
在我刚刚进入大学,从零开始学习 C 语言的时候,我就不断的从学长的口中听到一个又一个语言,比如 C++、Java、Python、JavaScript 这些大众的,也有 Lisp、Perl、Ruby 这些相对小众的。一般来说,当程序员讨论一门语言的时候,默认的上下文经常是:“用 xxx 语言来完成 xxx 任务”。所以一直困扰着的我的一个问题就是,为什么完成某个任务,一定要选择特定的语言,比如安卓开发是 Java,前端要用 JavaScript,iOS 开发使用 Objective-C 或者 Swift。这些问题的答案非常复杂,有的是技术原因,有的是历史原因,有的会考虑成本,很难得出统一的结论,只能 case-by-case 的分析。这篇文章并非专门解答上述问题,而是希望通过介绍一些通用的概念,帮助读者掌握分析问题的能力,如果这个概念在实际编程中用得到,我也会举一些具体的例子。
在阅读本文前,不妨思考一下这几个问题,如果没有头绪,建议看完文章以后再思考一遍。如果觉得答案显而易见,恭喜你,这篇文章并非为你准备的:
什么是编译器,它以什么为分界线,分为前端和后端# Java 是编译型语言还是解释型语言,Python 呢# C 语言的编译器也是 C 语言,那它怎么被编译的# 目标文件的格式是什么样的,段表、符号表、重定位表有什么作用# Swift 是静态语言,为什么还有运行时库# 什么是 ABI,ABI 不稳定有什么问题# 什么是 WebAssembly,为什么要推出这门技术,用 C++ 代替 JavaScript 可行么# JavaScript 和 DOM API 是什么关系,JavaScript 可以读写文件么# C++ 代码可以自动转换成 Java 代码么,任意两种语言是否可以互转# 为什么说 Python 是胶水语言,它可以用来开发 iOS/Android 么#
编译原理
就像数学是一个公理体系,从简单的公理就能推导出各种高阶公式一样,我们从最基本的 C 语言和编译说起。
int main(void) { int a = strlen(“Hello world”); // 字符串的长度是 11 return 0; }
相关的介绍编译过程的文章很多,读者应该都非常熟悉了,整个流程包括预处理、词法分析、语法分析、生成中间代码,生成目标代码,汇编,链接 等。已有的文章大多分析了每一步的逻辑,但很少谈实现思路,我会尽量用简单的语言来描述每一步的实现思路,相信这样有助于加深记忆。由于主要谈的概念和思路,难免会有一些不够准确的抽象,读者学会抓重点就行。
预处理是一个独立的模块,它放在最后介绍,我们先看词法分析。
词法分析
最先登场的是编译器,它负责前五个步骤,也就是说编译器的输入是源代码,输出是中间代码。
编译器不能像人一样,一眼就看明白源代码的内容,它只能比较傻的逐个单词分析。词法分析要做的就是把源代码分割开,形成若干个单词。这个过程并不像想象的那么简单。比如举几个例子:
int t 表示一个整数,而 intt 只是一个变量名。 int a 表示一个函数而非整数 a,int a 也是一个函数。 a = 没有具体价值,它可以是一个赋值语句,还可以是 a == 1 的前缀,表示一个判断。
词法分析的主要难点在于,前缀无法决定一个完整字符串的含义,通常需要看完整句以后才知道每个单词的具体含义。同时,C 语言的语法也不简单,各种关键字,括号,逗号,语法等等都会给词法分析的实现增加难度。
词法分析的主要实现原理是状态机,它逐个读取字符,然后根据读到的字符的特点转换状态。比如这是 GCC 的词法分析状态机(引用自《编译系统透视》):

如果自己实现的话,思路也不难。外面包一个循环,然后各种 switch…case 就完事了。词法分析应该算是最简单的一节。
语法分析
经过词法分析以后,编译器已经知道了每个单词,但这些单词组合起来表示的语法还不清楚。一个简单的思路是模板匹配,比如有这样的语句:
int a = 10;
它其实表示了这么一种通用的语法格式:
类型 变量名 = 常量;
所以 int a = 10; 当然可以匹配上这种模式。同理,它不可能匹配 类型 函数名(参数); 这种函数定义模式,因为两者结构不一致,等号无法被匹配。
语法分析比词法分析更复杂,因为所有 C 语言支持的语法特性都必须被语法分析器正确的匹配,这个难度比纯新手学习 C 语言语法难上很多倍。不过这个属于业务复杂性,无论采用哪种解决方案都不可避免,因为语法规则的数量就是这么多。
在匹配模式的时候,另一个问题在于上述的名词,比如 类型、参数,很难界定。比如int 是类型,long long 也是类型,unsigned long long 也是类型。(int a) 可以是参数,(int a, int b) 也是参数,(unsigned long long a, long long double b, int *p) 看起来能把人逼疯。
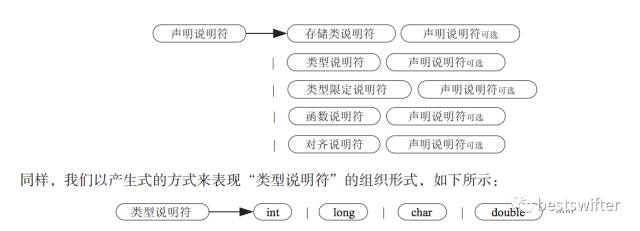
下面举一个简单的例子来解释 int a = 10 是如何被解析的,总的思路是归纳与分解。我们把一个复杂的式子分割成若干部分,然后分析各个部分,这样可以简化复杂度。对于 int a = 10 来说,他是一个声明,声明由两部分组成,分别是声明说明符和初始声明符列表。
声明 声明说明符 初始声明符列表 int a = 10 int a = 10 int fun(int a) int fun(int a) int array[5] int array[5]
声明说明符比较简单,它其实是若干个类型的串联:
声明说明符 = 类型 + 类型的数组(长度可以为 0)
而且我们知道若干个类型连在一起又变成了声明说明符,所以上述等式等价于:
声明说明符 = 类型 + 声明说明符(可选)
再严谨一些,声明说明符还可以包括 const 这样的限定说明符,inline 这样的函数说明符,和 _Alignas 这样的对齐说明符。借用书中的公式,它的完整表达如下:
成功解析语法以后,我们会得到抽象语法树(AST: Abstract Syntax Tree)。以这段代码为例:
int fun(int a, int b) { int c = 0; c = a + b; return c; }
它的语法树如下:
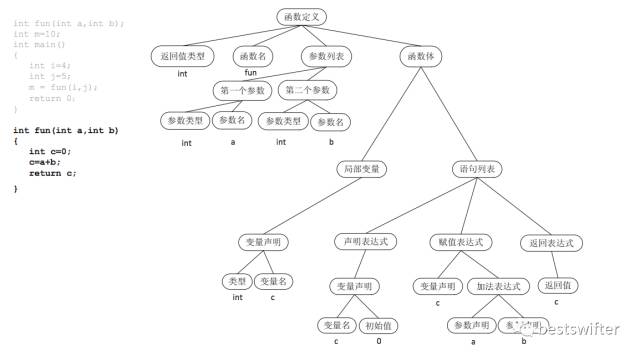
语法树将字符串格式的源代码转化为树状的数据结构,更容易被计算机理解和处理。但它距离中间代码还有一定的距离。
生成中间代码
以 GCC 为例,生成中间代码可以分为三个步骤:
语法树转高端 gimple 高端 gimple 转低端 gimple 低端 gimple 经过 cfa 转 ssa 再转中间代码
简单的介绍一下每一步都做了什么。
语法树转高端 gimple
这一步主要是处理寄存器和栈,比如 c = a + b 并没有直接的汇编代码和它对应,一般来说需要把 a + b 的结果保存到寄存器中,然后再把寄存器赋值给 c。所以这一步如果用 C 语言来表示其实是:
int temp = a + b; // temp 其实是寄存器 c = temp;
另外,调用一个新的函数时会进入到函数自己的栈,建栈的操作也需要在 gimple 中声明。
高端 gimple 转低端 gimple
这一步主要是把变量定义,语句执行和返回语句区分存储。比如:
int a = 1; a++; int b = 1;
会被处理成:
int a = 1; int b = 1; a++;
这样做的好处是很容易计算一个函数到底需要多少栈空间。
此外,return 语句会被统一处理,放在函数的末尾,比如:
if (1 > 0) { return 1; } else { return 0; }
会被处理成:
if (1 > 0) { goto a; } else { goto b; } a: return 1; b: return 0;
低端 gimple 经过 cfa 转 ssa 再转中间代码
这一步主要是进行各种优化,添加版本号等,我不太了解,对于普通开发者来说也没有学习的必要。
中间代码的意义
其实中间代码可以被省略,抽象语法树可以直接转化为目标代码(汇编代码)。然而,不同的 CPU 的汇编语法并不一致,比如 AT&T与Intel汇编风格比较 这篇文章所提到的,Intel 架构和 AT&T 架构的汇编码中,源操作数和目标操作数位置恰好相反。Intel 架构下操作数和立即数没有前缀但 AT&T 有。因此一种比较高效的做法是先生成语言无关,CPU 也无关的中间代码,然后再生成对应各个 CPU 的汇编代码。
生成中间代码是非常重要的一步,一方面它和语言无关,也和 CPU 与具体实现无关。可以理解为中间代码是一种非常抽象,又非常普适的代码。它客观中立的描述了代码要做的事情,如果用中文、英文来分别表示 C 和 Java 的话,中间码某种意义上可以被理解为世界语。
另一方面,中间代码是编译器前端和后端的分界线。编译器前端负责把源码转换成中间代码,编译器后端负责把中间代码转换成汇编代码。
LLVM IR 是一种中间代码,它长成这样:
define i32 @square_unsigned(i32 %a) { %1 = mul i32 %a, %a ret i32 %1 }
生成目标代码
目标代码也可以叫做汇编代码。由于中间代码已经非常接近于实际的汇编代码,它几乎可以直接被转化。主要的工作量在于兼容各种 CPU 以及填写模板。在最终生成的汇编代码中,不仅有汇编命令,也有一些对文件的说明。比如:
.file “test.c” # 文件名称 .global m # 全局变量 m .data # 数据段声明 .align 4 # 4 字节对齐 .type m, @objc .size m, 4 m: .long 10 # m 的值是 10 .text .global main .type main, @function main: pushl %ebp movl %esp, %ebp …
汇编
汇编器会接收汇编代码,将它转换成二进制的机器码,生成目标文件(后缀是 .o),机器码可以直接被 CPU 识别并执行。从目标代码可以猜出来,最终的目标文件(机器码)也是分段的,这主要有以下三个原因:
分段可以将数据和代码区分开。其中代码只读,数据可写,方便权限管理,避免指令被改写,提高安全性。 现代 CPU 一般有自己的数据缓存和指令缓存,区分存储有助于提高缓存命中率。 当多个进程同时运行时,他们的指令可以被共享,这样能节省内存。
段分离我们并不遥远,比如命令行中的 objcopy 可以自行添加自定义的段名,C 语言的 __attribute((section(段名)))__ 可以把变量定义在某个特定名称的段中。
对于一个目标文件来说,文件的最开头(也叫作 ELF 头)记录了目标文件的基本信息,程序入口地址,以及段表的位置,相当于是对文件的整体描述。接下来的重点是段表,它记录了每个段的段名,长度,偏移量。比较常用的段有:
.strtab 段: 字符串长度不定,分开存放浪费空间(因为需要内存对齐),因此可以统一放到字符串表(也就是 .strtab 段)中进行管理。字符串之间用
 关注微信
关注微信