
作为一门编程语言,R已经演变和发展了20多年。开发者的目标非常清晰,就是使R成一款简单易用且灵活的,能够综合执行统计计算、数据探索和可视化的工具。
在众多统计软件中,R能够脱颖而出,有几个优势:免费开源、高度通用性、作为动态脚本语言的灵活、代码可重复性,除此之外,R语言还有着丰富的资源和强大的社区,来自不同领域的统计学、计量经济学等专业研究者,在为R语言做贡献,使R有幸将数据科学知识应用于现实世界,进一步提高其功能并揭示其潜力。
当然,R也存在一些固有缺点,例如学习曲线相对比较陡峭、第三方包的质量良莠不齐等。但我相信,未来的R将不再局限为一种语言,而是成为行业间通用的交流货币。

R语言都有哪些行业在用
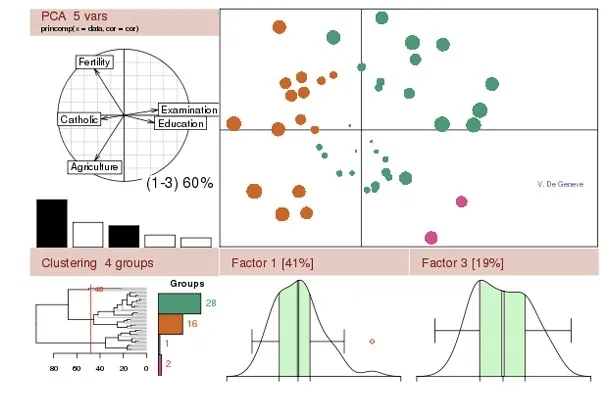
● 统计分析
在统计分布、假设检验和统计建模里,R语言是“绝对王者”。借助ggplot2画静态图,plotly画交互图,你可以快速创建所需的各种可视化图表,方便又直观(跟领导汇报时都多了份底气)
● 金融分析
R语言在金融领域的应用主要包括量化策略、投资组合、风险控制、时间序列等。
以时间序列为例,在金融市场里,最重要的一个维度就是时间,一切交易和价格随着时间一点一滴地被记录下来。
此外,R语言被长期应用在量化金融分析领域,其专门的量化投资包能够满足投资者量化投资的需要,通过数据处理和运算,自动判断未来价格走势,从而自动择股。
● 数据挖掘
数据挖掘领域通常面临着关联规则挖掘、聚类、分类这三大问题
很多人对R的第一印象是,它只是一个统计计算的一个软件。但R有足够的能力以一个快速和简单的方式来实现机器学习算法,并通过使用机器学习的方法来构建预测模型的基本能力。
● 互联网
R语言在互联网的主要应用是推荐系统、消费预测和社交网络等。
在互联网高速发展的今天,通过建立社交网络,形成人类行为相关性的分析框架,而且对于寻找行为相似性更高的用户进行轨迹预测、商品推荐、链路预测等场景都有着直接或潜在的应用价值。
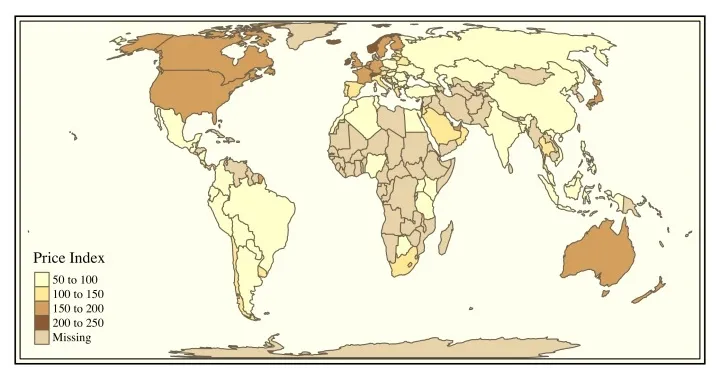
● 全球地理科学
国内一些R语言的先进组织,已经开发出了地理可视化、天气预测等功能,比如这张批量绘制GIS图,简直不要太好看:
R语言与医学大数据
医学数据分析已经成为当前的热门领域,它是医学、统计学和计算机科学等领域的交叉学科,而R语言在临床数据统计方面拥有其他语言无法媲美的优势,因此受到了广大医学科研人员追捧的“香饽饽”。
现在的趋势是医疗数据的大量爆发及快速的电子数字化,比如基因数据:一次全面的基因测序,产生的个人数据则达到 300GB;在生物医药方面,功能性磁共振影像的数据量也达到了数万TB级别,每一幅影像包含有5万像素值;此外,各种健身、健康可穿戴设备的出现,使得血压、心率、体重,血糖,心电图(EKG)等的监测都变为现实和可能,信息的获取和分析的速度已经从原来的按“天”计算,发展到了按“小时”,按“秒”计算……
这种数据的扩展速度和覆盖范围是前所未有的,数据的来源也纷繁复杂。大数据给生物医学领域带来了巨大的影响,而生物医学领域的发展离不开数据分析。数据的开发、利用、整理和分析为临床实践及科学研究提供了大量有价值的信息。

可以说,掌握R语言,利用其强大的统计分析和可视化功能,对提高医疗质量、强化患者安全、降低风险、降低医疗成本等方面发挥无与伦比的巨大作用。现在市面上有很多流行的统计和作图软件,如 SAS、SPSS、Stata 等。为何要选择 R 呢?具体来讲,R 有如下优势。
R语言在“临床诊断”的应用
在临床医学中,医生的一项重要任务是判断就诊者是否患病,以便采取适当的进一步行动。临床检测结果常被用于指导临床决策,因此,对临床诊断试验的质量评价尤为重要。
用于描述检测质量的统计学指标有:灵敏度、特异度、预测值、正确率和似然比等。通常最简单的诊断结果是根据检验指标的测定值将受试对象分成真阳性(a)、假阳性(b)和假阴性(c)、真阴性(d)两组。
对于这类检验指标的评价,通常是对检验结果与目前公认的最准确的诊断方法,即金标准 (gold standard)作比较,以正确区分“有病”和“无病”。而灵敏度和特异度是反映真实性最重要和不可缺少的指标。
灵敏度(sensitivity)是指患者检测结果为阳性的百分率,也称真阳性率:
灵敏度=a/(a+c)*100%
特异度(specificity)是指未患病的人检测结果为阴性的百分率,也称真阴性率:
特异度=d/(b+d)*100%
在实际应用中,我们往往只知道试验的结果,并据此作出临床判断,但并不知道受试者究竟是否是患者。因此,我们需要了解检验结果预测疾病的能力,如阳性结果中真正的患者的比例是多少。
阳性预测值(positive predictive value)是指在检测结果呈阳性的情况下受试者患病的比例:
阳性预测值=a/(a+b)*100%
阴性预测值(negative predictive value)是指在检测结果为阴性的情况下受试者不患病的比例:
阴性预测值=d/(c+d)*100%
灵敏度和特异度反映了检测方法的判断能力不受患病率的影响,但受到疾病严重程度等患者特征的影响。而预测值受到患病率的影响,患病率越低,阳性预测值越低,而阴性预测值越高。这时,最好来图解灵敏度、特异度、阳性预测值和阴性预测值。
假设在一项研究中有 100 名患者和 100 名非患者。某一检测试验的灵敏度为 80%,特异度为 90%。数据可以描述如下:
> table1 <- as.table(cbind(c(80, 20), c(10, 90)))
> dimnames(table1) <- list("检测结果" = c("阳性", "阴性"),
+ "金标准" = c("有病", "无病"))
> table1
金标准
检测结果 有病 无病
阳性 80 10
阴性 20 90
> mosaicplot(t(table1), col = c("red", "white"), main = ")
由此得到不同患病率下的灵敏度和特异度示意图:

图a中,灵敏度是左侧红色部分的相对高度(80%),特异度是右侧白色部分的相对高度(90%)。阳性预测值是指左侧红色部分相对于所有红色部分所占的比例,在此例中为 80/(80 + 10) ≈ 88.9%。阴性预测值是指右侧白色部分相对于所有白色部分所占的比例,在此例中为 90/(20 + 90) ≈ 81.8%。
事实上,左侧部分的相对宽度反映了这种疾病的患病率。在此例中,两个组的数目相等,所以患病率为 50%。灵敏度和特异度的计算限定在每一列中,因此它们与患病率无关。如果不考虑研究的设定条件,尤其是在社区研究中,患病率通常远远低于 50%。
图b表示的患病率较低,因为左侧部分的宽度仅为两列加起来的总宽度的5%。灵敏度(80%)和特异度(90%)与前例一致,但阳性预测值现在要小得多。患病组(左侧)的红色部分面积不到总的红色面积的一半,阳性预测值仅为 80/(80 + 190) ≈ 29.6%。
在患病率为 5%的情况下,检测结果呈阳性的人患病的可能性不到 30%。在社区或人群中对一种罕见疾病进行临床诊断必须谨慎,因为结果实际上可能反映的是其他类似疾病的情况。
降低患病率对阴性预测值也有一定影响。在图b中,右侧白色部分的面积占绝对大的比重。阴性预测值为 1710/(1710 + 20) ≈ 98.8%。这比之前的 81.8%有所升高。但是,阴性检测结果可能不会对临床排除疾病的倾向决定有太大的影响。因此,患病率很低的筛查检测中,很少用到阴性预测值。
以上就是临床诊断试验中的二分类结果的评价指标,而R语言在医学中的应用远不止这些,像比如截断值、ROC曲线、SPSS、样本量计算、Meta分析等。
 关注微信
关注微信