
这篇文章给大家介绍一个解析html内容的模块——htmlparser。
举一个简单的应用场景:假设有一天领导需要你收集一下线上页面已存在的静态资源链接(js、css、img),你们的页面很多,而且每个页面的代码量很大(比如上万行),这种情况下你总不能人肉去搜索,那么此时htmlparser这个模块就可以派上用场了。
安装命令
npm install htmlparser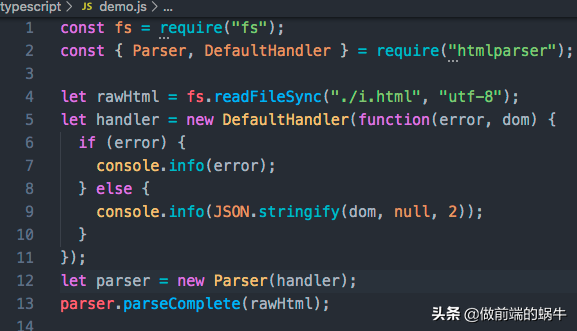
图1
图1中我们使用htmlparser模块解析一个i.html文件,其内容如下:
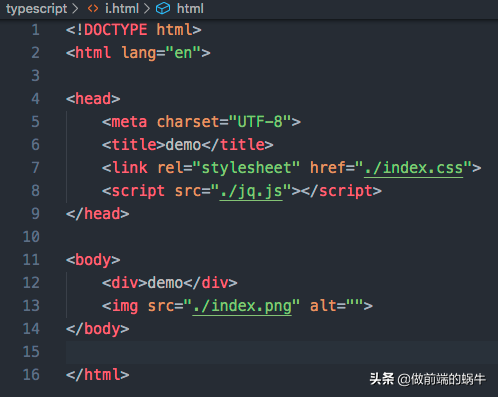
图2
解析结果如下:
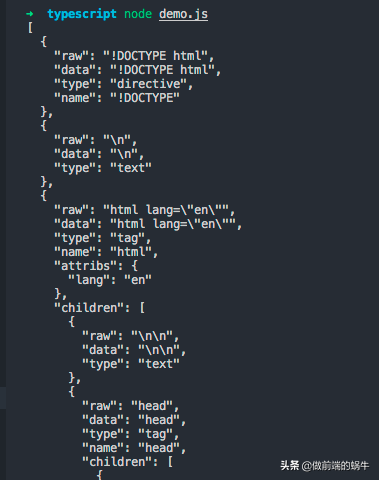
图3
图3所示是个对象(此处序列化了便于显示),遍历这个对象就可以解决本文开头所说的问题,这个模块的用法非常的简单。
回到图1,htmlparser模块给我提供了一个Parser构造函数,这个构造函数是初始化的入口!它大概长这个样子:
function Parser(handler) {
this._handler = handler;
}Parser接受一个参数handler,这个handler必须是一个对象,这个对象必须定义以下几个方法:
图1中我们使用的是模块内部提供的DefaultHandler,我们当然也可以自己定义handler。用别人的handler有时并不能完全满足自己的业务场景,那么我们操作一把,代码如下:
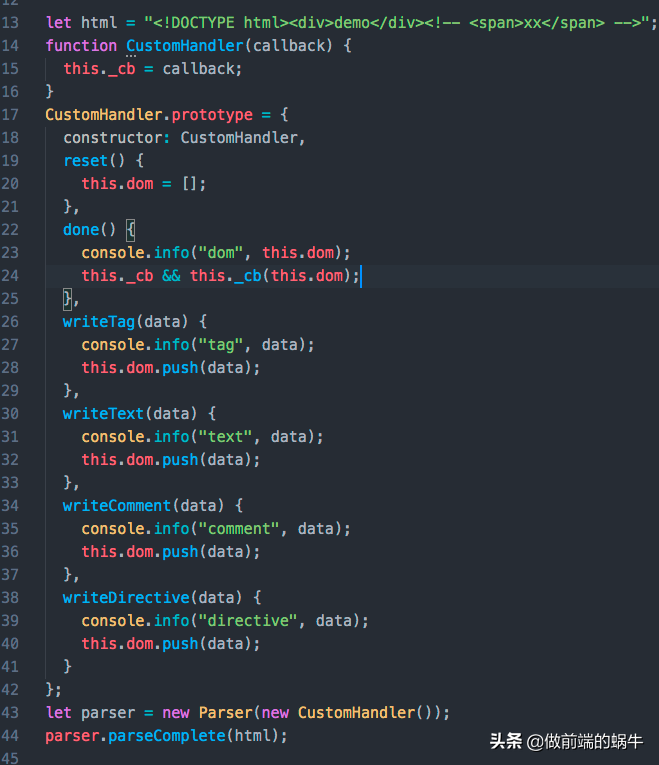
图4
图4中我们自定义一个handler——CustomHandler,我们先运行一下看看各个方法都输出了什么?
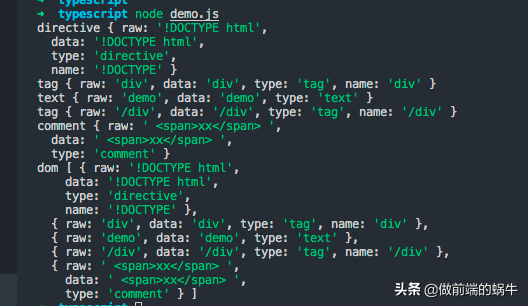
图5
图5中CustomHandler的各个方法按照原始字符串的顺序依次打印出了每个解析结果,这些解析结果是parser对象为我们自动生成的,解析的原理就是正则匹配。我们可以在自定义handler的各个函数方法中做一些特殊处理,然后把最终的结果通过done函数输出出去。
图4中的parseComplete方法也可以用以下逻辑代替,
parser.reset();
parser.parseChunk(html);
parser.done();这个模块除了可以在node环境中使用,它同时也可以在浏览器中使用,用法如下:
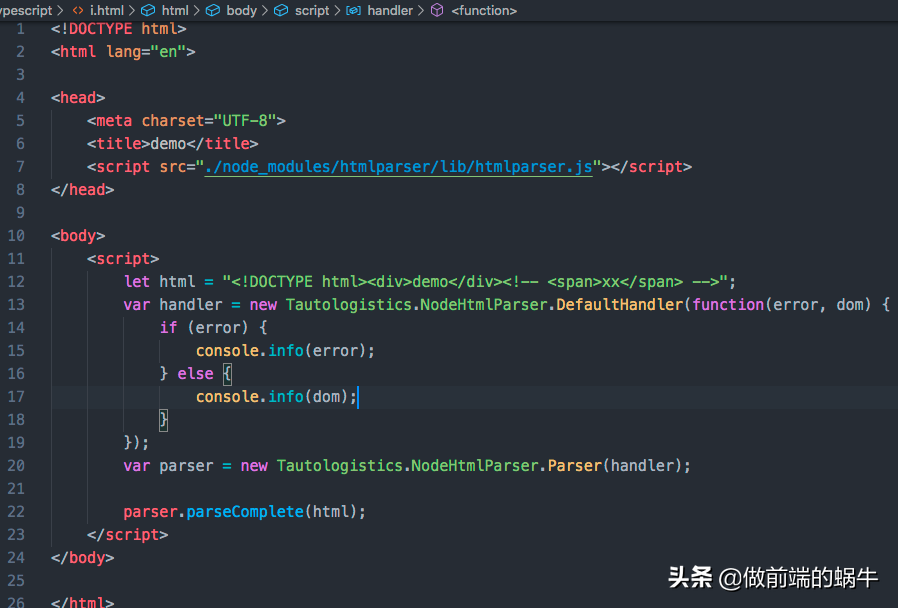
图6
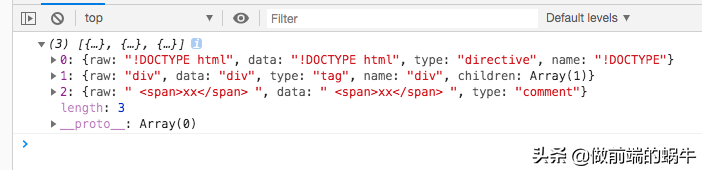
图7
注意,如果在浏览器中使用,模块的所有API都挂在了
Tautologistics.NodeHtmlParser这个对象上,其它用法一致。
需要我们去解析html内容的场景非常多,之前我们更多的是使用自己写的正则表达式去做,麻烦并且容易出错。现在我们了解了htmlparser模块,以后就可以直接使用它去解决问题。
 关注微信
关注微信