

检索(Crawl ) 与索引( Index )是SEO领域里面非常非常基本的两个观念,是在学习SEO之前一定要理解的基本观念,但检索以及索引的优化概念很大,只透过一篇文章我可能没有办法完整的讲完,因此这篇文章我只会针对基础的概念先进行解说,并且在文章中连结到我曾经写过的相关文章来帮助你学习: )
Google也有提供官方很多的HTML语法给网站经营者,透过这些语法以及HTML标记你可以优化搜寻引擎的爬虫如何检索、理解你的网站,不过每一种语法的功能不同,因此每一种语法我会以独立的文章来撰写,像是:
三分钟搞懂SEO的《meta robots、robots.txt》
认识SEO排名的杀手,『重复内容』超完整攻略
(重复内容文章内提到的Canonical标记便是一种常用到的SEO标记)
认识SEO的Title Tag(标题标记)
但在阅读上述这些文章之前,建议还是必须要先看完这篇文章,确保自己已经有检索(Crawl )以及索引(Index) 的概念。
网路爬虫这个说法比较抽象,Google官方将它称为Google Spider、Google Bot,你可以把整个世界的网路想像为一个巨大蜘蛛网,而搜寻引擎本身有属于它的一只爬虫程式,这支程式会像蜘蛛一样在这巨大的网路上爬行,并收集资讯。
做SEO工作,维持搜寻引擎爬虫与网站之间良好的关系是非常重要的,我们必须要尽量让它能够完整爬取你网站上的优质内容,否则会对你的网站SEO有影响(在这篇文章中我会慢慢提到),而搜寻引擎运作原理我们可以简单分为三个阶段:
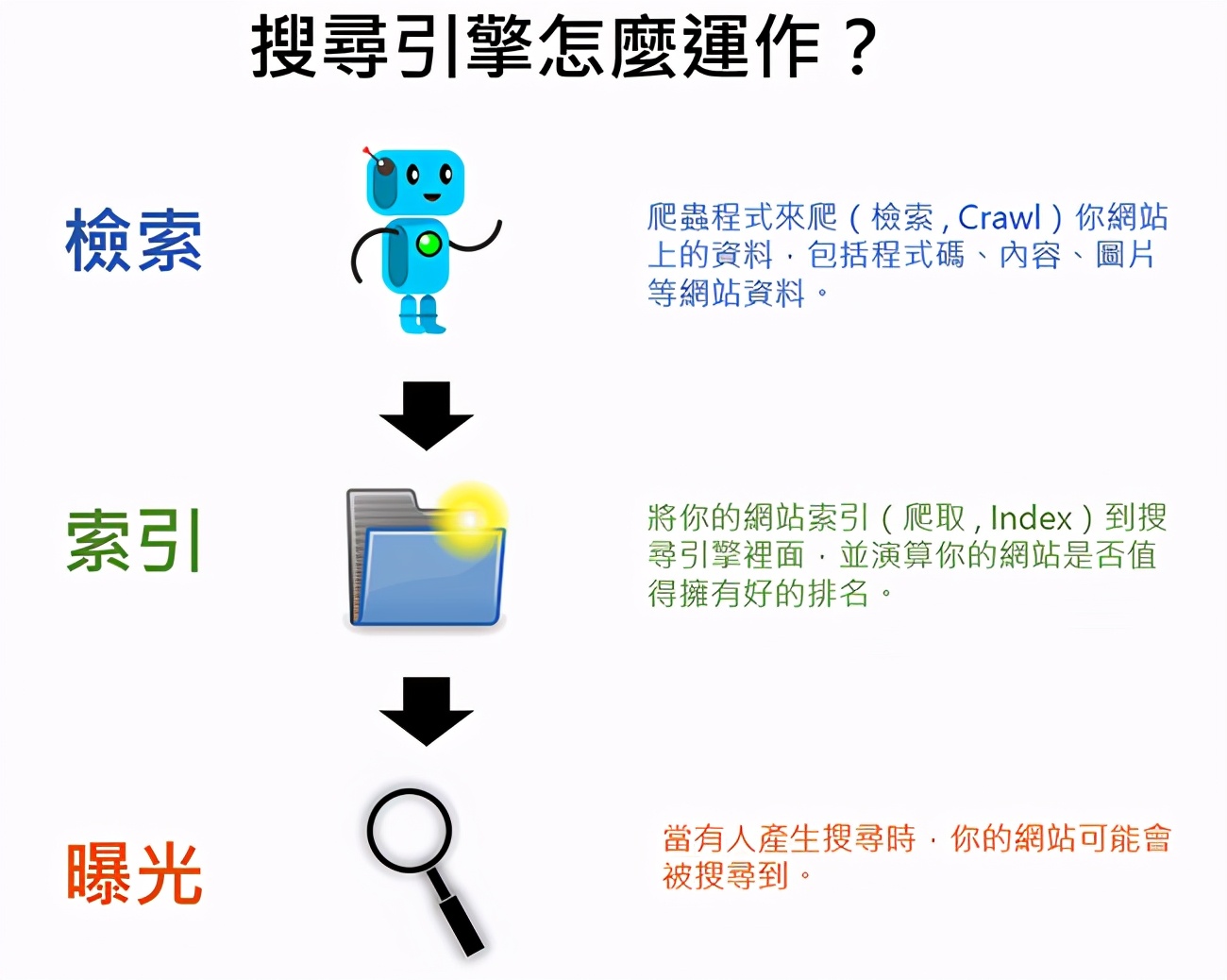
阶段1 –检索(爬取):搜寻引擎的爬虫来你的网站上爬取、下载网站资料的这个动作我们叫做检索,在Google官方的文件上正式的专有名词叫做『检索』,但SEO业界比较习惯白话一点来称呼,通常我们会称呼为爬取、抓取等比较白话的用词。这个阶段Google的爬虫会在你的网站上爬取所有能爬到的资料,包含你的网页内容、程式码、图片等所有的网页资讯。
阶段2 –索引(收录):将你的网页资料收录、建档到搜寻引擎里面的这个动作我们叫做索引(白话一点来说就是收录的意思),但你的网站就算被收录到搜寻引擎里面也不代表你会得到很可观的搜寻流量,Google也许愿意收录你的网站,但未必愿意给你的网站很好的搜寻排名(取决于你的网站是否是一个优质的网站、是否有被很好的优化,否则Google也许愿意收录网站,但不愿意让你的网站很常被搜寻到)很多人以为网站没有搜寻流量就代表没有被Google收录,其实这观念是不对的,『是否有被收录』、 『是否有排名有流量』是两件事。但至少被Google收录进搜寻引擎是好的第一步,如果Google连收录你的网站都不愿意,那更不用谈搜寻流量以及SEO了。
阶段3 –曝光在搜寻结果:搜寻者查询关键字时,你的网站可能会被Google提供给搜寻者,而你的品牌也会因此获得搜寻流量(但这取决于你的网站是否是一个优质的网站、是否有做SEO)。
实务上我们在学习SEO时,会碰到很多网路上的文章主题都是环绕在所谓的"排名因素",也就是你的网站该如何做才能被Google排名被搜寻结果的前面名次,但实务上一个网站会面临到的SEO问题有很多面向,根据网站的架构、网站的产业、所在的市场等不同的因素而定,并不是只要优化"排名因素"就够了,Google如果没办法很健康的爬取你的网站资料,那么网站的排名因素优化做再好都没用,因为他的爬虫根本看不到你网站里面的资料,所以你要了解搜寻引擎的爬虫到底是怎么检索(爬取资料),然后又是怎么索引(收录)网站。
举例来说,在我们实务上常常遇到有客户的网站是使用AJAX程式建构出动态式的瀑布流,在你进入网站时会看到四则文章连结,接着你滑鼠向下卷动时,程式则会触发并出现后面四则(简单来说就是Facebook 现在的做法,俗称瀑布流),通常这个状况底下Google的爬虫只会爬取到一开始的前面几则文章而已,因为网路爬虫不会像人类使用者去往下卷动并触发AJAX程式的瀑布流。在这类案例之下,Google的爬虫看到的网页资讯很少,当然也很伤害你的SEO(不管你的网站再棒、再好,只要Google的爬虫看不到,那么根本没有意义)。
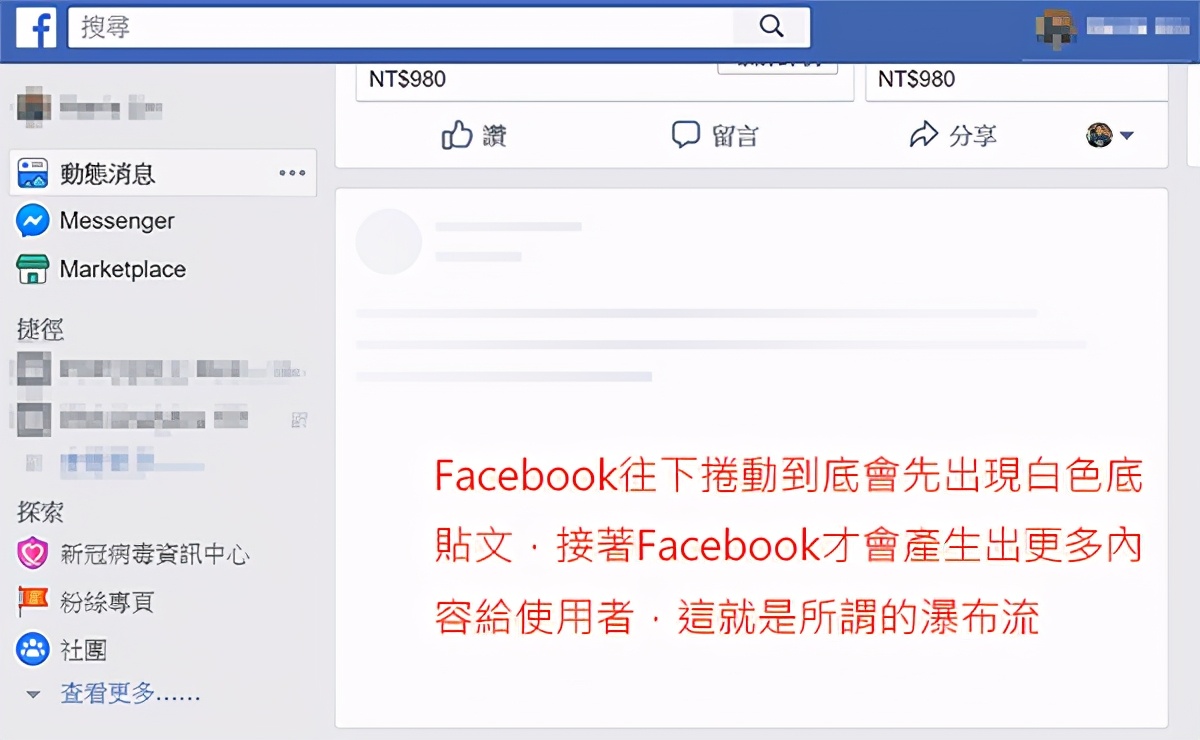
因此作为SEOer,研究、了解爬虫的效能是很重要的,我们必须要了解搜寻引擎的爬虫有哪些效能限制、哪些网页技术是爬虫无法好好的爬取(像瀑布流就是大多情况没办法被搜寻爬虫很有效的爬到资料),而Google的爬虫、Bing/Yahoo搜寻引擎的爬虫由各自是不同的团队/公司所开发出来,因此他们的爬虫效能又有些不一样,如果做SEO时希望除了Google之外的Yahoo/Bing也可以优化好,那么就要全部都花时间去研究。
这个议题有很多面向可以谈论,在这篇我先谈一些基础观念以及方法。
首先,大部分的情况只要你的网站被Google很健康的『爬取』,收录状况就不太会有问题,通常如果Google有很健康的检索你的网站但却没有收录你的网站,那代表你的网站可能有违规、用作弊的方法做SEO而遭到Google惩处(除了违规惩处之外,很少有网站是检索都没问题,但Google却不愿意收录你的网站)。
那么,要如何检查Google是否有健康的爬取(检索)你的网站呢?常见的方法之一就是透过Search Console的报表(如下图范例)。
(如果你还不知道什么是Search Console,可以参考这篇Search Console新手教学)
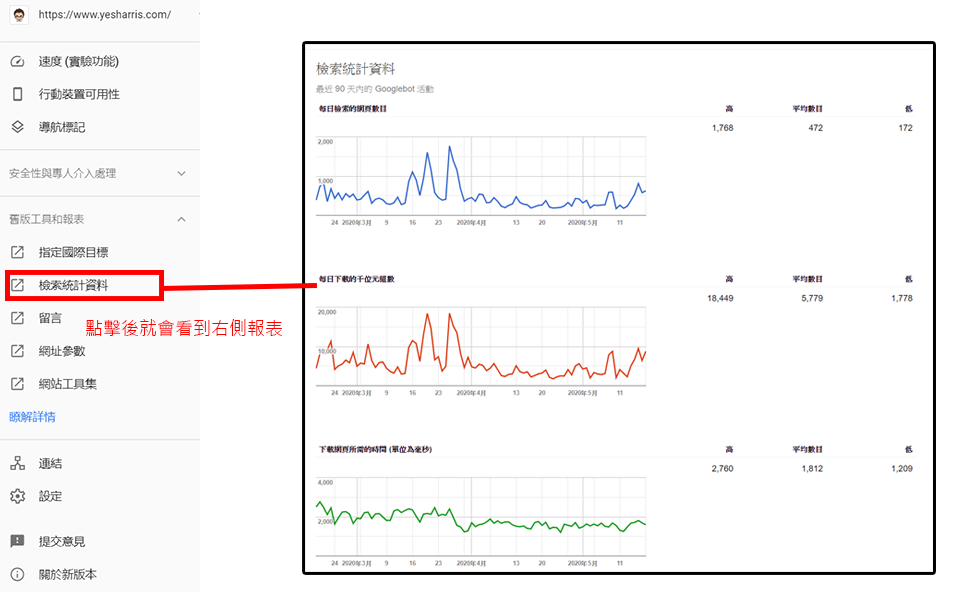
这张报表最上方的蓝色趋势图是"每日检索的网页数目",这张图表代表着Google"每天来爬你的网站时,都爬了多少个网页",通常图表会在一个区间范围内波动,大多情况Google每天来爬多少网页取决于三件事情:
1. 你的网站在市场上有多重要、网站的SEO权重有多高(也就是所谓的Crawl Budget)
2. 你的网站架构是否有使用不利于爬虫的技术,导致爬虫不容易爬到资料
3.你是否有主动阻挡Google爬你的网站(阻挡Google的部分可以阅读非技术人员也能看懂的《meta robots、robots.txt》)
上述报表可以帮你检查Google是否有健康的"爬取"你的网站,通常如果Google爬你网页的数字与你的网站落差太大,对SEO都是不太好的,比方说你的网站共有8,000个网页,但Google每天来爬你的网站却只有爬50页~100页左右,如果你的网站有8,000页,Google每天爬的网页数最好在500~1,000之间是比较正常的。
但"索引"呢?要如何检查Google有健康的索引我的网站呢?这部分你可以阅读我的学习使用Site指令,诊断《 Google索引》状况,里面有很完整的教学。
撇除你有违规、作弊的行为发生而导致Google不愿意好好的处理你的网站,以下有几个常见的优化项目,也是我们通常在担任SEO顾问时会检查的优化项目:
虽然说Google近年来宣称搜寻引擎现在已经能够满有效的解析JavaScript、AJAX技术,但实务上还是有很多网站的JavaScript、AJAX没办法被Google很有效的解析(这篇文章中提到的瀑布流就是AJAX的一种应用),因此尽可能避免在导览列、面包屑、网站侧栏、商品/文章列表这些重要的地方使用JavaScript以及AJAX会比较保险(在这篇文章我先列出几个大方向的常见重点,未来我会在看大家回馈状况各自拉出来写成独立的文章,JavaScript与AJAX这个议题有太多层面要探讨,但简单总结的话就是不要太过度使用AJAX)。
根据Google官方的说明,Google针对每一个网站有所谓的"爬取额度(Crawl Budget)",也就是说他在爬你的网站时只会给予你一定的时间额度,因此你必须要尽可能的优化网站速度,让爬虫在最短的时间内可以爬到尽可能多的网站,而这个爬取的额度会根据你的网站在市场上的重要性、以及SEO的网站权重而定。
举例来说,Google决定给你的网站每天10分钟的额度,那么他每天只会来爬你的网站10分钟,并且10分钟一到他就会离开网站,因此,如果你的网站速度尽可能优化到好,可以帮助他在同样的10分钟内爬完你的网页,概念上简单来说是这样:
当你的网站速度很慢时,他10分钟只能爬完100个网页。
当你的网站速度够快时,他可以在10分钟内爬完500页。
以上述情况来说,你SEO成效的差距就出来了,我们会希望Google在同样的时间内可以爬越多网页越好,Google如果连爬你的网站都不能好好的爬,基本上成效当然不好。
针对网站速度优化的部分,你可以参考这篇来获得更多知识:超重要的SEO优化项目:『网站速度』优化
重复内容问题要尽量避免(尤其是网址参数所产生的重复内容),重复内容会让爬虫要去爬更多无效的网页(如果你不知道什么是重复内容,我在重复内容这篇文章有完整的解说),简单来说,如果你的网页总共有500页,但你有很严重的重复内容问题而导致网页膨胀到了1,200页,那么当中有700页的网页会浪费掉爬虫的爬取额度,毕竟爬虫每天能爬的网页是很有限的。
如果你有很多损毁/坏掉的网页,或是网站上有很多不必要的、很胡乱的转址可能都会影响爬虫爬你网站的效能以及额度,因此在经营网站时一些最基础的事情你必须要尽量避免,像是:
 关注微信
关注微信