
前几天,我手里的一个项目需要将富文本的所有 html 标签全部删除,得到纯文本后再存储到数据库中。在一系列得搜索操作之后,我找到了实现这个目的的几种方法,在这里我分享给大家,当你遇到同样的情况兴许也能用的上。
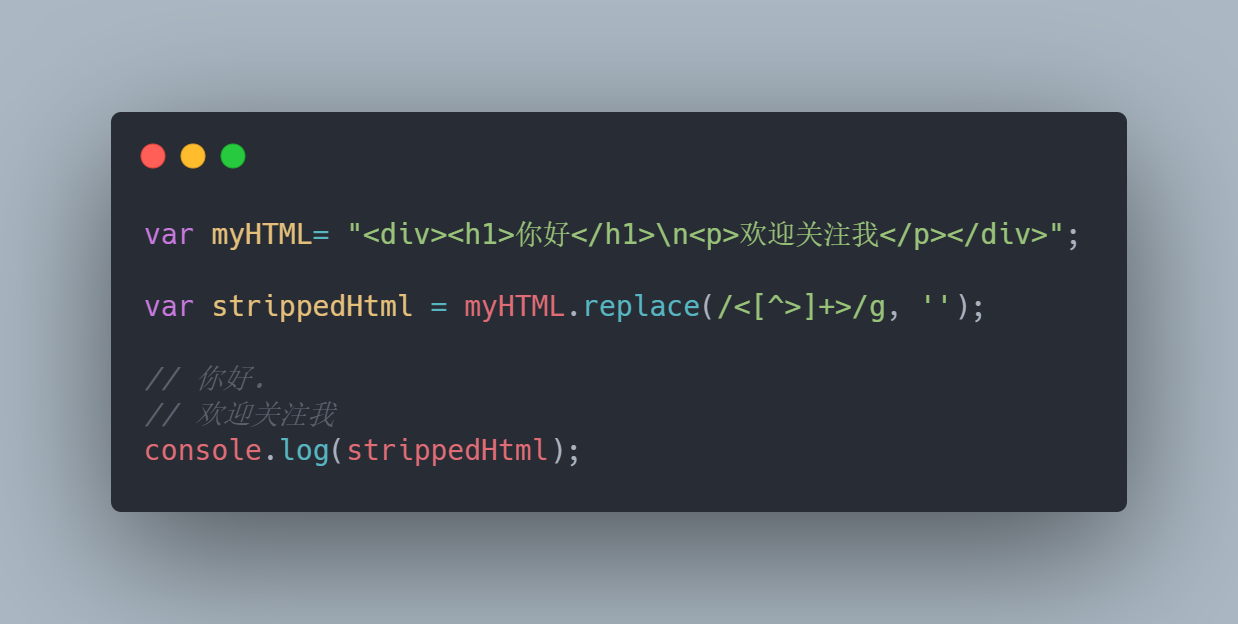
这个方法是从文本中去除 html 标签最简单的方法。它使用字符串的方法 .replace(待替换的字符串,替换后的字符串) 将 HTML 标签替换成空值。 /g 是表示替换字符串所有匹配的值,即字符串中所有符合条件的字符都将被替换。
这个方法的缺点是有些 HTML 标签不能被剔除,不过它依然很好用。
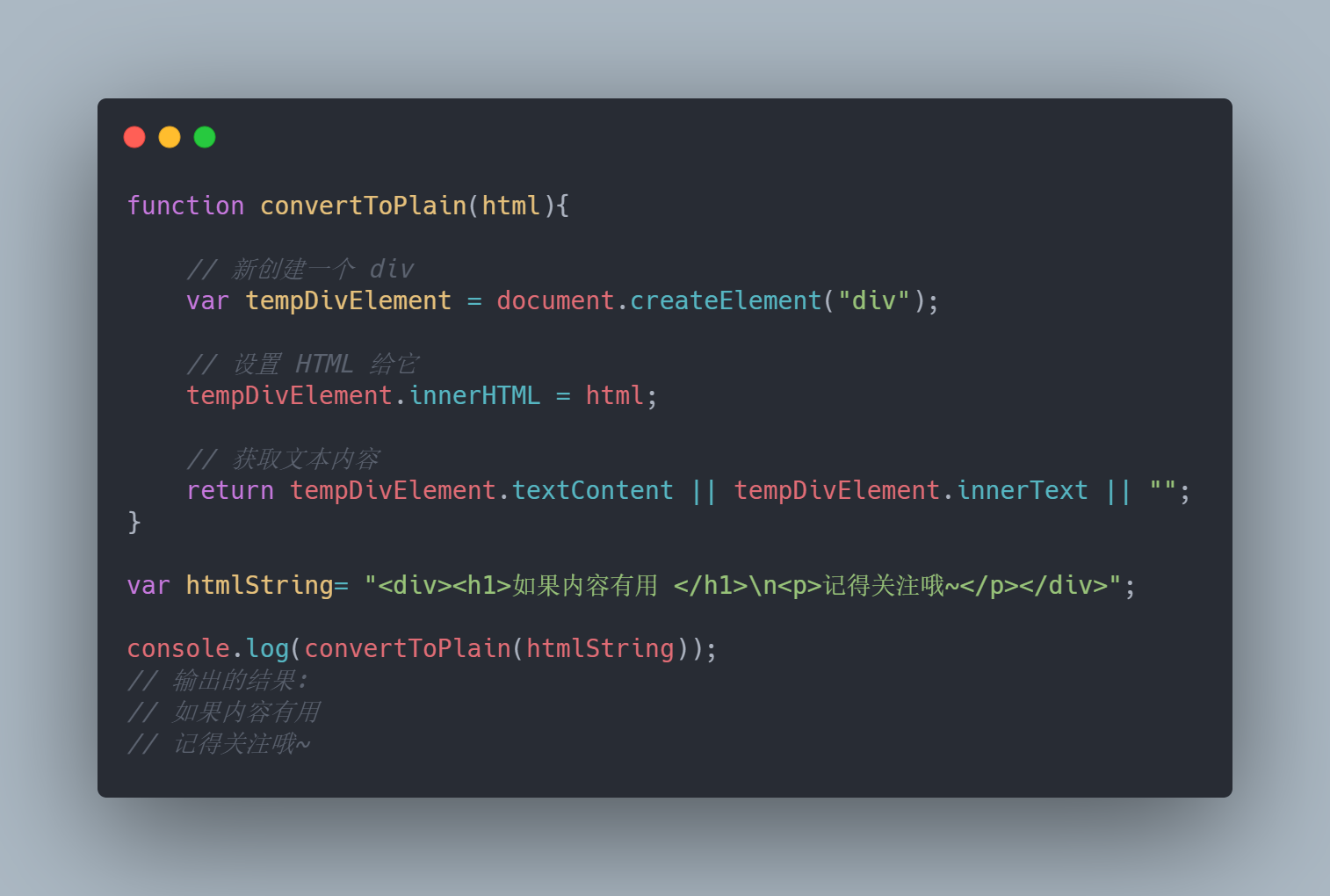
这种方法是完成该问题的最有效的方法。创建一个临时 DOM 并给他赋值,然后我们使用 DOM 对象方法提取文本。
html-to-text 这个包的功能很全了,转换也有许多的选项比如:wordwrap, tags, whitespaceCharacters , formatters 等等。
安装:
npm install html-to-text使用:

 关注微信
关注微信