
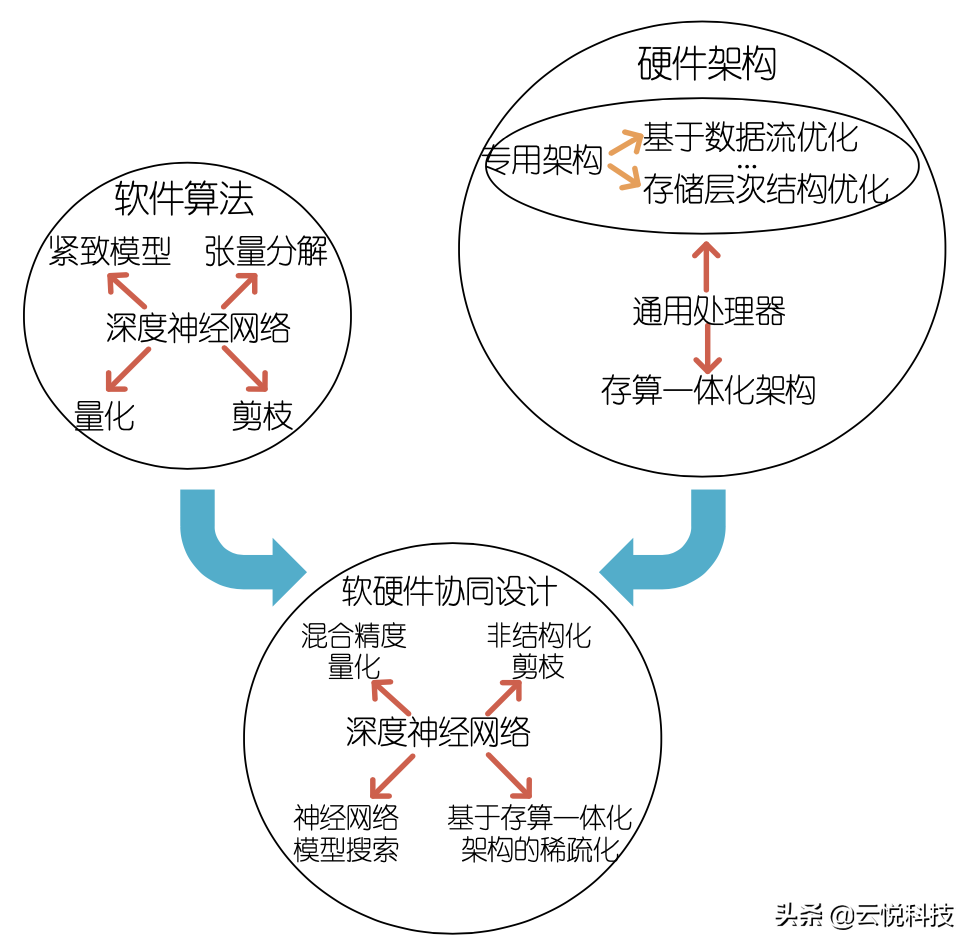
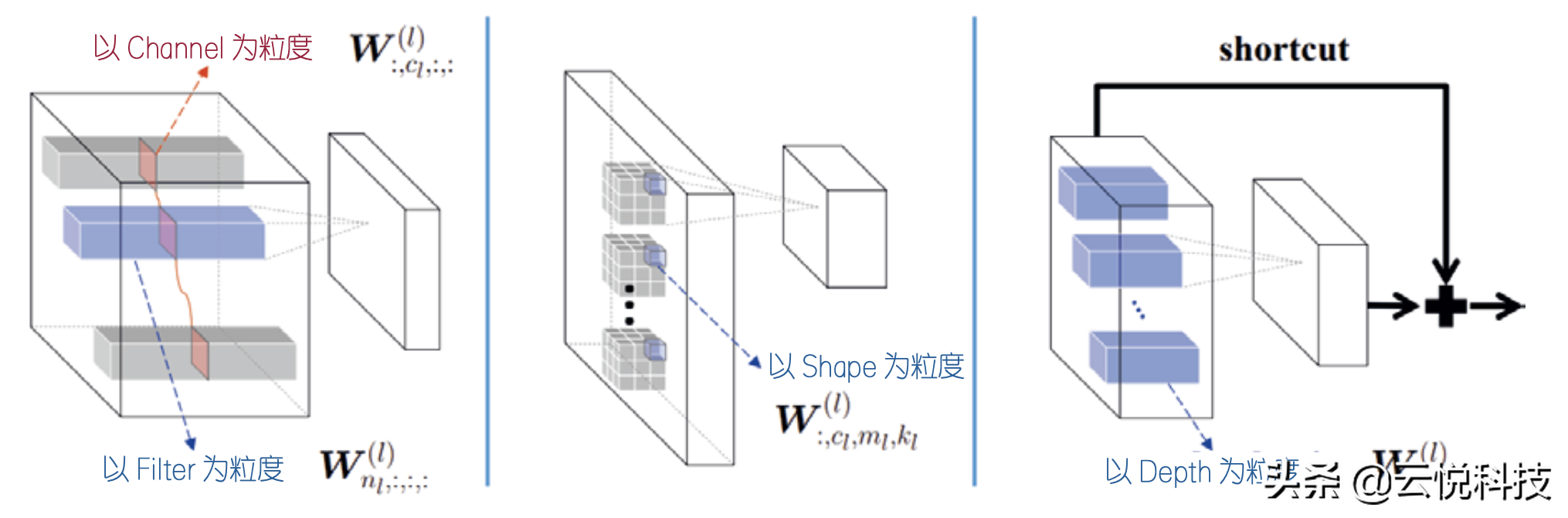
神经网络压缩技术最重要的是设计抽象层次上的发展,遵循软件算法-硬件架构-软硬件协同设计的轨迹。从软件算法角度来看,压缩深度神经网络模型一直是AI领域的一个重点研究问题。一方面,用一些新的学习表征、模型结构和学习方法,生成一个稀疏性极低的紧致神经网络模型,降低对计算能力和访存的需求。另一方面,通过修改已有的神经网络模型挤压其稀疏性。方法主要包括以下3种。(1)张量分解算法:通过满秩分解、SVD分解等方法将张量降秩;(2)结构化剪枝算法:以通道、矩阵等模型结构为粒度减少神经网络中冗余权值的数量;(3)固定位宽量化算法:统一降低神经网络模型权值参数的表达位宽。业界往往通过耦合上述多项算法以实现更高的模型压缩率。值得一提的是,这些算法可以在GPU等通用处理器上取得明显的计算性能提升。图4展示了结构化剪枝算法,以Channel、Filter、Shape等网络结构为粒度对神经网络的权重剪枝,保证了剪枝粒度大于GPU并行调度粒度(即线程组宽度),从而有效提升了GPU的执行效率。然而,若要进一步提升压缩算法的效率,如更细的剪枝粒度、更灵活的位宽设置,就不得不对硬件架构进行深度定制。这不仅增加了架构设计的复杂度,还降低了架构的灵活性,难以在模型的准确率与压缩率之间取得最佳平衡。
设计抽象层次发展脉络
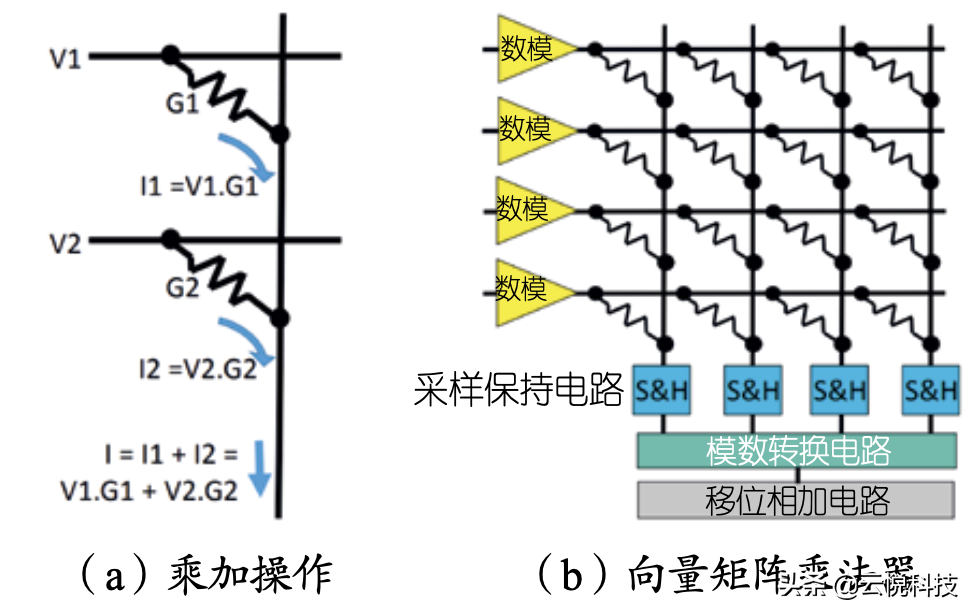
从硬件架构角度来看,神经网络的执行效率与底层架构设计息息相关。DNN专用架构的优化主要针对访存,包括(1)数据流优化:通过优化DNN计算通路中的数据流,提高数据的可复用性,减少DDR的访存请求;(2)存储层次结构优化:根据神经网络中数据访问的局部性(尤其是卷积运算深层嵌套的LOOP循环),将加速器中的存储结构分级,提高神经网络的访存速度;(3)存算一体化架构设计:以各种传统工艺(如SRAM、NorFlash)或新型忆阻器工艺(如FeRAM、ReRAM、PCM和MRAM)制作器件构建存储阵列,将神经网络权值参数直接存储在阵列内部,并以模拟信号的形式并行执行大规模矩阵乘法。以典型的存算一体化硬件架构为例,向量以电压形式驱动阵列字线(行),利用电压乘以电导(按照DNN的权值对忆阻器阻值进行编程)等于电流,并且电流在位线(列)自然汇聚相加的电流定律,一次读操作即可完成向量与矩阵的乘加操作。这种方法不但提高了矩阵乘法的并行度,而且避免了反复从DDR读取DNN的权重,进一步提高了架构的能效比。然而,单纯从硬件架构中挖掘并行性和数据可复用性,能效比很快就到达极致,性能提升将会遇到瓶颈。
结构化剪枝算法
软件算法与硬件架构融合,通过更高的灵活性来获取更高的DNN压缩率成为了历史的选择。软硬件协同设计主要从以下几个角度考虑。(1)混合精度量化:使用不同的、混合的数据位宽来表示同一神经网络中的不同数据,并辅以专用加速器架构设计,以获取更高的性能收益;(2)非结构化剪枝:删除DNN中不重要的、冗余的权重(不一定非要按照某种结构删除),最大程度地挖掘DNN的稀疏性,通过专用的跳零架构4加速神经网络的推理过程;(3)硬件导向的DNN架构搜索:分析底层专用架构的特点,设计DNN模型搜索机制,搜索出一个适用于当前架构、执行效率极高的DNN架构(如层数,卷积核大小、通道数及连接,数据位宽等);(4)基于存算一体架构的稀疏方案:存算一体化架构的执行单元通常以阵列的形式组织,非结构化剪枝产生随机分布的零,难以通过编码压缩部署在阵列上。存储权重的忆阻器件同时参与计算流,这种操作数与运算器的硬件耦合导致无法实现跳零架构。因此我们主要以规则的行、列以及块的规则形状剪枝或量化DNN模型。
存算一体化架构
未来,抽象层次上的软硬件协同设计将向更深更广的方向发展。(1)更广的任务场景,比如删除冗余令牌(token)的Transformer加速架构,面向视频时域上的稀疏性、三维点云空间稀疏性和图神经网络关系稀疏性进行压缩的软硬件协同设计。(2)从单芯片的软硬件协同拓展到异构计算架构和系统的软硬件优化。比如谷歌的万亿参数的语言模型稀疏。(3)基于模拟运算的存算一体化架构和脉冲神经网络加速器架构。
 关注微信
关注微信