
一、应用数据模型概念
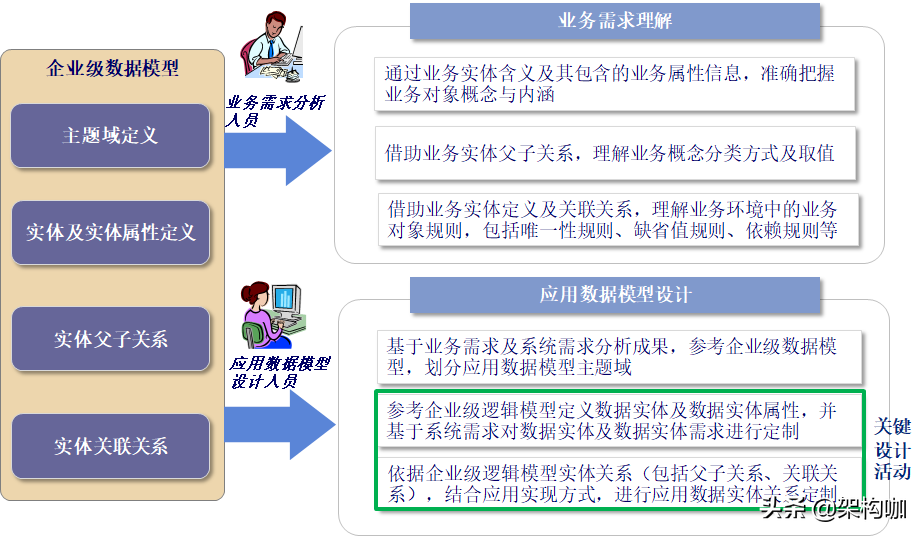
二、应用数据模型设计原则
关注点:重点关注数据量大、访问频繁的实体进行应用数据模型的整改,如合约、结算、客户。
集成度:过多地进行数据冗余和衍生则会导致灵活性下降,同时增加维护数据集成的复杂度。如合约中增加结算、客户信息。
最小化:为了维护数据模型的灵活性和可扩展性,尽量遵循对企业级逻辑模型最小化修改的原则。
存储量:数据模型根据非范式化原则进行考虑,则很容易导致数据冗余,从而加大对数据库存储需求的增加。
三、应用数据模型设计内容

非范式化与范式化:
范式化数据模型:企业级数据模型是在范式化的应用规则下,考虑灵活性、重用性等原则建立的。由于范式化不建议数据冗余等使用原则,因此为了充分体现数据关系的清晰性,从而使数据实体相对分散,在应用数据模型进行直接使用,则会由于多表关联查询、访问路径长等原因导致应用系统的处理能力下降。
非范式化数据模型:应用数据模型设计的主要活动是在企业级逻辑数据模型的基础上结合本应用的特征、性能等因素进行非范式化的过程。对数据模型的非范式化应用虽然可以通过合并实体等方法减少数据实体之间的联合查询从而最大化地提高数据库访问性能和减少数据管理的复杂度,但也会导致不良的效果,如数据集成规则复杂化、数据更新不规则化,同时也大大降低了数据模型的灵活性和重用性原则。因此应用数据模型在设计时必须坚持考虑灵活性和高性能之间的平衡关系。
四、应用数据模型设计方法
1、实体整合原则
(1)超类或子类实体整合
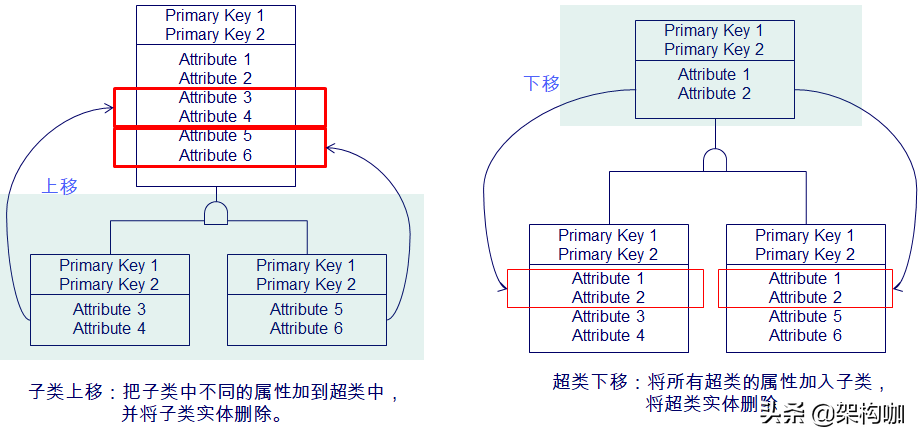
如果子类属性很少,就将子类属性上移;否则,也是大多数情况下,则将“超类下移”。
1)子类上移的影响
2)超类下移的影响
(2)实体上移或下移
如果两个实体同时访问和创建的可能性很高,则可以整合为一个实体。这些动作创建了包含两个实体组合属性的非范式化实体。

(3)实体上移
“上移”有两种方法,第一种方法,子实体的属性信息无法直接作为查询条件,则此时可以将子实体的信息上移到主实体信息中,如下:
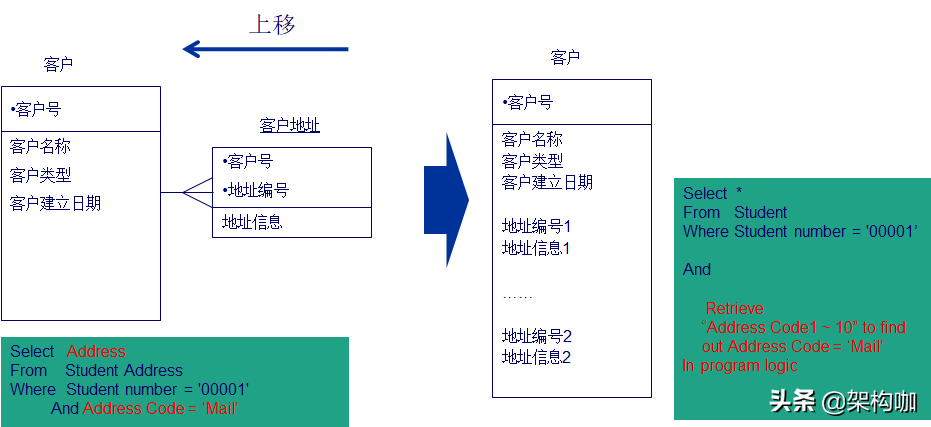
方法2,将需要访问的属性信息上移到主实体中直接进行访问,则会导致数据的灵活性降低。
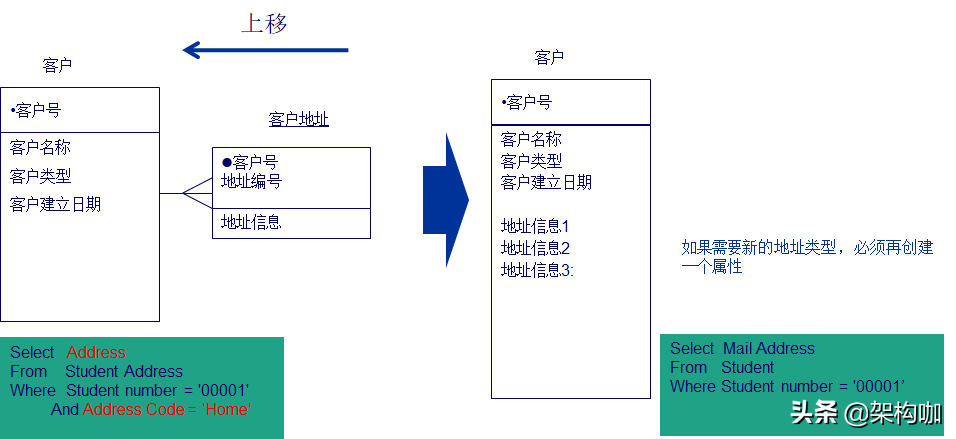
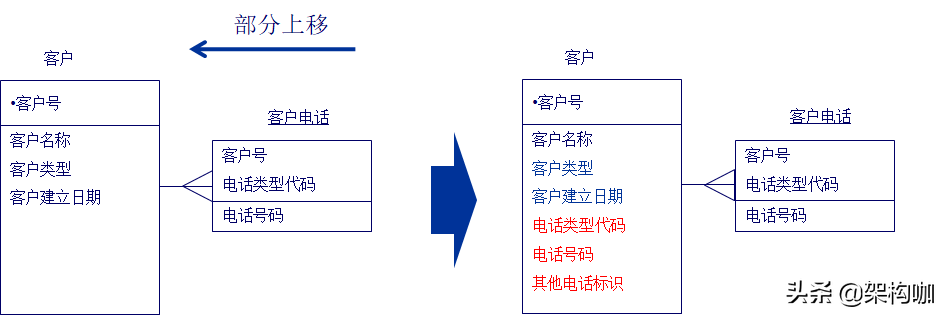
(4)部分上移
有些情况下,将实体中的属性信息采用部分“上移”。但是这样做相比全部“上移”,增加了应用的复杂性,一般情况下所以很少使用。若关系信息大多是1对1的关系,则可以采用此方法。
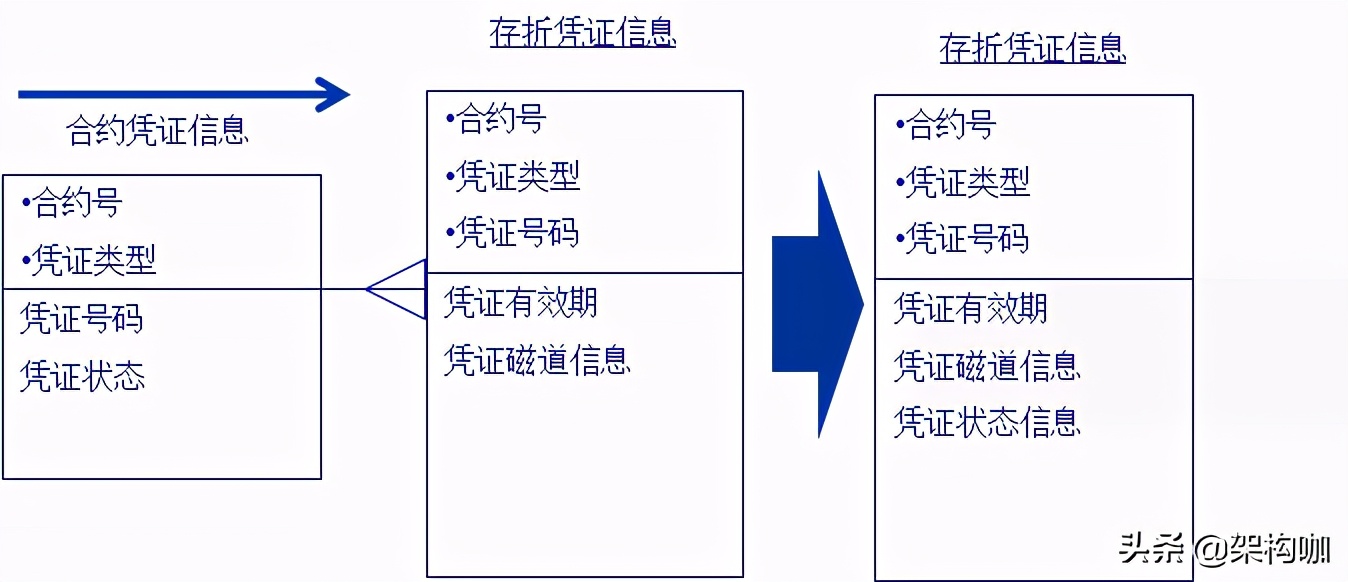
(5)实体下移
当主实体属性不多,且主实体属性不会改变的时候,则可以采用下移方法,否则将会增大数据量存储,或对维护数据的一致性造成复杂性。
(6)重复组整合
实体的重复数据是确定的,同时操作较为固定,则可以将主实体中按行存储的属性信息进行重复组组合,将公共信息进行抽取,非公共信息按照多列进行存储,对于无法一行存储的信息则可以折行存储。这样做可能会导致数据访问的复杂度增加,从而增加系统的运行效率。

2、实体分割原则
实体分割是将一个大的数据实体纵向或横向分成几个较小的数据实体。目的是减少数据实体的大小,从而提高数据访问的效率和可管理性。实体分割分为纵向分割和横向分割两种。
当实体数据量巨大,并且实体的访问逻辑都不尽相同,则可以考虑对实体进行分割;
实体分割优点:
① 根据实体访问的逻辑情况将对数据实体可能被扫描的属性信息分割出来形成新的实体,则可以提高数据访问的性能;
② 可以简化数据实体的管理,如降低数据备份、数据清理、数据恢复的成本,提高索引维护的效率。
实体分割缺点:
① 增加了物理表的数量,从而加大了数据库的管理复杂度;
② 增加了程序代码编写的复杂性,如需要根据不同的业务逻辑访问不同的数据库代码;
③ 不能使用简单的join语句进行联合查询;需要程序代码进行逻辑判断定位。
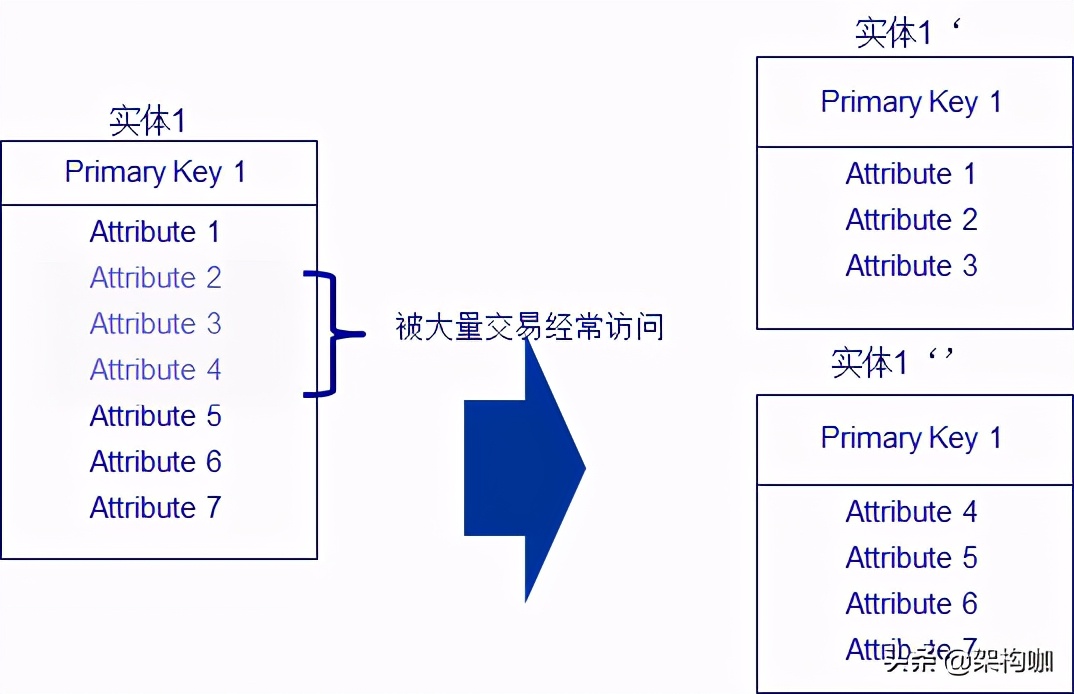
实体纵向分割
纵向分割是把一个实体拆分成两个或多个实体,每个包含一套不同的源实体的非主键属性。
当访问模式不同时,建议采用纵向分割实体的方法。
纵向分割的优点:
① 降低实体的大小:把实体中很少被使用的属性信息分割出来,从而降低实体的大小,提高
了实体的访问速度。
② 避免实体锁表:实体的属性可能被多种处理逻辑进行随机访问,从而加大了数据库锁表的
风险,当实体被分割后,则只为某一类或几类访问逻辑相似的进程访问,则避免了实体锁表
的风险,并且还能大大提高数据访问的效率。
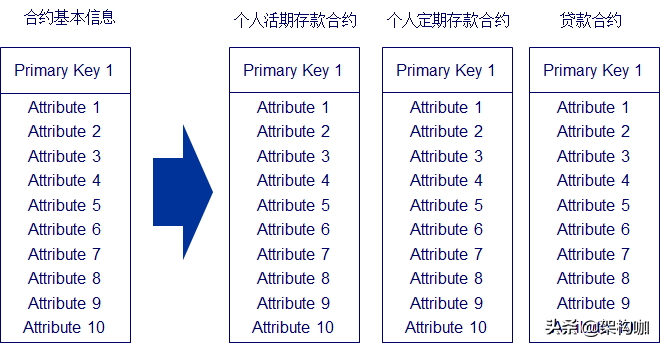
实体横向分割
“横向地”把一个实体分割成两个或多个实体,每个实体都包含源实体的所有属性信息,但基于数值的不同,每个实体会包含一套不同的数据子集,当访问范围不同时横向分割实体的方法则经常被采用。如合约基本信息按照合约类型进行横向分割,如个人活期存款合约、个人定期存款合约、个人卡服务合约、单位存款合约、贷款合约、内部合约、其他普通合约实体等。
实体横向循环分割
当一个数据实体存储大量很少使用的历史属性信息时,则可以通过横向循环分割的方法将实体按照一定的循环规则进行物理分割,从而提高应用需要快速获取数据查询结果的效率。如:合约交易明细表,可以按年进行存储,则可以将合约明细表横向分割为12张表,每个月访问一张表,当下一年时,循环使用这12张表进行数据存储。这样不仅可以提高数据访问的效率,同时也能减少数据存储压力。

3、衍生属性原则
优点:在主实体信息中创建从属实体的指示标识属性信息,作为主实体信息的衍生属性进行存在,目的是为了提高快速查询从属实体信息的效率。这对增强数据访问性能及可用性,以及对数据模型的最小化影响都是很有用的。这种原则下,当从属信息创建和删除时,只需要对主实体中的衍生信息标识进行更新即可。
缺点:但是经常变更的属性信息不建议进行衍生存储,如利率信息等,当利率发生变化则衍生信息也需要跟着变化,否则会导致数据信息不一致,从而影响数据的有效性和可靠性。
4、冗余属性原则
优点:将一个数据实体中的部分属性信息复制到另一个数据实体中,这样做的目的是为了将常用的属性信息复制到经常访问的数据实体中去,从而减少对数据实体的联合访问,缩短数据库的访问路径,大大地提高了系统的处理性能。
缺点:但是将哪些属性信息可以通过这种方案进行复制,需要根据属性内容变更的频繁度来进行考虑。如客户号相对稳定,因此可以将客户号信息存储在合约信息中;再如客户地址信息,一般情况下,每个地址信息都会分配一个地址编号,而地址编号相对稳定,地址详细信息则会经常进行变更,因此将地址详细放在合约信息中,可以提高生成对账单等处理的效率,但是变更相对频繁,反而会加大数据集成的复杂度和数据不一致的风险存在,因此不建议将地址信息存储在合约信息中。
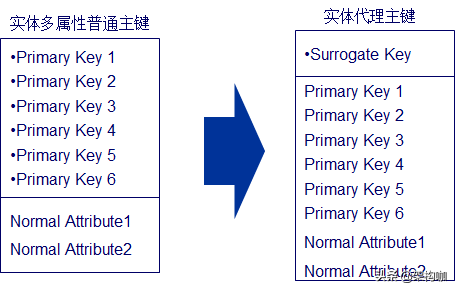
5、代理主键原则
关于实体普通主键和代理主键有很多争论,但是如果应用从不使用普通主键作为搜索条件,就像接口实体在使用时是对数据实体逐条记录进行全表扫描,则在这种情况下,只是出于建立一个唯一键值的考虑,可以使用代理主键的概念。一般情况下代理主键没有业务含义,仅用于标识。
6、属性摆放原则
 关注微信
关注微信