
我先考一考你,你说这个字符串(ab一2#仯3#4)有多少个字符?
这时候你也许开始数了,123…9个,没错,确实我们肉眼确实是看到了9个,java代码如下:
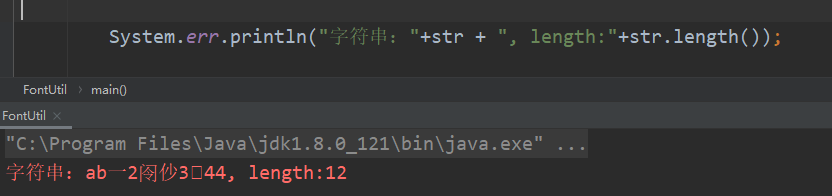
有没有发现java判断出来的不是9,而是12!!!
那是因为这个字符串中有2个字符ab一2#仯3#4用黄色表示,实际上UTF-8已经满足不了,# 见下图:

java的String是使用UTF-16来表示的,U+0000-U+FFFF都ok,但是只要是下列这个区间的字符都无法用常规手段处理,5位内码的,用length都无法正确判断其长度
CJK Unified Ideographs Extension B (U+20000 through U+2A6DD)
CJK Unified Ideographs Extension C (U+2A700 through U+2B734)
CJK Unified Ideographs Extension D (U+2B740 through U+2B81D)
CJK Unified Ideographs Extension E (U+2B820 through U+2CEA1)
CJK Unified Ideographs Extension F (U+2CEB0 through U+2EBE0)
具体也可以查看官方资料 ,了解unicode,UTF-8,UTF-16,UTF-32的区别。
如下图,可以通过Character中的codePointCount来得到字符数量。

进入主题
jdk自带的Character类特别好用,汉字转内码,内码转汉字具体功能请参考下面的代码
/**
* 字符串转16进制内码
* @param str ab一2#仯3#4
* @return \u61\u62\u4e00\u32\u2b802\u4eef\u33\u2b82f\u34\u34
*/
public static String stringToCodePoints(String str) {
StringBuilder stringBuilder = new StringBuilder();
str.codePoints().forEach(cp -> stringBuilder.append("\u").append(Integer.toHexString(cp)));
return stringBuilder.toString();
}
/**
* 内码转汉字
* @param codePoints \u61\u62\u4e00\u32\u2b802\u4eef\u33\u2b82f\u34\u34
* @return ab一2#仯3#4
*/
public static String codePointsToString(String codePoints) {
StringBuilder stringBuilder = new StringBuilder();
for(String hexCodePoint : codePoints.split("\\u")){
if(StringUtils.isNotBlank(hexCodePoint)) {
stringBuilder.append(codePointToString(Integer.parseInt(hexCodePoint, 16)));
}
}
return stringBuilder.toString();
}
/**
* 十进制转汉字
* @param cp code point 汉字内码
* @return
*/
public static String codePointToString(int cp) {
StringBuilder sb = new StringBuilder();
if (Character.isBmpCodePoint(cp)) {
sb.append((char) cp);
} else if (Character.isValidCodePoint(cp)) {
sb.append(Character.highSurrogate(cp));
sb.append(Character.lowSurrogate(cp));
} else {
sb.append('#');
}
return sb.toString();
}支持5位编码的在线转换工具
 关注微信
关注微信