
学习计划安排如下:
这个IK分词器有什么用?为什么要用它?
要知道计算机是老美搞出来的,它的很多东西对于中文来说其实是很不友好的。
关于分词,即把一段中文或者别的划分成一个个的关键字。
比如”我是中国人”,可以分为多少个词?
按照中国汉字语言,其分为“我”,“是”,“中国人”,“中国”,“国人”这5个。
也就是说用户输入上述5个词语,都可以搜索到“我是中国人”这条数据。
而默认的中文分词是将每个字看成一个词,会被分为“我”,“是”,”中”,”国”,”人”。
这显然是不符合要求的,所以用中文分词器ik来解决这个问题。
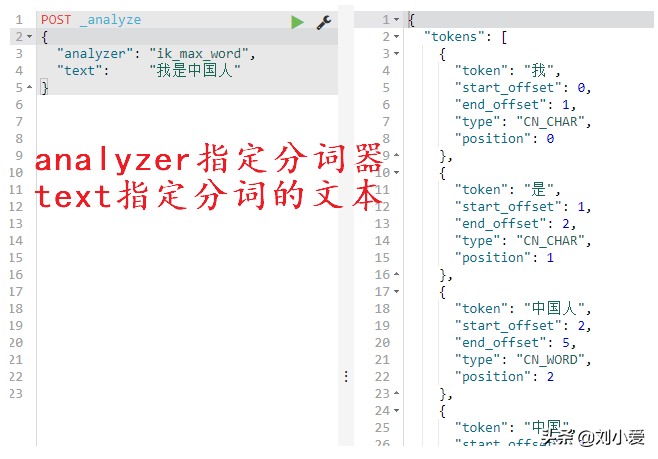
①analyze:翻译过来就是分析的意思,这里就可以理解成分词。
②analyzer:这里也就是指分词器,我们使用ik_max_word。
这是ik分词器提供的两个分词算法,至于具体是如何实现的,就要去研究它的算法了。
可以把上述代码修改做一个对比,会发现使用ik_smart只能分三个词:“我”,“是”,“中国人”
这里显然使用ik_max_word更加的合适。
Elasticsearch本质上也就是在存储数据,其有很多概念可以和MySQL类似的。
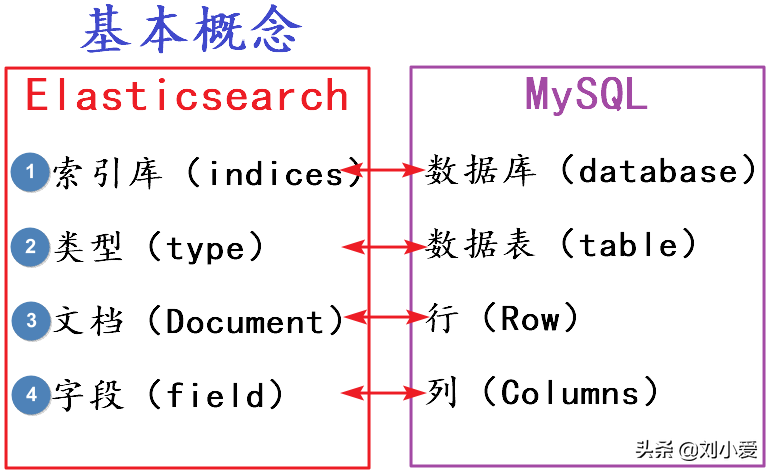
为了方便学习将其和MySQL结合起来。
当然严格来说将这些概念对应起来不太准确,但目前就这样理解也没问题。
①索引库indices
indices本身也就是索引indexs的复数写法。
②类型type
不过这有一个缺陷是会导致索引库混乱,未来版本中会移除这个概念,emm…也不知道现在移除这个概念没有,目前还没来得及查。
③文档document
④字段field
弄清楚了这些概念,接下来创建索引库。
昨天我们也说明过了,Elasticsearch是一个基于RESTful风格的搜索引擎。
Elasticsearch采用的是REST风格API,其API本质上也就是一次http请求:
1索引库的创建
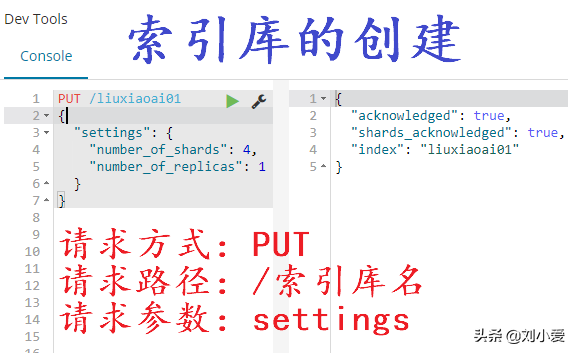
既然是请求,那自然就会有:
这里settings是指索引库的设置:
这个呢就涉及到了一些集群相关的概念,后续具体使用到的时候再做说明。
2索引库的查询与删除
REST风格的方便之处就在于通过请求方式的不同就能实现不同的操作:
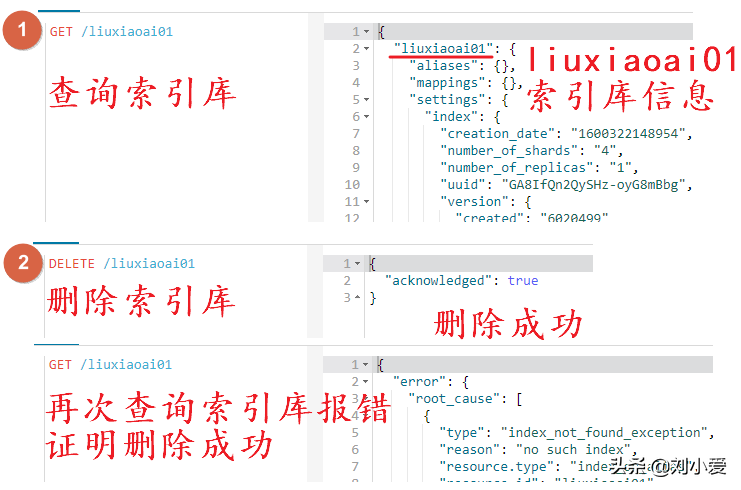
①查询索引库
请求方式GET对应的就是查询操作。
请求路径依旧是上述创建的索引库,可以查询出liuxiaoai01索引库的信息。
②删除索引库
请求方式DELETE对应的就是删除操作。
请求路径依旧是上述创建的索引库,可以删除liuxiaoai01索引库。
删除后再次使用GET查询对应的索引库,会发现其会报错了,证明删除成功。
创建了索引库也就相当于有了database数据库,接下来就是数据表并添加数据了。
1类型的创建

在索引库中添加数据叫映射,这也是上述格式中_mapping的由来。
goods就是索引类型,也就是相当于数据库中的goods数据表。
properties也就是属性,其下添加对应的字段,上述中就有title,images,price三个字段,可以设置许多属性:
这个type是字段数据类型:int、long这些是数字类型,text、string是字符串类型。
2类型的查询

PUT对应着新增操作,GET也就对应着查询操作了,关于类型没有删除和修改操作。
就相当于不能删除和修改数据表的名称,这点倒是和MySQL数据库不一样。
其查询到的索引之间的映射关系也很清楚:
索引库叫liuxiaoai01,通过mappings映射有goods这个索引类型,该类型下properties中有3个字段。
基本上知道了其单词意思也就知道其作用了。
注意关于这个type不要弄混了:
 关注微信
关注微信