
从菜市场买来的菜,总有一些是坏掉的不太好的,所以把菜买回来之后要做一遍预处理,也就是把那些坏掉的不太好的部分扔掉。现实中大部分的数据都类似于菜市场的菜品,拿到手以后会有一些不好的数据,所以都要先做一次预处理。
常见的不规则数据主要有缺失数据、重复数据、异常数据几种,在开始正式的数据分析之前,我们需要先把这些不太规整的数据处理掉,做数据预处理。
一、缺失值处理
缺失值就是由某些原因导致部分数据是空的,对于为空的这部分数据我们一般是有两种处理方式的,一种是做删除处理,即把含有缺失值的数据删除;另一种是做填充处理,即把缺失的那部分数据用某个值代替。
1、缺失值查看
对缺失值进行处理,首先要把数据中的缺失值找出来,也就是查看数据中有哪些列有缺失值。
(1)、Excel实现
在Excel中我们选中一列没有缺失值的数据,看一下这一列数据共有多少个,然后把其他列的计数与这一列进行做对比,小于这一列数据个数的就代表该列数据有缺失值,差值就是缺失个数。
下图中非缺失值列的数据计数为5,性别这一列计数为4,这就表示性别这一列是有一个缺失值的。
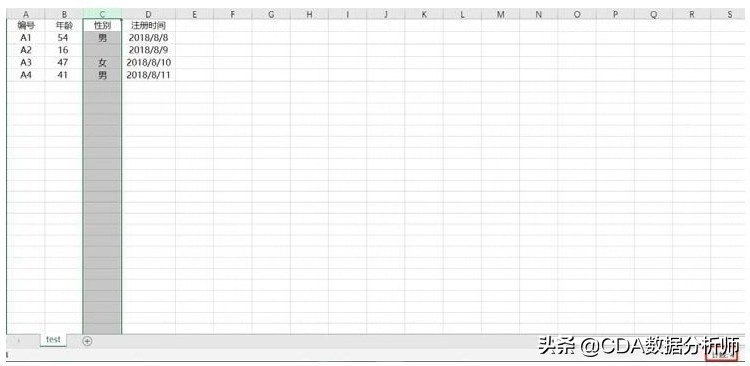
如果想要看整个数据表中每列数据的缺失情况,则要挨个选中数据中每一列去判断该列是否有缺失值。
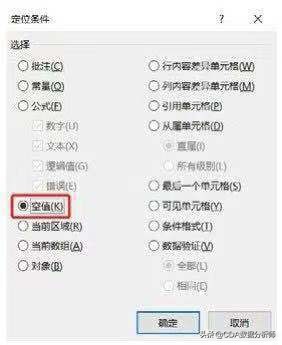
如果数据不是特别多,你想看数据中具体是哪个单元格的缺失,则可以利用定位条件(按快捷键Ctrl+G可弹出对话框)查找。在定位条件对话框中选择空值,单击确定就会把所有的空值选中,如下图所示:
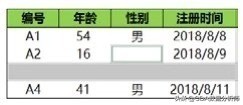
通过定位条件把数据中缺失值选出来的结果,如下图所示:
(2)Python实现
在Python中直接调用info ( ) 函数的方法就会返回每一列的缺失情况。关于info ( ) 函数方法我们在之前就用过,但是没有说明这个方法可以判断数据的缺失情况。
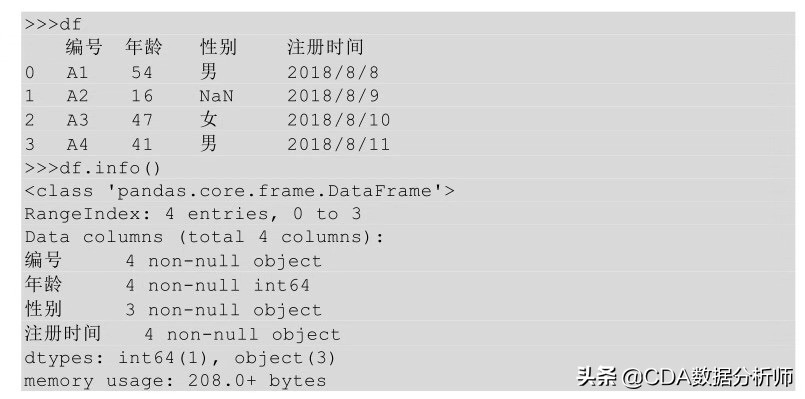
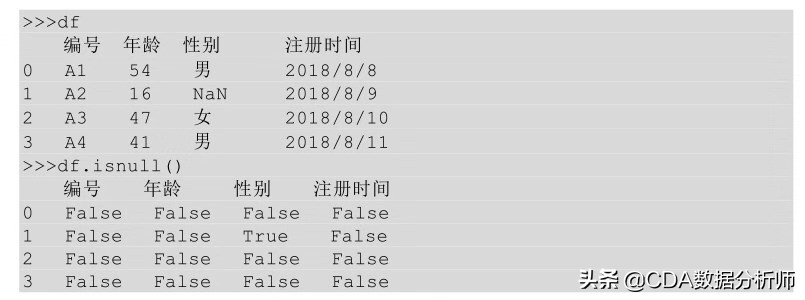
Pythoy中缺失值一般用NaN表示,从用info ( ) 方法的结果来看,数据中性别这一列是3 non-null object,表示性别这一列有3个非null值,而其他列有4个非null值,说明性别这一列有1个null值。
我们在python中还可以用isnull ( ) 方法来判断哪个值是缺失值,如果是缺失值则返回True,一行中如果不是缺失值则返回False。
2、缺失值删除
缺失值分为两种,第一种是一行中某个字段是缺失值;另一种是一行中的字段全部为缺失值,即为一个空白行。
(1)Excel实现
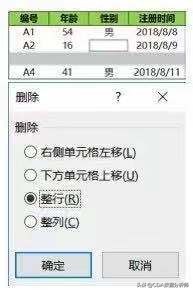
在Excel中,这两种缺失值都可以通过定位条件(按快捷键Ctrl+G可弹出该对话框),对话框中选择空值就可以找到。
这样含有缺失值的部分数据就会被选中,包括某个具体的单元格及一整行,然后单击鼠标右键在弹出的删除对话框中选择删除整行选项,并单击确定按钮即可实现整行的删除。
(2)Python实现
在Python中,我们利用的是函数dropna ( ) 方法,函数dropna ( ) 方法默认删除含有缺失值的行,也就是只要某一行有缺失值就把这一行删除。
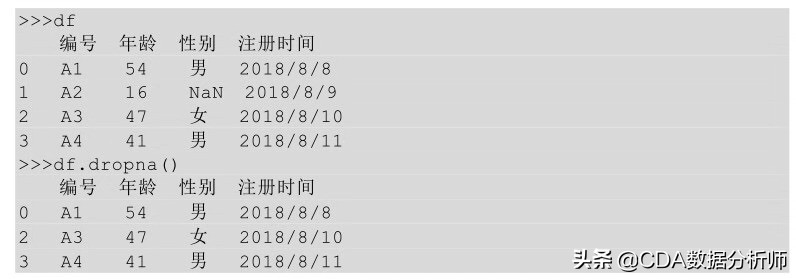
运行函数dropna ( ) 方法以后,删除含有NaN值的行,返回删除后的数据。
如果想删除空白行,只要给函数dropna ( ) 方法传入一个参数 how = all 即可,这样就会只删除那些全为空值的行,不全为空值的行就不会被删除。


上表第二行中只有性别这个字段是空值,所以在利用函数dropna( how = “all” )的时候并没有删除第二行,只是把全为NaN值的第三行删掉了。
3、缺失值的填充
上面介绍了数据处理缺失值删除的方法,但是数据是宝贵的,一般情况下只要数据缺失比例不是过高(不大于30%),尽量还是不要做删除处理,而是选择做填充。
(1)Excel实现
在Excel中,缺失值的填充和缺失值删除一样,利用的也是定位条件,先把缺失值找到,然后在第一个缺失值的单元格中输入要填充的值,最常用的就是用0填充,输入以后按Ctrl+Enter组合键就可以对所有缺失值进行填充处理。
缺失值填充前后的对比如下图所示:
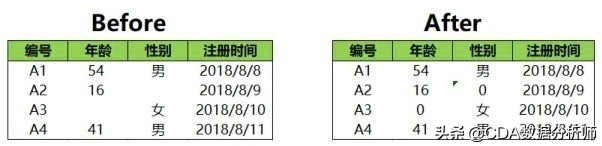
在数据中年龄用数字填充合适,但是性别用数字填充就不太合适,那么可不可以分开填充呢?答案是可以的,选中想要被填充的那一列,按照填充全部数据的方式进行填充就可以了,只不过如果想要要填充几列,则需要执行几次这样的操作。
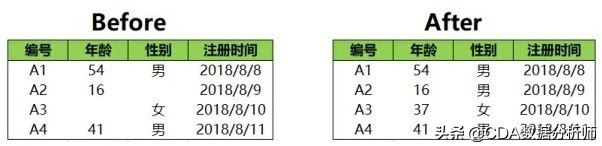
上图是数据填充前后的对比,年龄这一列我们使用平均值进行填充,性别这一列我们使用众数进行填充。
除了用0填充、平均值填充、众数(大多数)填充,还有向前填充(即用缺失值的前一个非缺失值填充,比如上个例子中编号A3 对应的缺失年龄的前一个非缺失值就是16)、向后填充(与向前填充对应)等方式。
(2)Python实现
在Python中,我们利用的 fillna ( ) 方法对数据表中的所有缺失值进行填充,在fillna ( )后面的括号中输入要填充的值即可。
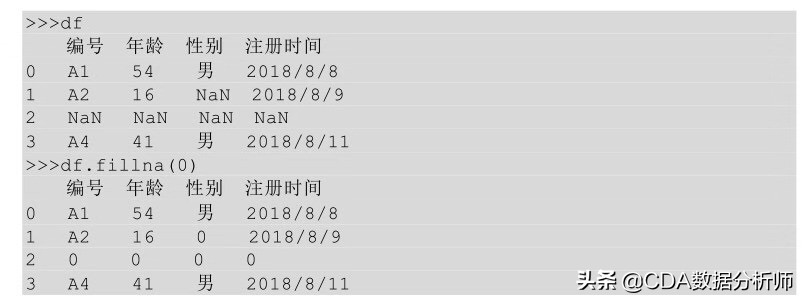
在Python中我们也可以按不同列进行填充,只要在函数fillna ( ) 方法的括号中指明列名即可。
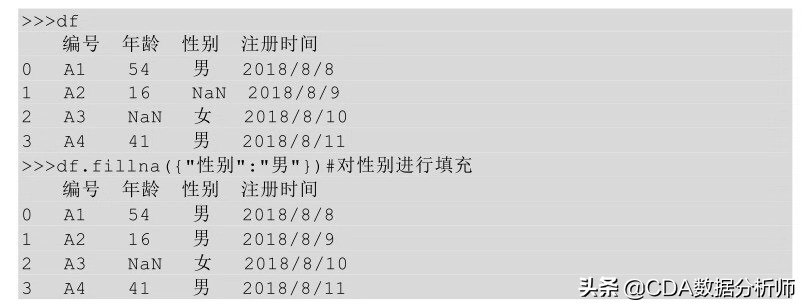
上面的代码中只针对性别这一列进行了填充处理,数据中其他列均未进行任何更改。
也可以同时对多个列填充不同的值:

二、重复值处理
重复数据就是同样的记录有多条,对于这样的数据我们一般做删除处理。
假设你是一名数据分析师,你的主要工作是分析你所在公司的销售情况,现有公司2018年8月的销售明细(已知一条明细对应一笔成交记录信息),你想看一下2018年8月公司整体成交量是多少,最简单的方式就是看一下这个月有多少条成交明细。但是这里可能会有重复的成交记录存在,所以要先做删除重复项的处理。
(1)Excel实现
在Excel中依次单击菜单栏中的数据>数据工具>删除重复值,就可以删除重复数据了,如下图所示:

数据删除前后的对比图如下:
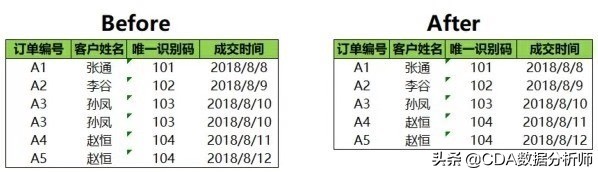
Excel的删除重复值默认是针对所有值进行重复值判断,比如数据中有订单编号、客户姓名、唯一识别码(类似于身份证号的字段)、成交时间这四个字段,Excel会判断这四个字段是否都是相等的,只有都相等时才会做删除处理,并且会保留第一个值(第一行值)。
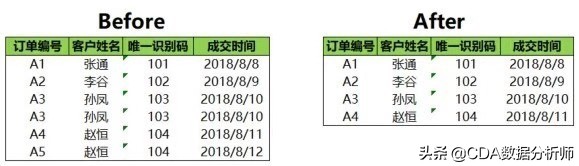
你知道了公司2018年8月份成交明细以后,你想看一下2018年8月份总共有多少成交客户,且每个客户在2018年8月份首次成交的日期。
查看客户数量只需要按客户的唯一识别码进行去重就可以了。Excel默认是全选,我们可以取消全选,选择唯一识别码进行去重,这样只要唯一识别码重复就会被删除,如下图所示:
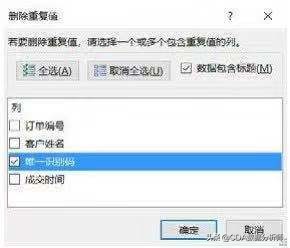
因为Excel默认会保留第一条记录,而我们又想获取每个客户较早成交日期,所以我们需要先对时间进行升序排序,让较早的日期排在前面。这样在删除的时候就会保留较早的成交日期。
删除前后的对比如下图所示:
(2)Python实现
在Python中我们利用drop_duplicates ( ) 方法,该方法默认对所有值进行重复值判断,且默认保留第一个值(或第一行值)。
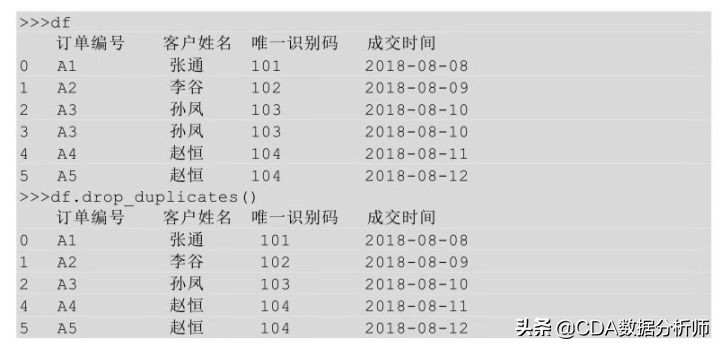
上面的代码是针对所有字段进行的重复值判断,我们同样也可以只针对某一列或某几列进行重复值删除的判断,只需要在drop_duplicates ( ) 方法中指明要判断的列名即可。
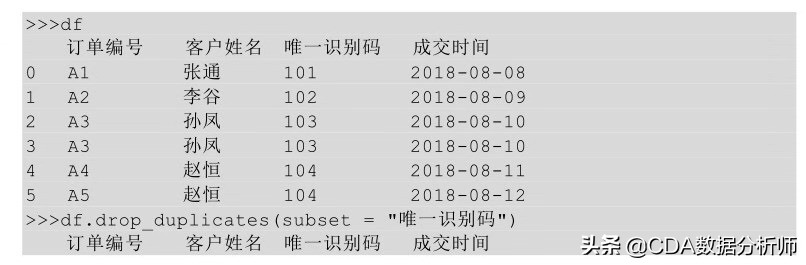

也可以利用多列去重,只需要把多个列名以列表的形式传给参数subset即可。比如按姓名和唯一识别码去重。

还可以定义删除重复项时要保留哪个,默认是保留第一个,也可以默认保留最后一个,或者全部不保留。通过传入参数keep进行设置,参数keep默认值是first,即保留第一个值;也可以是last,保留最后一个值;还可以是False,即把重复值全部去掉。
三、异常值的检测与处理
异常值就是相比正常数据而言过高或者过低的数据,比如一个人的年龄是0岁或者100岁都算是一个异常值,因为这和实际情况差距过大。
1、异常值检测
要处理异常值首先要检测,也就是发现异常值,发现异常值的方式主要有以下三种:
■根据业务经验划定不同指标的正常范围,超过该范围的值就可以算为异常值
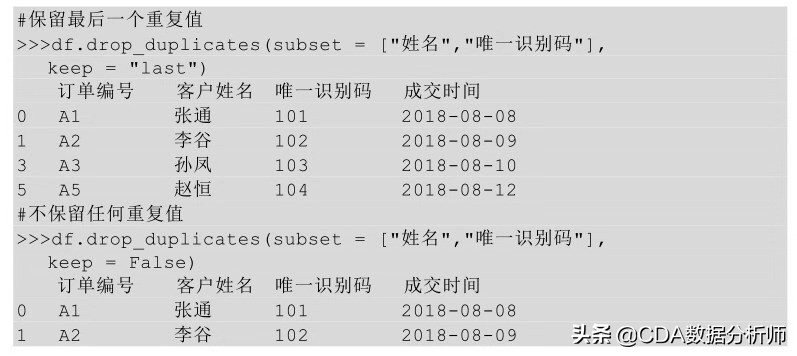
■通过绘制箱型图,把大于(小于)箱型图上边缘(下边缘)的点称为异常值
■如果数据服从正太分布,则可以利用3σ 原则;如果一个数值与平均值之间的偏差超过3倍标准差,那么我们就认为这个值是异常值。
箱形图如下图所示:
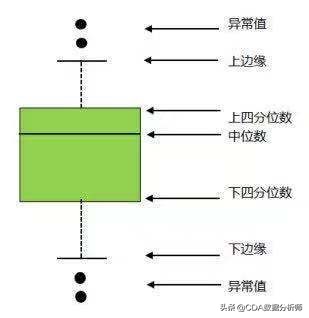
下图是正态分布图,我们把大于μ+3σ的值称为异常值。
2、异常值处理
对于异常值一般有以下几种处理方式:
■最常用的处理方式就是删除
■把异常值当做缺失值来填充
■把异常值当做特殊情况,研究异常值出现的原因
(1)Excel实现
在Excel中,删除异常值只要通过筛选就把异常值对应的行找出来,然后单击鼠标右键选择删除行即可。
对异常值进行填充,其实就是对异常值进行替换,同样通过筛选的功能把异常值先找出来,然后把这些异常值替换成要填充的值即可。
(2)Python实现
在Python中,删除异常值用到的方法和Excel中的方法原理类似,Python中是通过过滤的方法对异常值进行删除。比如 df 表中有年龄这个指标,要把年龄大于200的值删掉,你可以通过筛选把年龄不大于200的筛出来,筛出来的部分就是删除大于200的值以后的新表。
对异常值进行填充,就是对异常值进行替换,利用 replace ( ) 方法可以对特定的值进行替换。
四、数据类型转换
1、数据类型
(1)Excel实现
在Excel中常用的数据类型就是在菜单栏中数字选项下面的几种,你也可以选择其他数据格式,如下图所示。
在Excel中只要选中某一列就可以在菜单栏看到这一列的数据类型。
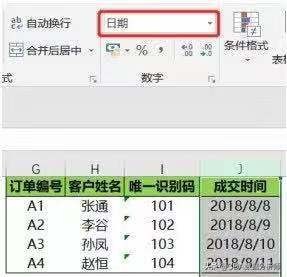
当选中成交时间这一列时,菜单栏中就会显示日期,表示成交时间这一列的数据类型是日期格式,如下图所示。
(2)Python实现
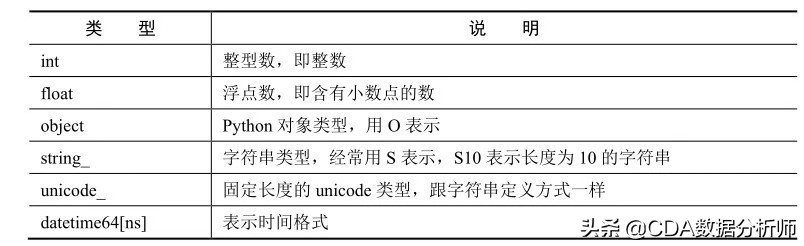
Pandas不像Excel分得那么详细,它主要有6种数据类型,如下表所示。
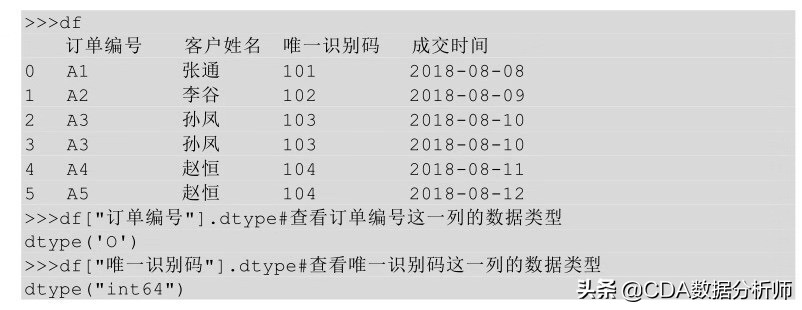
在 Python 中,不仅可以用 info ( ) 方法获取每一列的数据类型,还可以通过 dtype方法来获取某一列的数据类型。
2、类型转换
我们在前面说过,不同数据类型的数据可以做的事情是不一样的,所以我们需要对数据进行类型转化,把数据转换为我们需要的类型。
(1)Excel实现
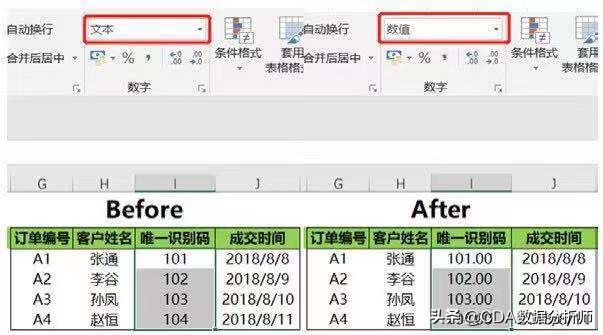
在Excel中如果想更改某一列的数据类型,只要选中这一列,然后在数字菜单栏中通过下拉菜单选择你要转换的目标类型即可实现。
下图就是将文本类型的数据转换成数值类型的数据,数值类型数据默认为两位小数,也可以设置成其他位数。
(2)Python实现
在Python中 ,我们利用astype ( ) 方法对数据类型进行转换,astype ( ) 后面的括号里指明要转换的目标类型即可。
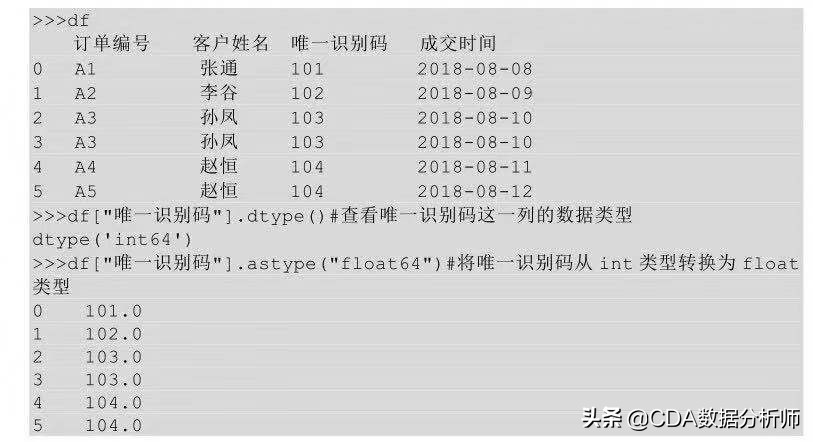
五、索引设置
索引是查找数据的依据,设置索引的目的是便于我们查找数据。举个例子,你逛超市买了很多食材,回到家以后你要把这些食材全部放在冰箱里,放置在冰箱的过程其实就是一个建立索引的过程,比如蔬菜放在冷藏室,肉类放在冷冻室,进行完这样的分类存放之后,这样再找的时候就可以很快的找到。
1、为无索引的表添加索引
有的表没有索引,这时要给这类表加一个索引。
(1)Excel实现
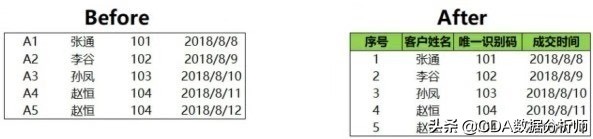
在Excel中,一般都是有索引的,如果没索引数据看起来会很乱,当然也会有例外,数据表就是没有索引的。这个时候插入一行一列就是为表添加索引。
添加索引前后的对比如下图所示,序号列为行索引,字段名称为列索引。
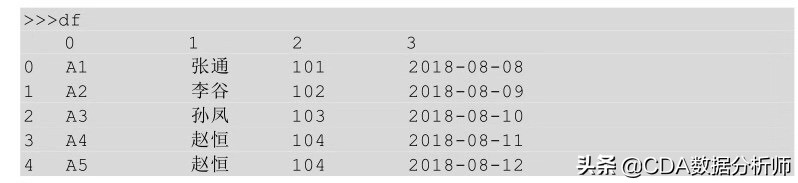
(2)Python实现
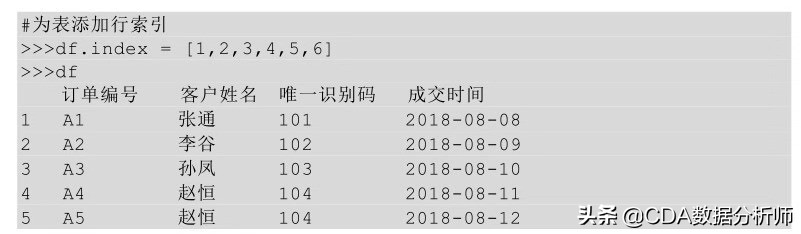
在Python中,如果表没有索引,会默认用从0开始的自然数做索引,比如下面这样:
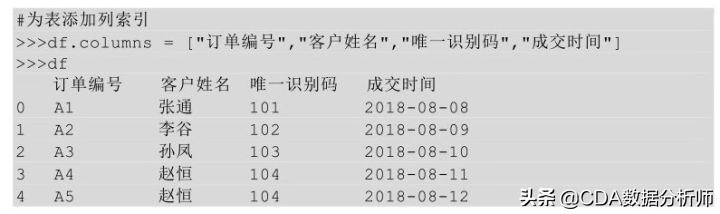
通过给表df的columns参数传入列索引值,index参数传入行索引值达到为无索引表添加索引的目的,具体实现如下:
2、重新设置索引
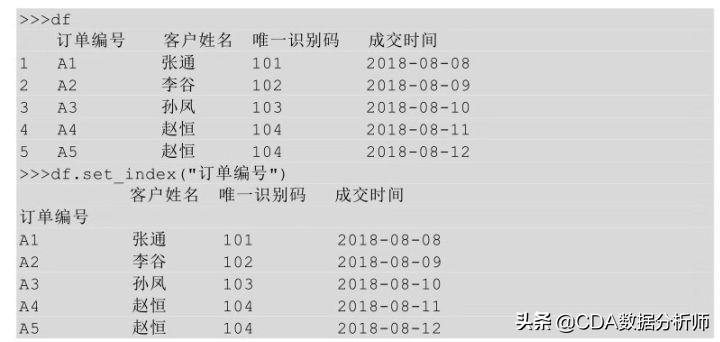
重新设置索引,一般指行索引的设置。有的表虽然有索引,但不是我们想要的索引,比如现在有一个表是把序号作为行索引,而我们想要把订单编号作为行索引,该怎么实现呢?
(1)Excel实现
在Excel中重新设置行索引比较简单,你想让哪一列做行索引,直接把这一列拖到第一列的位置即可。
(2)Python实现
在Python中可以利用set_index ( ) 方法重新设置索引列,在 set_index ( ) 里指明要用作行索引的列的名称即可。
在重新设置索引时,还可以给 set_index ( ) 方法传入两个或多个列名,我们把这种一个表中用多列来做索引的方式称为层次化索引,层次化索引一般用在某一列中含有多个重复值的情况下。层次化索引的例子,如下所示,其中 a、b、c、d 分别有多个重复值。

3、重命名索引
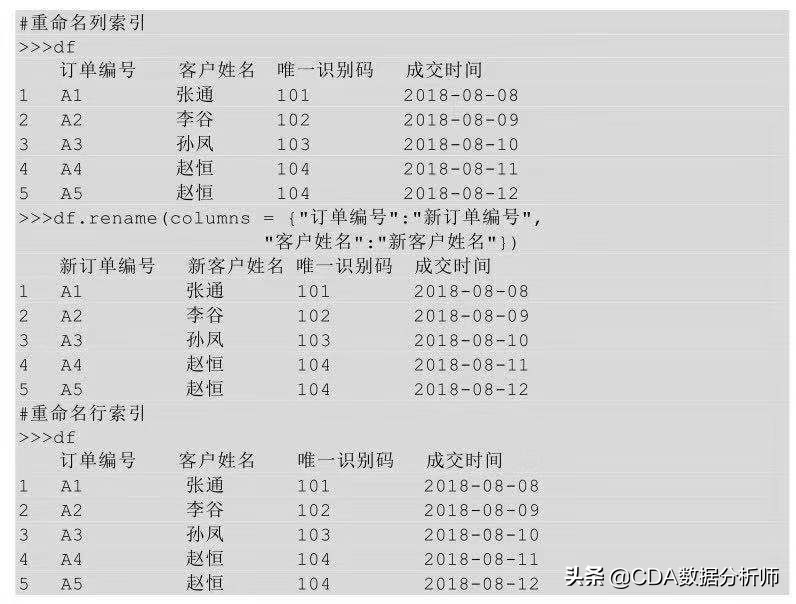
重命名索引是针对现有索引名进行修改的,就是改字段名。
(1)Excel实现
在Excel中重命名索引比较简单,就是直接修改字段名。
(2)Python实现
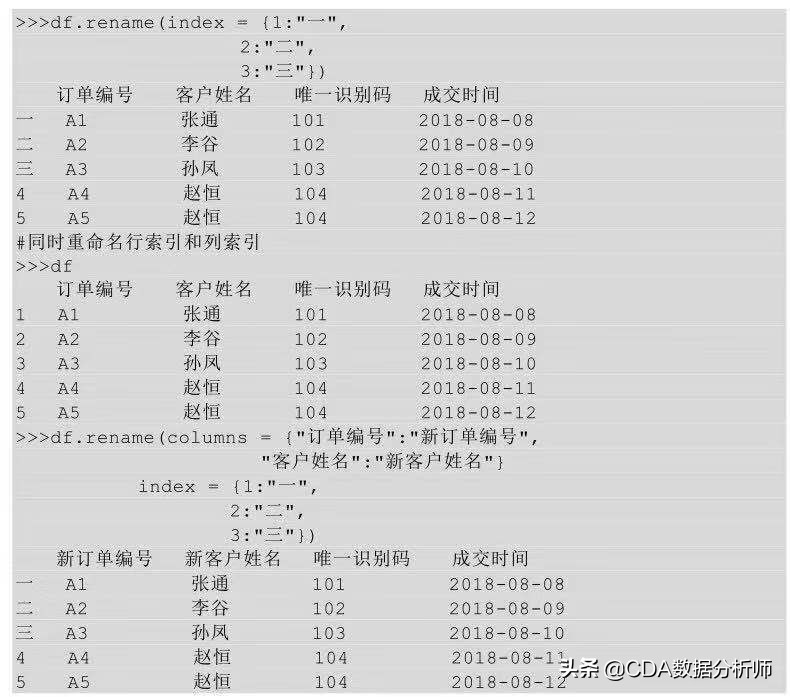
在Python中重命名索引,我们利用的是rename ( ) 方法,在rename ( ) 后的括号里指明要修改的行索引及列索引名。
4、重置索引
重置索引主要用在层次化索引表中,重置索引是将索引列当作一个columns进行返回。
在下图左侧的表中,Z1、Z2是一个层次化索引,经过重置索引以后,Z1、Z2这两个索引以columns的形式返回,变为常规的两列。
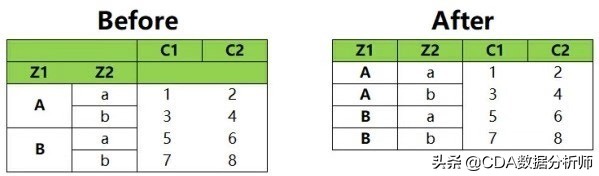
在Excel中,我们要进行这种转换,直接通过复制、粘贴、删除等功能就可以实现,比较简单。我们主要讲一下在Python中怎么实现。
在Python利用的是reset_index ( ) 方法,reset_index ( ) 方法常用的参数如下:

level参数用来指定要将层次化索引的第几级别转化为columns,第一个索引为0级,第二个索引为1级,默认为全部索引,即默认把索引全部转化为columns。
drop参数用来指定是否将原索引删掉,即不作为一个新的columns,默认为False,即不删除原索引。
inplace参数用来指定是否修改原数据表。

reset_index ( ) 方法常用于数据分组、数据透视表中。
 关注微信
关注微信