
OCR (Optical Character Recognition,光学字符识别)是指电子设备检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
以上是官方介绍,如果用小编的话来描述的话,那就是:将图片上的文字识别并提取出来,变成可编辑的文档。这么介绍的话,大家都懂了吧?
在使用ocr工具时,如果想要识别图片中表格的内容,并且提取出来应该如何实现呢?下面是详细到不行的操作教程,有需要的小伙伴快来看看吧!
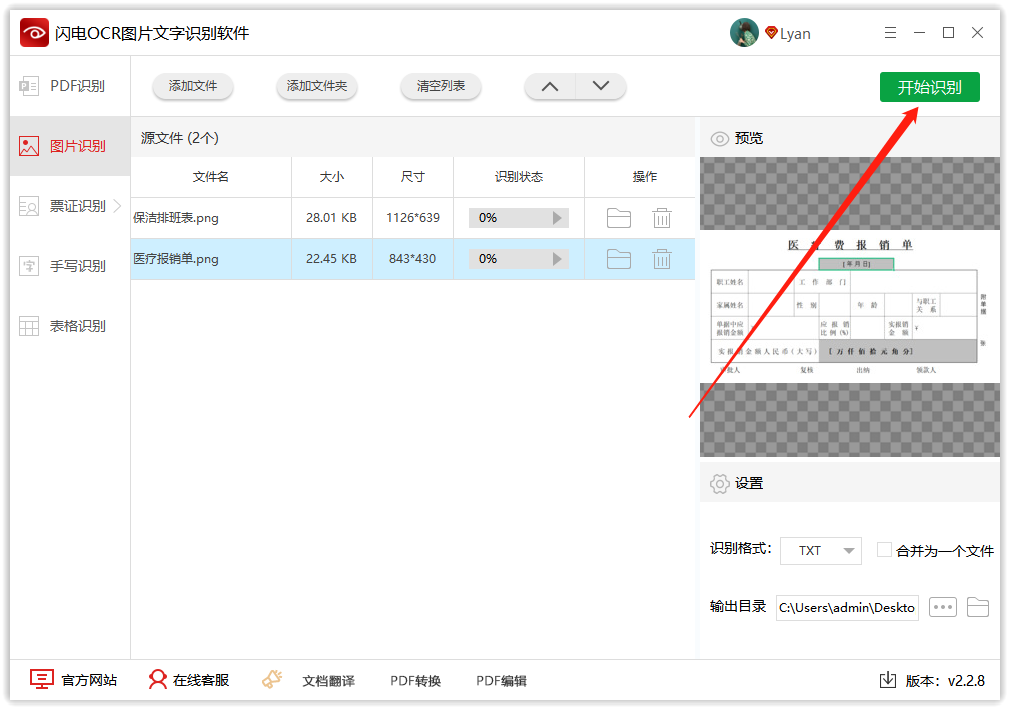
第一步、首先,在电脑上双击打开识别软件,然后在这里选择“图片识别”功能;
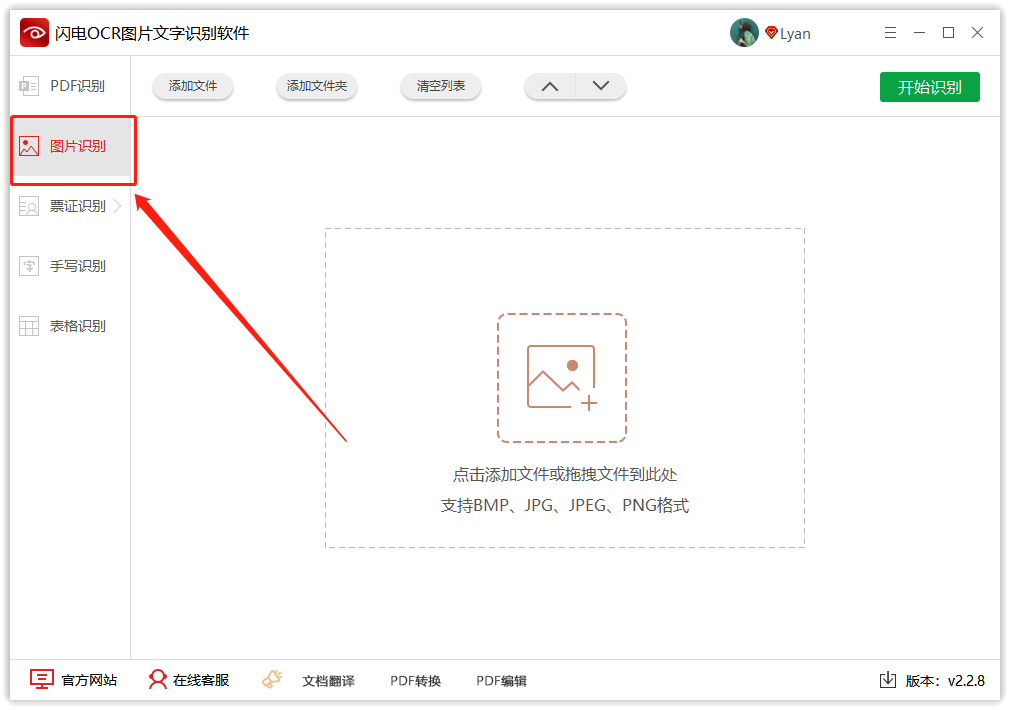
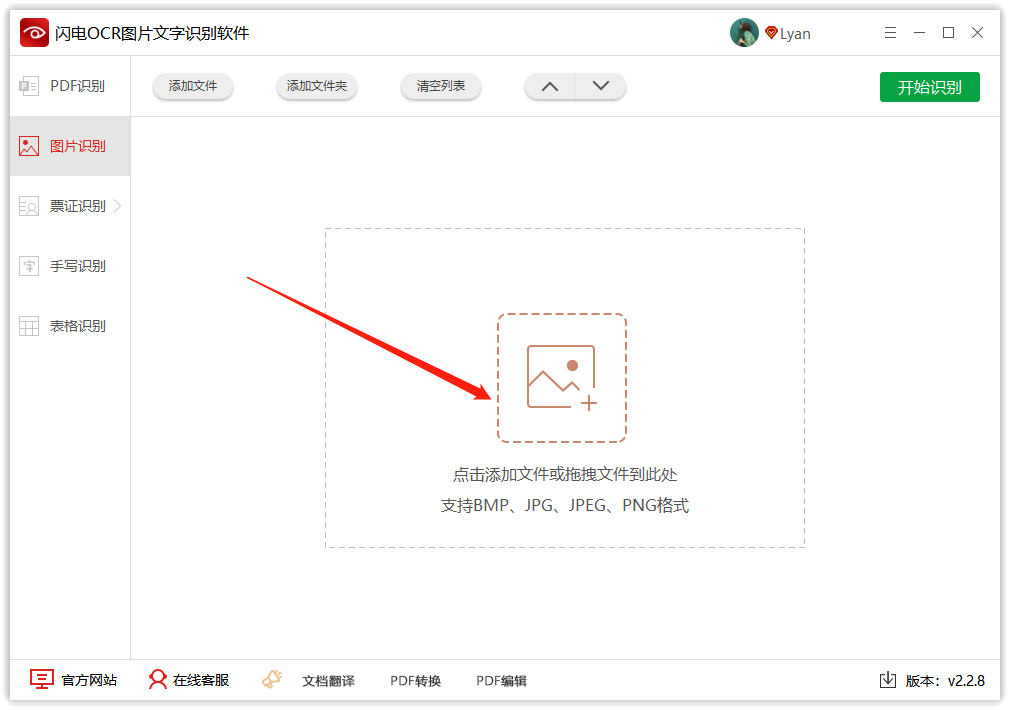
第二步、紧接着,点击添加文件,直接将图片拖拽到这里就可以啦;
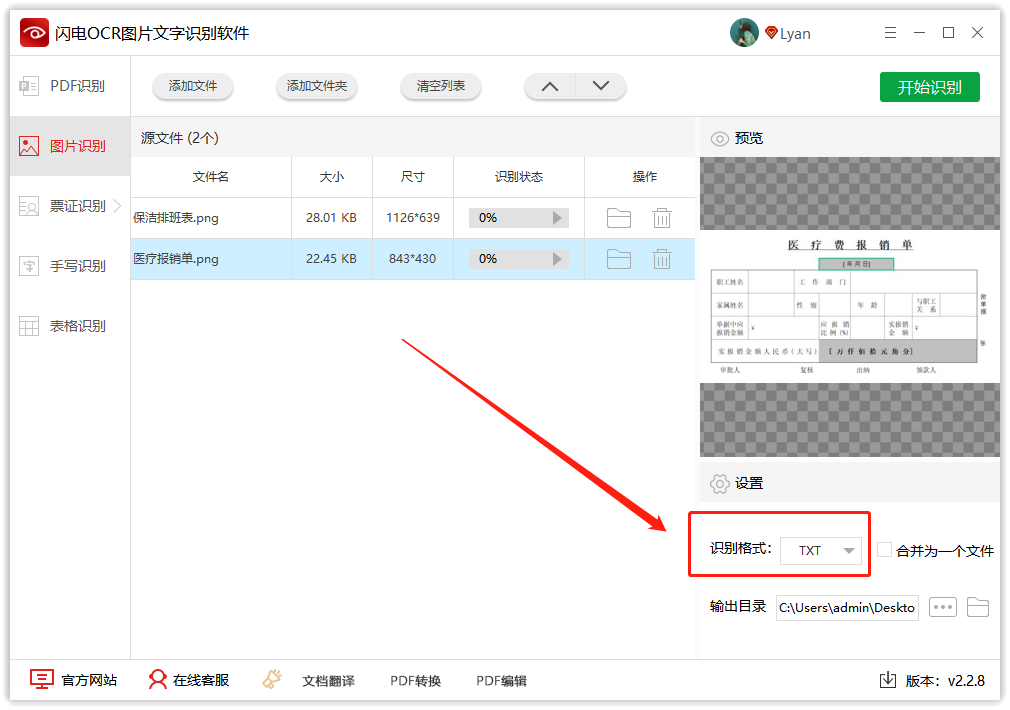
第三步、如图,在识别格式这里,可选择TXT或者doc格式,这里小编选择的是TXT格式;
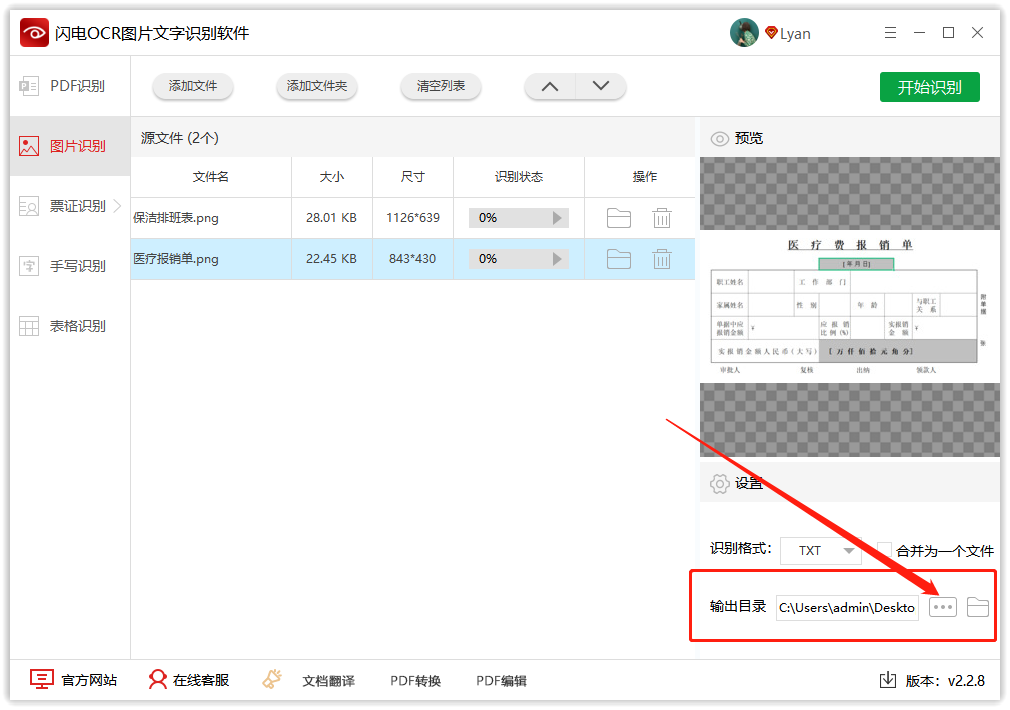
第四步、软件默认的存储位置是原文件夹,点击此处可更换位置;
第五步、最后,直接点击右上角的“开始识别”就可以了;
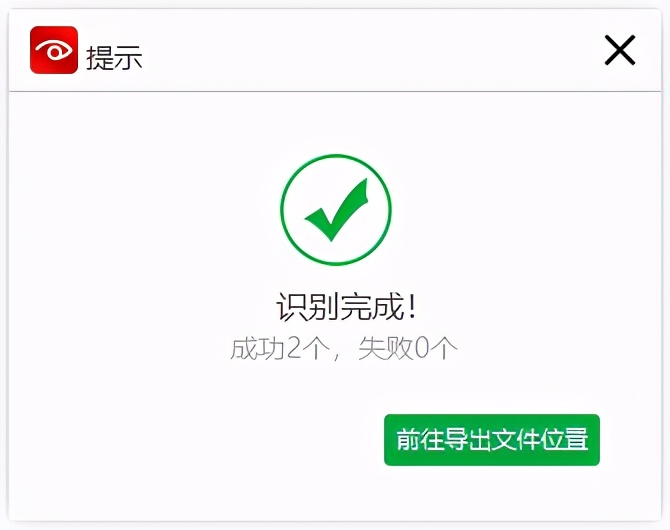
第六步、得到以下提示,说明文件识别成功了;
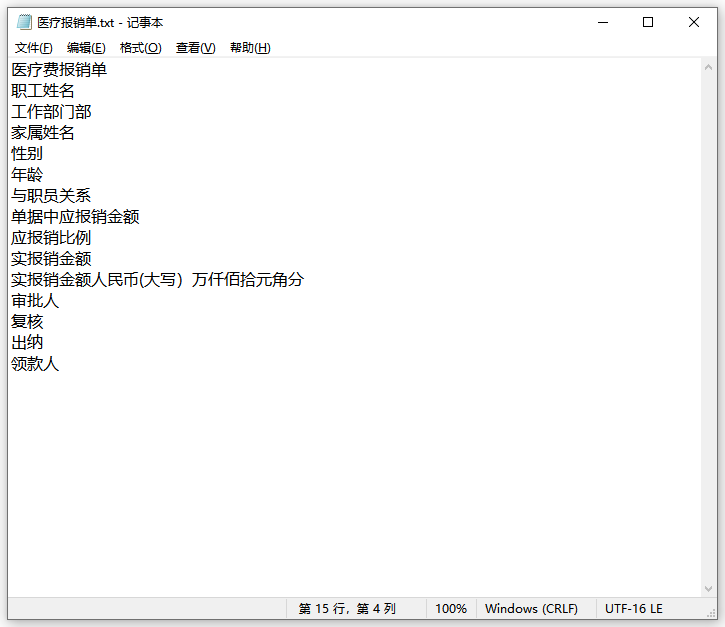
第七步、点击前往导出文件位置浏览文件,下图就是识别好的内容;害怕出错的小伙伴,可以对比下内容哈!
 关注微信
关注微信