
byte :1个字节
short :2个字节
char :2个字节
int :4个字节
long :8个字节
float :4个字节
double :8个字节Java集合框架的根接口有Collection和Map。Collection根接口包含List和Set二个子接口。
List接口
它的特点是:元素有序、且可重复,主要包含三个实现类:ArrayList,vector,LinkedList
ArrayList的特点:底层是数组,线程不安全,查找快,增删慢(数组的特点)。
ArrayList的底层实现原理:通过ArrrayList空参构造器创建对象。
底层创建一个长度为10的数组,当我们向数组中添加11个元素时,底层会进行扩容,扩容为原来的1.5倍
(创建一个新的数组,长度为原数组长度的1.5倍,将原数组复制到新数组中)。
vector的特点:古老的实现类,底层是数组,线程安全的,JDK1.0就有了,Vector总是比ArrayList慢,所以尽量避免使用。
LinkedList的特点:底层是使用双向链表。增删快,查找慢。Set接口
它的特点:
无序性:通过HashCode方法算出的值来决定在数组中存放的位置;
不可重复性:进行equals方法比较,结果为true则两个数据相同,若为false则不同。
主要包含三个实现类:HashSet,LinkedHashSet,TreeSet
HashSet特点:线程不安全,集合元素可以为null,不能保证元素的排列顺序
HashSet的底层实现原理:
当向HashSet添加数据时,首先调用HashCode方法决定数据存放在数组中的位置,该位置上没有其他元素,
则将数据直接存放,若该位置上有其他元素,调用equals方法进行比较。若返回true则认为两个数据相同,
若返回false,则以链表的形式将该数据存在该位置上,(jdk1.8)如果数量达到8则将链表换成红黑树。
HashSet的底层就是一个HashMap,向HashSet中添加的数据实际上添加到了HashMap中的key里。
所以HashMap的key可以看成是Set的集合。
LinkedHashSet特点:继承了HashSet,底层实现原理和HashSet一样,可以安照元素添加的顺序进行遍历
根据元素的hashCode值来决定元素的存储位置,它维护了一张链表该链表记录了元素添加的顺序。
底层就是一个LinkedHashMap。
TreeSet特点:底层为红黑树;可以安照指定的元素进行排序;TreeSet中的元素类型必须保持一致,
底层就是TreeMap。TreeSet必须(自然排序)实现Comparable接口,重写compareTo()方法,
按照某个属性进行排序,相结合添加元素或(定制排序)创建一个Comparator实现类的对象,
并传入到TreeSet的构造器中,按照某个属性进行排序,向集合添加元素。定制排序比自然排序灵活。
如果即有自然排序又有定制排序谁起作用? 定制排序Map接口
Map的特点:
Map存储的是键值对(key,value),Map中的key是无序的且不可重复的,所有的key可以看成是一个set集合。
Map中的key如果是自定义类的对象必须重写hashCode和equals方法,Map中的value是无序的可重复的,
所有的value可以看成是Collection集合,Map中的value如果是自定义类的对象必须重写equals方法,
Map中的键值对可以看成是一个一个的Entry.Entry所存放的位置是由key来决定的。
Entry是无序的不可重复的。主要的实现类:HashMap,LinkedHashMap,TreeMap,HashTable.
HashMap特点
1.底层是一个数组 + 链表 + 红黑树(jdk1.8)
2.数组的类型是一个Node类型
3.Node中有key和value的属性
4.根据key的hashCode方法来决定Node存放的位置
5.线程不安全的 ,可以存放null
HashMap的底层实现原理:
当我们向HashMap中存放一个元素(k1,v1),先根据k1的hashCode方法来决定在数组中存放的位置。
如果该位置没有其它元素则将(k1,v1)直接放入数组中,如果该位置已经有其它元素(k2,v2),调用k1的equals方法和k2进行比较。
如果结果为true则用v1替换v2,如果返回值为false则以链表的形式将(k1,v1)存放,
当元素达到8时则会将链表替换成红黑树以提高查找效率。
HashMap的构造器:new HashMap() :创建一个容量为16的数组,加载因子为0.75。
当我们添加的数据超过12时底层会进行扩容,扩容为原来的2倍。
LinkedHashMap:继承了HashMap底层实现和HashMap一样.
可以安照元素添加的顺序进行遍历底层维护了一张链表用来记录元素添加的顺序。
TreeMap特点:可以对Key中的元素安照指定的顺序进行排序 ( 不能对value进行排序)
HashTable特点:线程安全的 ,不可以存放null,map中的key不能重复,如果有重复的,后者的value覆盖前者的value四大作用域:
page :当前页面有效时间最短(页面执行期)
request :HTTP请求开始到结束这段时间
session :HTTP会话开始到结束这段时间
application :服务器启动到停止这段时间九大内置对象:
request :请求对象 作用域 Request
response :响应对象 作用域 Page
pageContext :页面上下文对象 作用域 Page
session :会话对象 作用域 Session
application :应用程序对象 作用域 Application
out :输出对象 作用域 Page
config :配置对象 作用域 Page
page :页面对象 作用域 Page
exception :例外对象 作用域 pagejsp和servlet的区别
1.jsp经编译后就变成了Servlet.(JSP的本质就是Servlet,JVM只能识别java的类,
不能识别JSP的代码,Web容器将JSP的代码编译成JVM能够识别的java类)
2.jsp更擅长表现于页面显示,servlet更擅长于逻辑控制.
3.Servlet中没有内置对象,Jsp中的内置对象都是必须通过HttpServletRequest象,
HttpServletResponse对象以及HttpServlet对象得到.
Jsp是Servlet的一种简化,使用Jsp只需要完成程序员需要输出到客户端的内容,Jsp中的Java脚本如何镶嵌到一个类中,由Jsp容器完成。
而Servlet则是个完整的Java类,这个类的Service方法用于生成对客户端的响应。servlet生命周期
1.加载和实例化
2.初始化
3.请求处理
4.服务终止
加载(服务器启动时,会到web.xml文件中去找到Servlet文件的配置并创建servlet的实例)
→初始化(init()此方法只执行一次) →执行(service(),doGet(),doPost()) →销毁(销毁destory())
service():
方法本身包含了doGet()和doPost().如果服务器发现了service()方法,则不再执行doGet(),doPost().
一般不建议去重写父类的service方法.因为重写了此方法doGet方法和doPost方法将得不到利用.
没有service()方法默认执行doGet()方法.cookie和session区别以及JWT与Session的差异
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用cookie。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
5、可以考虑将登陆信息等重要信息存放为session,其他信息如果需要保留,可以放在cookie中。
1.Session是在服务器端的,而JWT是在客户端的。
2.Session方式存储用户信息的最大问题在于要占用大量服务器内存,增加服务器的开销。
3.JWT方式将用户状态分散到了客户端中,可以明显减轻服务端的内存压力。
4.Session的状态是存储在服务器端,客户端只有session id;而Token的状态是存储在客户端。OAuth2是一种授权框架 ,JWT是一种认证协议。
无论使用哪种方式切记用HTTPS来保证数据的安全性
OAuth2用在使用第三方账号登录的情况(比如使用weibo, qq, github登录某个app)
JWT是用在前后端分离, 需要简单的对后台API进行保护时使用。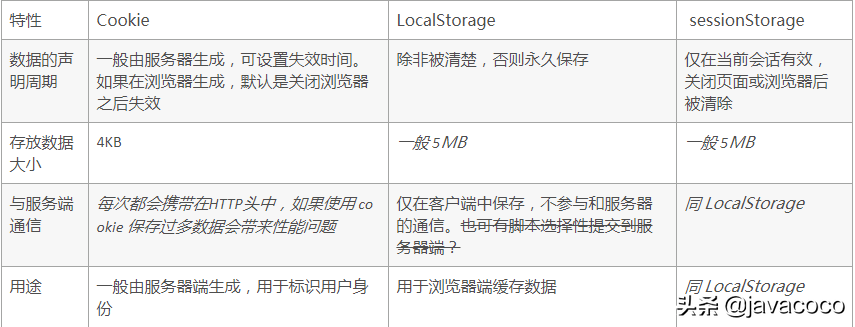
转发:浏览器地址栏不变,1次请求,request请求,可以访问web-inf,可以共享request请求域数据,只能跳转工程内的资源
重定向:浏览器变化,2次请求,response响应,不能访问web-inf,不可以共享request请求域数据,可以跳转任意资源
单例模式设计:
第一步:私有化构造器
第二步:提供一个公共静态返回该类实例对象的方法
饿汉式:先初始化对象,Single类一进内存,就已经创建好了对象。
class Single{
private Single(){}
private static Single s=new Single();
public static Single getInstance()
{
return s;
}
}
懒汉式:对象是方法被调用时,才初始化,也叫做对象的延时加载。
class Single{ //Single类进内存,对象还没存在,只有调用了getInstance方法时,才建立对象
private Single(){}
private static Single s=null;
public static synchronize Single getInstance()
{
if(s==null){
s=new single();
}
return s;
}
}
操作共享的数据有多条,会出现线程安全问题,在方法加一个同步①拦截器是基于java的反射机制的,而过滤器是基于函数回调。
②拦截器不依赖与servlet容器,过滤器依赖与servlet容器。
③拦截器只能对action请求起作用,而过滤器则可以对几乎所有的请求起作用。
④拦截器可以访问action上下文、值栈里的对象,而过滤器不能访问。
⑤在action的生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时被调用一次。
⑥拦截器可以获取IOC容器中的各个bean,而过滤器就不行,这点很重要,在拦截器里注入一个service,可以调用业务逻辑。#{}和${}的区别
#{} 在mapper的配置文件的sql语句中,它是占位符, 相当于 # 号。
${} 在 mapper 的配置文件的 sql 语句中,它是原样输出变量的值,然后以字符串拼接的功能进行操作。
${} 中只能写value,或者是@Param命名参数后的参数名称
在输出参数的时候,我们并不推荐使用 ${} 来输出。因为可能会导至 sql 注入问题的存在。
什么是SQL注入?
如果SQL是根据用户输入拼出来,如果用户故意输入可以让后台解析失败的字符串,这就是SQL注入
例如,用户在输入密码的时候,输入' or 1=1', 这样,后台的程序在解析的时候,拼成的SQL语句,可能是这样的:
select count(1) from tab where user=userinput and pass='' or 1=1;
看这条语句,可以知道,在解析之后,用户没有输入密码,加了一个恒等的条件 1=1,这样,这段SQL执行的时候,
返回的 count值肯定大于1的,如果程序的逻辑没加过多的判断,这样就能够使用用户名 userinput登陆,而不需要密码。
防止SQL注入,首先要对密码输入中的单引号进行过滤,再在后面加其它的逻辑判断,或者不用这样的动态SQL拼。&和&&的区别?
&和&&左边的式子为true的时候,右边的式子都会执行。
左边的式子为false的时候。&右边的式子仍然会执行。&&右边的式子将不再执行。
|和||的区别?
|和||左边的式子为false的时候,右边的式子都会执行。
左边的式子为true的时候。|右边的式子仍然会执行。||右边的式子将不再执行。 final修饰符,用来修饰变量,方法和类,分别表示属性不可变,方法不可被重写,类不可被继承,finally是异常语句中处理语句,
表示总是执行;finalize表示在垃圾回收机制时使该对象状态恢复的方法1、Integer是int的包装类,int则是java的一种基本数据类型
2、Integer变量必须实例化后才能使用,而int变量不需要
3、Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
4、Integer的默认值是null,int的默认值是0==:如果==两边是基本数据类型,那么比较的是具体的值。如果==两边是引用数据类型,那么比较的是地址值。
(两个对象是否指向同一块内存)
equals:如果没有重写equals方法那么调用的是Object中的equals方法,比较的是地址值。
如果重写了euqlas方法(比属性内容)那么就比较的是对象中属性的内容。
StringBuff 和StringBuilder及String区别?
String类是不可变类,任何对String的改变都会引发新的String对象的生成;
StringBuffer是可变类,任何对它所指代的字符串的改变都不会产生新的对象,线程安全的。
StringBuilder是可变类,线性不安全的,不支持并发操作,不适合多线程中使用,但其在单线程中的性能比StringBuffer高。1. Override 特点
1、覆盖的方法的标志必须要和被覆盖的方法的标志完全匹配,才能达到覆盖的效果;
2、覆盖的方法的返回值必须和被覆盖的方法的返回一致;
3、覆盖的方法所抛出的异常必须和被覆盖方法的所抛出的异常一致,或者是其子类;
4、方法被定义为final不能被重写。
5、对于继承来说,如果某一方法在父类中是访问权限是private,那么就不能在子类对其进行重写覆盖,如果定义的话,
也只是定义了一个新方法,而不会达到重写覆盖的效果。(通常存在于父类和子类之间。)
2.Overload 特点
1、在使用重载时只能通过不同的参数样式。例如,不同的参数类型,不同的参数个数,不同的参数顺序
当然,同一方法内的几个参数类型必须不一样,例如可以是fun(int, float), 但是不能为fun(int, int)
2、不能通过访问权限、返回类型、抛出的异常进行重载;
3、方法的异常类型和数目不会对重载造成影响;
4、重载事件通常发生在同一个类中,不同方法之间的现象。
5、存在于同一类中,但是只有虚方法和抽象方法才能被覆写。 1、抽象类和接口都不能直接实例化,如果要实例化,抽象类变量必须指向实现所有抽象方法的子类对象,
接口变量必须指向实现所有接口方法的类对象。
2、抽象类要被子类继承,接口要被类实现。
3、接口只能做方法申明,抽象类中可以做方法申明,也可以做方法实现
4、接口里定义的变量只能是公共的静态的常量,抽象类中的变量是普通变量。
5、抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类抽象方法,那么该子类只能是抽象类。
同样,一个实现接口的时候,如不能全部实现接口方法,那么该类也只能为抽象类。
6、抽象方法只能申明,不能实现,接口是设计的结果 ,抽象类是重构的结果
7、抽象类里可以没有抽象方法
8、如果一个类里有抽象方法,那么这个类只能是抽象类
9、抽象方法要被实现,所以不能是静态的,也不能是私有的。
10、接口可继承接口,并可多继承接口,但类只能单根继承。一.堆栈空间分配区别:
1.栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈;
2.堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
二.堆栈缓存方式区别:
1.栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放;
2.堆是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。
所以调用这些对象的速度要相对来得低一些。
三.堆栈数据结构区别:
堆(数据结构):堆可以被看成是一棵树,如:堆排序;
栈(数据结构):一种先进后出的数据结构。实例化bean对象
设置对象属性
检查Aware相关接口并设置相关依赖
BeanPostPreocessor前置处理
检查是否是InitialliziingBean以决定是否调用afterPropertesSet方法
检查是否配置有自定义的init-method
BeanPostProcessor后置处理
注册必要的Destrunction相关回调接口
使用中
是否实现DisposableBean接口
是否配置有自定义的Destory方法
JDK ( Java开发工具包)= JRE(Java运行环境) + 开发工具集(例如Javac编译工具等)
JRE (Java运行环境)= JVM (Java虚拟机)+ Java SE标准类库
值传递:会创建副本,函数中无法改变原始对象
引用传递:不会创建副本,函数中可以改变原始对象
值传递:方法调用时,实际参数把它的值传递给对应的形式参数,方法执行中形式参数值的改变不影响实际参数的值。
引用传递:也称为传地址。方法调用时,实际参数的引用(地址,而不是参数的值)被传递给方法中相对应的形式参数,
在方法执行中,对形式参数的操作实际上就是对实际参数的操作,方法执行中形式参数值的改变将会影响实际参数的值。 访问权限 类 包 子类 其他包
public ∨ ∨ ∨ ∨
protect ∨ ∨ ∨ ×
default ∨ ∨ × ×
private ∨ × × ×装箱:值类型转换为引用对象,一般是转换为System.Object类型或值类型实现的接口引用类型;
拆箱:引用类型转换为值类型,注意,这里的引用类型只能是被装箱的引用类型对象;
拆箱与装箱就是值类型与引用类型的转换throw代表动作,表示抛出一个异常的动作;
throws代表一种状态,代表方法可能有异常抛出;
throw用在方法实现中,而throws用在方法声明中;
throw只能用于抛出一种异常,而throws可以抛出多个异常。第一:statement执行的SQL语句必须是一个完整的SQL,而对于PreparedStatement来说,可以使用“?”作为
SQL语句当中的占位符,然后使用PreparedStatement的setXXX方法来给占位符赋值,最后在执行;
第二:使用Statement时,如果SQL当中出现了“‘”或者“-”等符号时,需要使用转义字符来进行转义,而在
PreparedStatement当中,如果占位符的值当中有这些符号,PreparedStatement会自动的进行转义;
第三:PreparedStatement会讲SQL语句进行预编译,每次执行的时候只需要将参数设置给相应的占位符就可以
运行。而使用Statement时,SQL语句时每次都要进行编译,所以PreparedStatement的效率相对较高。get方式 参数在地址栏中显示 通过#name="&id="这种形式传递的 不安全 只能传递2kb的能容
post方式 底层是通过流的形式传递 不限制大小 上传的时候必须用Post方式
doGet:路径传参。效率高,安全性差
doPOST:实体传参。效率第,安全性好undefined是访问一个未初始化的变量时返回的值,而null是访问一个尚未存在的对象时所返回的值。
Error(错误)是系统中的错误,程序员是不能改变的和处理的,是在程序编译时出现的错误,只能通过修改程序才能修正。
一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢等。
对于这类错误的导致的应用程序中断,仅靠程序本身无法恢复和和预防,遇到这样的错误,建议让程序终止。
Exception(异常)表示程序可以处理的异常,可以捕获且可能恢复。遇到这类异常,应该尽可能处理异常,使程序恢复运行,
而不应该随意终止异常。1. 同步,就是我调用一个功能,该功能没有结束前,我死等结果。
2. 异步,就是我调用一个功能,不需要知道该功能结果,该功能有结果后通知我(回调通知)
3. 阻塞,就是调用我(函数),我(函数)没有接收完数据或者没有得到结果之前,我不会返回。
4. 非阻塞,就是调用我(函数),我(函数)立即返回,通过select通知调用者
同步IO和异步IO的区别就在于:数据拷贝的时候进程是否阻塞
阻塞IO和非阻塞IO的区别就在于:应用程序的调用是否立即返回1)原子性(Atomic):事务中各项操作,要么全做要么全不做,任何一项操作的失败都会导致整个事务的失败;
2)一致性(Consistent):事务结束后系统状态是一致的;
3)隔离性(Isolated):并发执行的事务彼此无法看到对方的中间状态;
4)持久性(Durable):事务完成后所做的改动都会被持久化,即使发生灾难性的失败。通过日志和同步备份可以在故障发生后重建数据。
脏读:事务A读到了事务B未提交的数据。
不可重复读:事务A第一次查询得到一行记录row1,事务B提交修改后,事务A第二次查询得到row1,但列内容发生了变化,侧重于次数,
侧重于update
幻读:事务A第一次查询得到一行记录row1,事务B提交修改后,事务A第二次查询得到两行记录row1和row2,侧重于内容,侧重于insertsleep()不释放同步锁,wait()释放同步锁.
sleep可以用时间指定来使他自动醒过来,如果时间不到你只能调用interreput()来强行打断;
wait()可以用notify()直接唤起.
sleep和wait的区别还有:
1。这两个方法来自不同的类分别是Thread和Object
2。最主要是sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。
3。wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用创建、就绪、运行、阻塞、终止。
1、新建状态(New):新创建了一个线程对象。
2、就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start()方法。该状态的线程位于“可运行线程池”中,
变得可运行,只等待获取CPU的使用权。即在就绪状态的进程除CPU之外,其它的运行所需资源都已全部获得。
3、运行状态(Running):就绪状态的线程获取了CPU,执行程序代码。
4、阻塞状态(Blocked):阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。NullPointerException - 空指针引用异常
ClassCastException - 类型强制转换异常。
IllegalArgumentException - 传递非法参数异常。
ArithmeticException - 算术运算异常
ArrayStoreException - 向数组中存放与声明类型不兼容对象异常
IndexOutOfBoundsException - 下标越界异常
NegativeArraySizeException - 创建一个大小为负数的数组错误异常
NumberFormatException - 数字格式异常
SecurityException - 安全异常
UnsupportedOperationException - 不支持的操作异常互联网 强调的是信息/数据在网络之间的流通,
BIO:堵塞式IO,相当于轮船运输
NIO:非堵塞式IO:面向缓冲区(buffer),基于通道(chanel)的io操作,相当于火车运输,效率高
文件->双向通道((缓冲区))->程序冒泡排序
int[] arr={6,3,8,2,9,1};
System.out.println("排序前数组为:");
for(int num:arr){
System.out.print(num+" ");
}
for(int i=0;i<arr.length-1;i++){//外层循环控制排序趟数
for(int j=0;j<arr.length-1-i;j++){//内层循环控制每一趟排序多少次
if(arr[j]>arr[j+1]){
int temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
System.out.println();
System.out.println("排序后的数组为:");
for(int num:arr){
System.out.print(num+" ");
}
自然排序
1、定义一个类(文章中为Employee)实现Comparable接口
2、重写Comparable接口中的compareTo()方法
3、在compareTo()中按指定属性进行排序
public class Employee implements Comparable{
public int compareTo(Object o) {
if (o instanceof Employee) {
Employee e = (Employee) o;
return this.name.compareTo(e.name);//按name进行排序
}
return 0;
}
}
定制排序
1.创建一个Compartor实现类的对象,并传入到TreeSet的构造器中
2.重写compare方法
3.安照某个属性进行排序
4.向集合中添加元素
TreeSet set = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if(o1 instanceof Student && o2 instanceof Student) {
Student s1 = (Student)o1;
Student s2 = (Student)o2;
int s = s1.getAge() - s2.getAge();
if(s == 0) {
return s1.getName().compareTo(s2.getName());
}
return s;
}
return 0;
}
});
set.add(new Student("aaa", 18));
set.add(new Student("bbb", 8));
set.add(new Student("fff", 38));
set.add(new Student("ccc", 28));
System.out.println(set);
在使用定制排序或是自然排序时,在其用到的类中都要重写hashCode()与equals()方法第一种遍历方法和输出结果。
for(int i=1,i<list.size(),i++){
System.out.println(list.get(i));
}第二种用foreach循环。加强型for循环。推荐方式。
for(String string:list){
System.out.println(string);
}第三钟迭代器
List<String> list=new ArrayList<>();
list.add("abc");
list.add("ghi");
for(Iterator<String> it=list.iterator();it.hasNext();){
System.out.println(it.next());
} 关注微信
关注微信