
经常写sql的人,基本都会问怎么优化sql语句,做sql的性能调优,小编认为最核心的掌握表连接的三大方式。在数据库中,join操作是最费资源的,实际生产环境中,一条慢sql,很多时候是数据库选择了错误的连接方式,导致查询缓慢。oracle 数据库的表连接,在内存中有三种连接方式,1.nest loop join 2.hash join 3.merge join
1.nest loop join
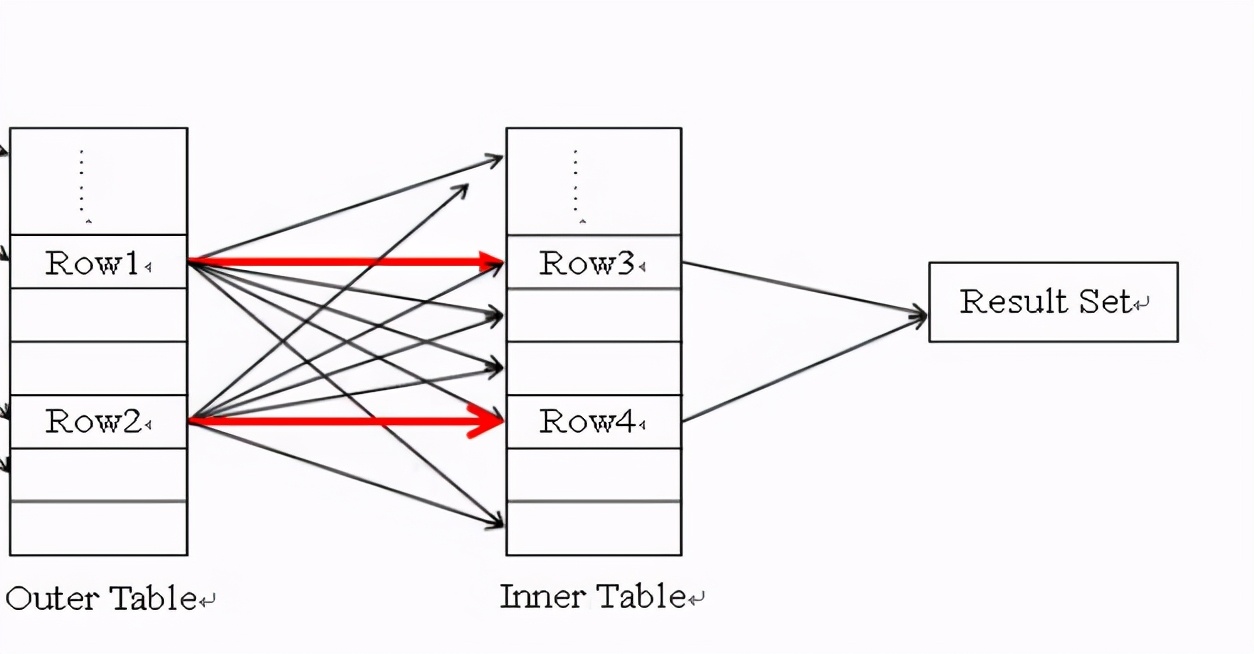
这种连接方式是早期数据库中就存在的,可以通俗地叫它“循环连接”,为什么叫循环连接呢?
如图 Outer Table 就表示驱动表,row1表示第一行数据,它会去关联 被驱动表(inner table),row1第一次去找inner table 时,属于一次随机读,被驱动表有M条,row1就会去关联M次,row1对inner table的访问包括一次随机读,M-1条顺序读,相当于找inner table要花费一个随机读,找到之后,对inner table 遍历就属于顺序读了,随机读的性能比顺序读差一千倍左右,一个随机读可以想象成10ms,一个顺序读大概0.1ms。假设驱动表N条数据,被驱动表M条数据,就会产生N*M次关联,其中N次随机读,inner table要被全表扫描N次。随机读,全表扫描,都是很费资源的,所以说驱动表不能太大,N不能太大。
我们经常听说说驱动表要选择小一点的表,根本原因之一就是如此,驱动表的每一条数据都要去把inner table全表扫描一遍,就像程序里面的for循环,for(驱动表每条数据取一次){ 每条驱动表的数据 都全表扫面inner table 做连接匹配 },“循环连接”这个名字就是这么来的。
举个极端的例子,表1 有10条数据,表2有100万条数据,如果选大表作为驱动表,那么表1短时间内要被访问一百万次,表2每次去关联表1都是一次随机读,100万个随机读很费时间如果调整一下,把表1这个小表,当作驱动表,这时候只有10个随机读,10次表2的全表扫描,全表扫描是顺序读,性能还勉强看的过去。
通过上面的解释,应该清楚为什么nest loop join 时驱动表要选择小表,主要原因是因为随机读和全表扫描。那有什么办法优化呢?这时候很多书本会告诉你建立连接列的索引,为什么建连接列的索引就可以优化呢?
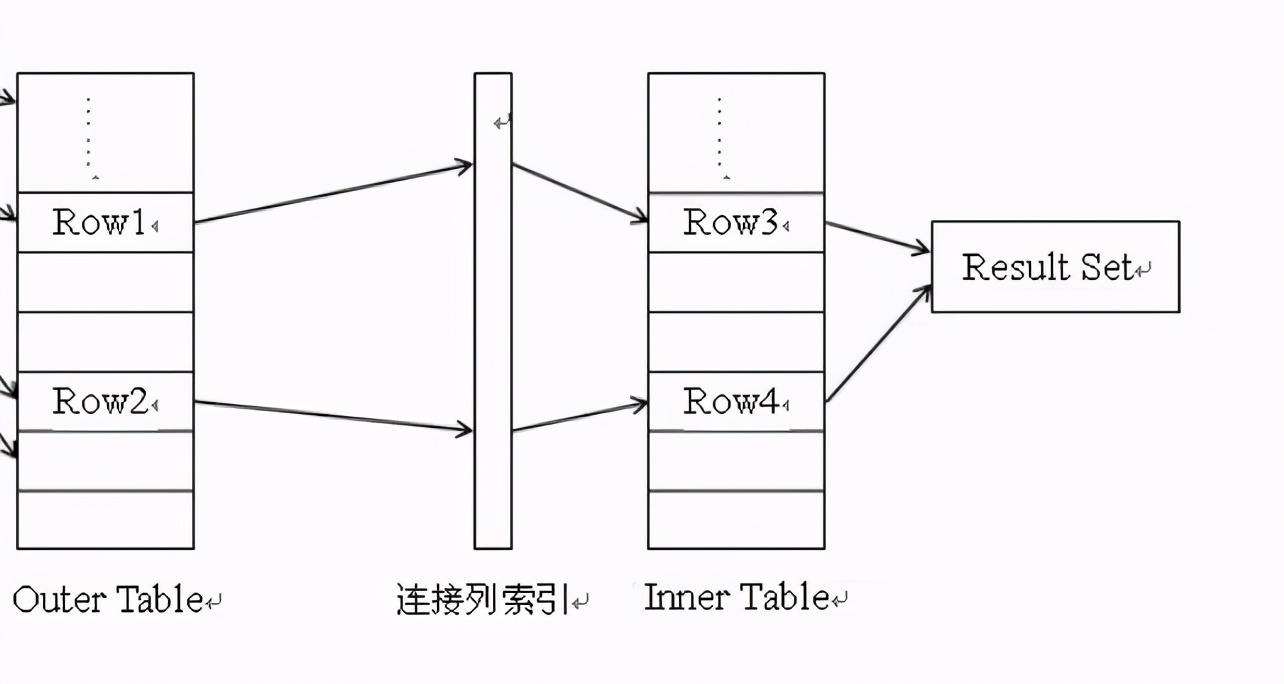
建立连接列索引后,进行连接匹配的阶段,压根就不需要访问表,直接访问索引就可以进行匹配,索引的大小相对于表还是很小的,两个索引进行匹配,可以想象成两个小表进行匹配,大的数据才有性能问题,小的东西当然快,这只是次要原因,主要原因还是索引结构带来的加速,有些人认为建连接列索引是为了消除大量随机读,我不这么认为,我们可以认为索引就是有结构的小表,两个索引之间的匹配还是像表之间的nest loop一样,n条索引数据,产生n条随机读,并不会减少随机读,索引带来的巨大优势是减少被驱动表的顺序读,没有索引时,被驱动表只能全表扫描,被驱动表1千方条数据,就要一千万的顺序读,有索引后,因为索引的结构,存储千万级别的数据只要5层索引结构,千万级别数据量中搜索一条数据,只要5次IO,千万次和5次,差别很大。连接列建立索引并不能消除大量随机读,大量随机读本身就是nest loop join的缺陷,后面就提出的hash join能改善这种大量随机读导致的性能问题。建立连接列索引后,nest loop join对于返回结果集特别小的查询,十分友好,比如驱动表经过where过滤后只有10条数据,这时整个驱动表不需要置入内存,只要拿这10条数据,与被驱动表的连接列索引匹配,速度很快。返回数据少,用nest loop join,返回数据多,用hash join (hash 需要把驱动表置入内存,如果只返回少量数据,还要用hash join有点浪费内存资源)
今天只讲nest loop join,下次再讲hash join ,merge join,今天主要核心知识点:随机读,顺序读,循环连接,索引层级
 关注微信
关注微信