
Mysql数据库是目前一款非常火爆的关系型数据库。
当我们谈到关系型数据库的时候,总会谈到索引(index),在面试中也是个高频问题。
可能我们在刚刚接触数据库的时候,对于索引我们总会听说索引的优点是加快查询的速度,利用索引可以确定表中数据的唯一性,使用group by、order by等分组、排序的时候,group by、order by后面所根据的字段最好是被索引包含的字段,因为被索引包含的字段是已经排好序的了,可以减少操作时间。同时也会听说不能创建太多的索引,因为在对表的数据进行insert、update、delete操作的时候,也需要动态的维护索引。总之我们听说索引的很多优点和缺点在此就不在累述。
那么我们是否考虑过这些优缺点的依据是什么?为什么索引会有这些优缺点?
其实很简单,依据主要是数据结构中的B+tree。
那么数据库中的索引和B+tree又有什么关系???别着急,且听我慢慢道来。
首先我们创建一个数据table
CREATE TABLE `student`.`Untitled` (
`studentId` varchar(4) NOT NULL,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`age` int(255) NOT NULL,
PRIMARY KEY (`studentId`) USING BTREE,
INDEX `studentIndex`(`studentId`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
创建了一个student表,里面有三个字段学生Id、名字、年龄,其中学生Id字段添加索引,引擎类型为InnoDB。
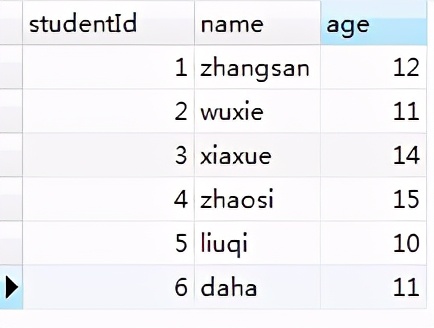
图1
现在我们添加上了索引,此时会根据索引来构建一个B+tree结构。类似下图结构:
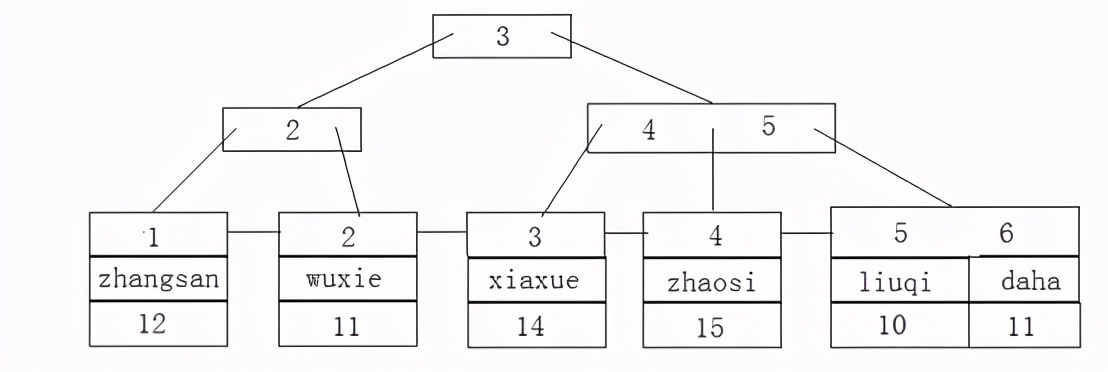
图2 B+树
当然我这里这是画了一个类似图,其实在数据量足够大的时候,树的根节点里面可以存储很多的数据,这就解决了树高度的问题(此知识点后面章节会详解),如果数据的高度小了,检索数据的次数就会相应减少。
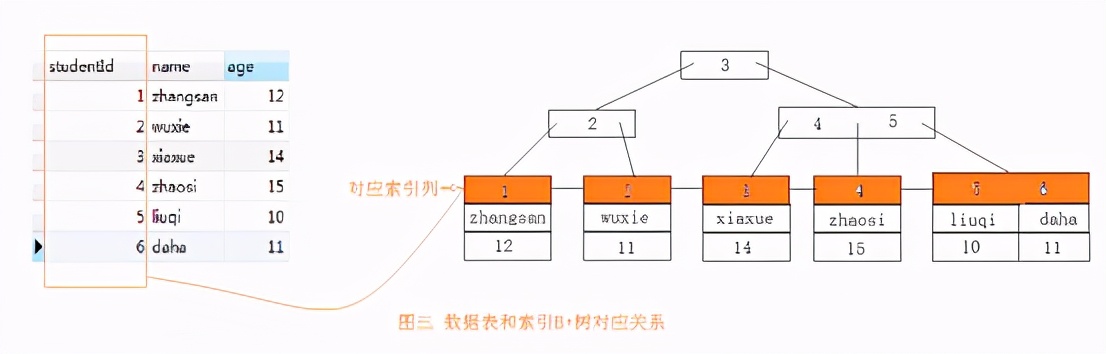
图三 数据表和索引B+树的对应图
我们通过图三就可以明白我上面所列举的索引的优缺点了。
1.当我们通过索引来查询数据的时候,例如查询studengId为6的数据,我们通过检索B+树只需要3次就能找到数据,而且树的根节点还是在内存中,检索速度很快的,但是如果不走索引,需要逐条检索信息,需要检索6次才能找到数据,因为这些数据都是存储在磁盘上的,每次检索都是一个IO,如果数据量大了,检索数据是很浪费性能的。
2.我们看图三中索引列在B+树中都是排好序的,右面叶子节点的值总是比左边叶子节点的值大(B+树的性质)。这也就解释了上面优点中排好序了。
3.当我们每次修改、删除、更新数据的时候,都会重新维护索引,其实主要就是重新构建这个B+树。
4.创建多个索引,就会生成多个B+树,每个都是需要存储的,所以不建议创建太多的索引。
所以我们平时看到的索引优缺点都是主要围绕着这个B+树结构来解释的。
后续关于索引的深度内容将继续更新,只有懂得了索引,才可能对sql进行高效的优化。
 关注微信
关注微信