
SQL中分组函数和聚合函数之前的文章已经介绍过,单说这两个函数有可能比较好理解,分组函数就是group by,聚合函数就是COUNT、MAX、MIN、AVG、SUM。
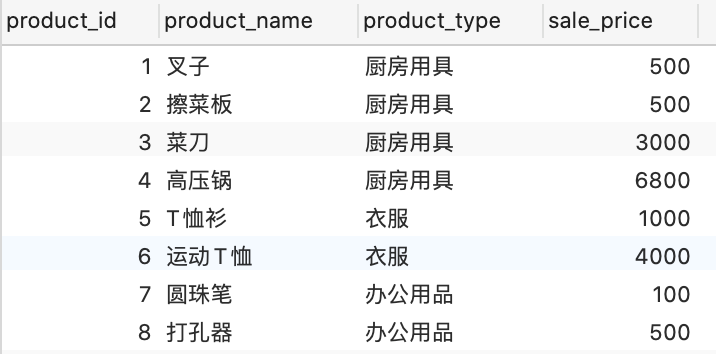
拿上图中的数据进行解释,假设按照product_type这个字段进行分组,分组之后结果如下图。
SELECT product_type from product
group by product_type
从图中可以看出被分为了三组,分别为厨房用具、衣服和办公用品,就相当于对product_type这个字段进行了去重,确实group by函数有去重的作用。
SELECT DISTINCT product_type from product假设分组之后,我想看一下价格,也就是sale_price这个字段的值,按照如下这个写法,会报如下错误。
SELECT product_type,sale_price from product
group by product_type
这是为什么呢?原表按照product_type分组之后,厨房用具对应4个值,衣服对应2个值,办公用品对应2个值,这就是在取sale_price这个字段的时候为什么报错了,一个空格中不能填入多个值,这时候就可以用聚合函数了,比如求和,求平均,求最大最小值,求行数。聚合之后的值就只有一个值了。
SELECT product_type,sum(sale_price),avg(sale_price),count(sale_price),max(sale_price) from product
group by product_type

对于多个字段的分组,其原理是一样的。从上述中记住两点:分组去重和分组聚合。
distinct只是为了去重,而group by是为了聚合统计的。
单个字段去重
--DISTINCT
SELECT distinct product_type from product
--GROUP BY
select product_type from product
GROUP BY product_type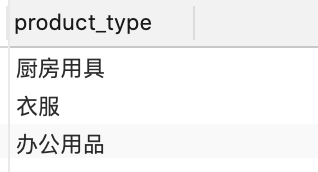
多个字段去重
--DISTINCT
SELECT distinct product_name, product_type from product
--GROUP BY
select product_name, product_type from product
GROUP BY product_name, product_type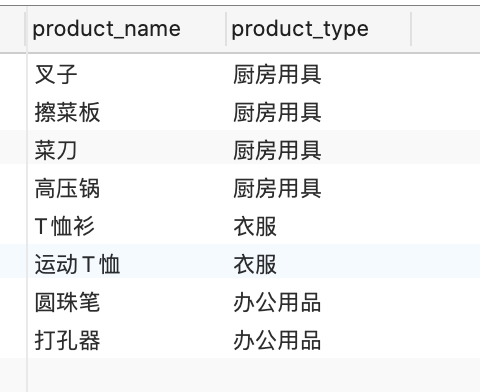
执行效率
select <列名1>,<列名2>
from<表名>
where 查询条件
group by 分组类别
having 对分组结果指定条件
order by <列名> (desc)
limit 数字
SQL语言的运行顺序,先执行上图中的第一步,然后再执行select子句,最后对结果进行筛选。distinct是在select子句中,而group by在第一步中,所以group by去重比distinct去重在效率上要高。
 关注微信
关注微信