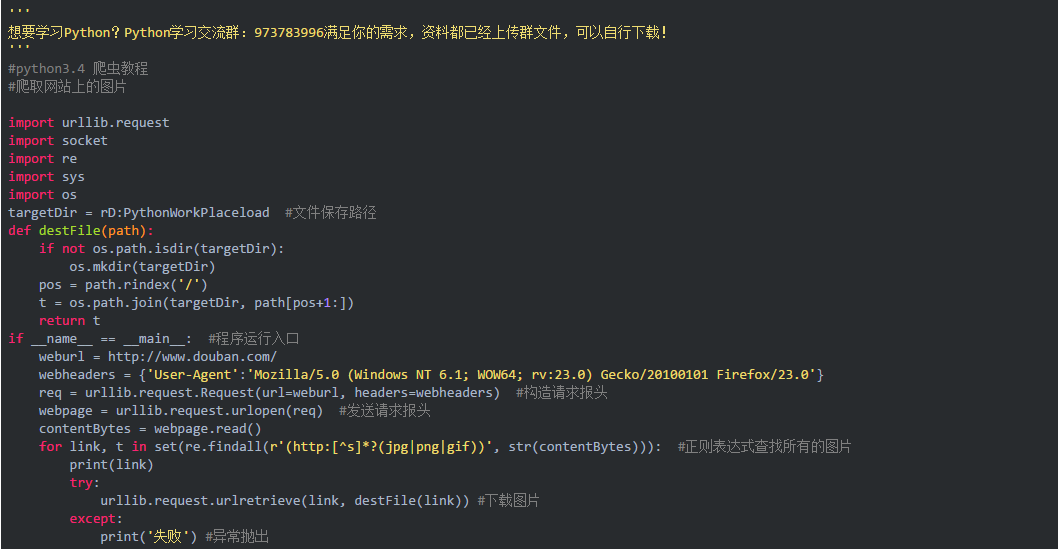
Python3.x 自动登录
python3.4代码编写:
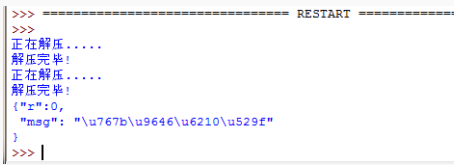
来看看结果:
这时运行返回的
 关注微信
关注微信