
语音信号处理的目的就是在复杂的语音环境中提取有效的语音信息。
技术思想及原理分析
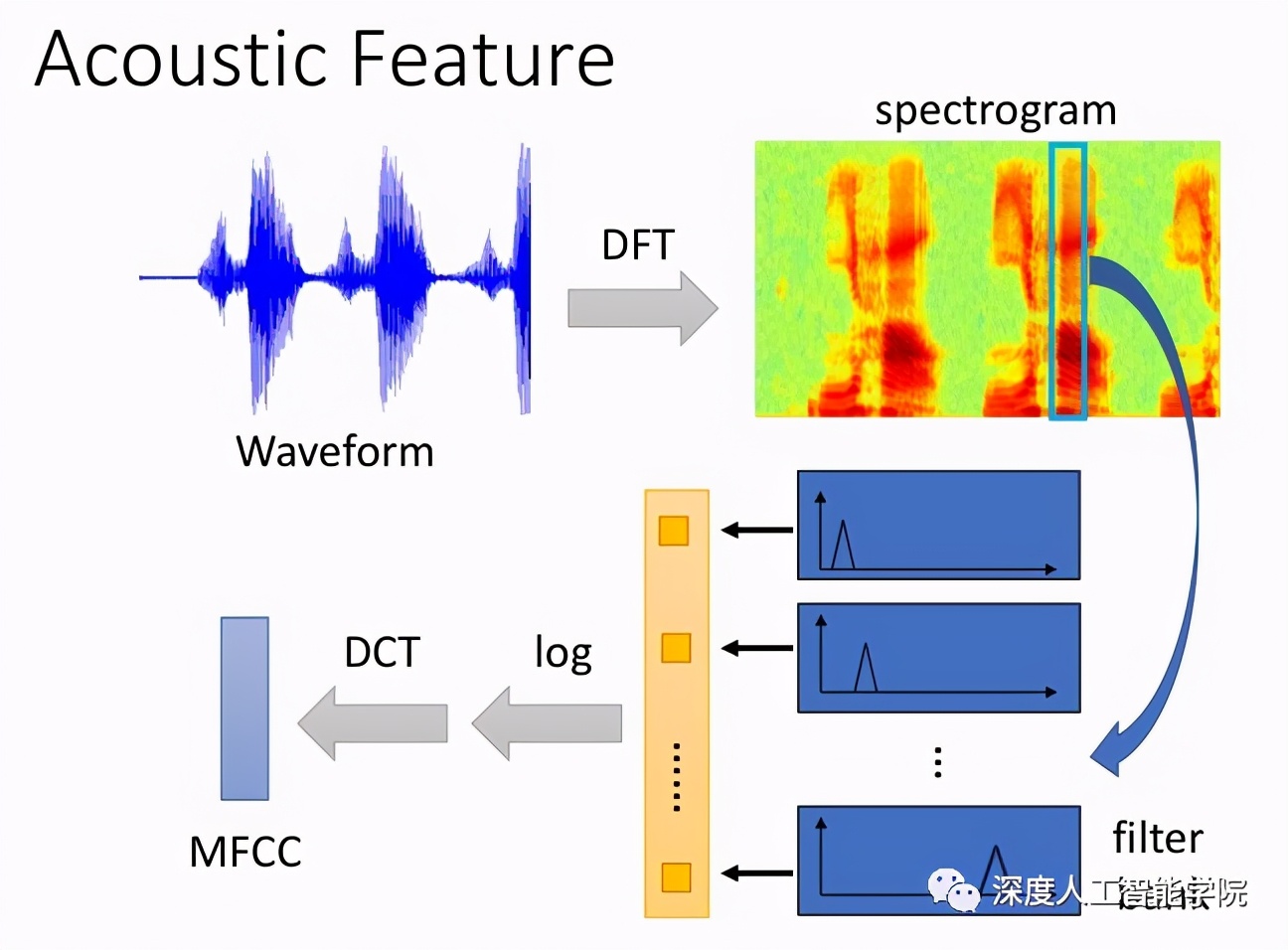
语音唤醒的原理是让模型学习特定唤醒词的语音信号特征,当输入设备捕捉到一定阈值范围内的语音信号时,当前设备将会被唤醒,否则平时设备都处于待机状态。比如小米音箱这款产品,我们在使用的时候,一般都会喊一声“小爱同学”,然后再让它执行我们的命令,比如换一首歌,或者减小音量。这个“小爱同学”所发出的语音信号就是模型要学习的标签,当模型学到一定的标签数量时,下次再听到这个标签的声音时,就会做出反应,设备也就被唤醒了。语音唤醒的方法有很多,有基于传统机器学习的方法,也有基于深度学习的方法,这里只分享一些目前比较流行的深度学习方法,比如有基于CNN的Keyword Spotting模型、基于CRNN的Keyword Spotting模型、基于SEQ2SEQ的Keyword Spotting模型等。无论是那种方法,一般会将先语音波形图转成频谱图,频谱图通过Mel滤波器组得到Mel频谱,然后在Mel频谱上进行倒谱分析,获得Mel频率倒谱系数MFCC,MFCC就是语音的特征;这时候,语音就可以通过一系列的倒谱向量来描述了,每个向量就是每帧的MFCC特征向量。这样就可通过这些倒谱向量对语音分类器进行训练和识别了。
应用场景及商业价值
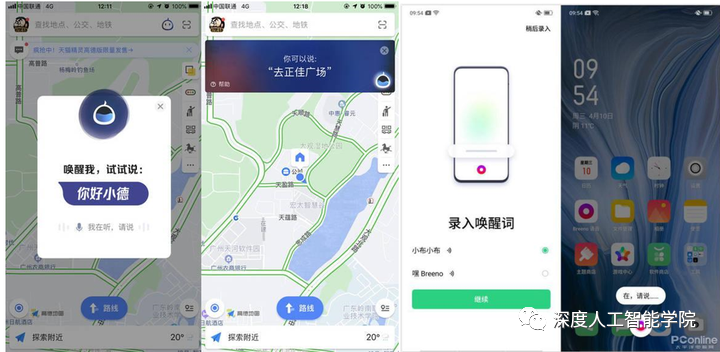
目前市场上几乎所有的智能语音产品都有语音唤醒装置,在执行任何一句命令之前,都要加上一个关键词来唤醒设备,其主要功能在于更好地执行命令,以及节能和延长设备使用寿命,如果一台语音设备没有唤醒装置,就意味着它无时无刻都是开机状态的,想要对它发号施令,就要求设备的智能程度非常高才行,不然设备很难判断你是在对它发号施令,还是在和你的朋友聊天,另外一直开机对能源的消耗和设备的使用寿命都损耗不少。
技术思想及原理分析
语音命令顾名思义就是对智能设备发号施令,然后让它执行。前面在介绍语音唤醒的时候提到过,语音唤醒和语音命令的关系,语音唤醒是让设备处于工作状态下,然后才会执行语音命令。所以语音命令一定是语音唤醒之后的工作,不然语音命令将变得毫无意义。语音命令主要是一些简短的语音词汇所组成的信息,比如打开台灯、关闭台灯、灯光调亮一点、灯光条暖一点等等类似这样的带有动词的词汇都可以算是命令性词汇。其处理原理和过程也是和语音唤醒是一样的,都是通过对人发出的声波经过一系列的变化而得到的语音信号特征,最后对特征进行分类处理。

应用场景及商业价值
语音命令的应用在日常生活中也很常见,比如生活中常见的手机导航、Windows电脑程序导航、小米音箱、百度地图导航,以及一些K12的教育产品,基本都是以语音命令来控制程序的。语音命令控制程序的优势是方便快捷,对于老人和小孩,以及上肢行动不便的人更为方便。

技术思想及原理分析
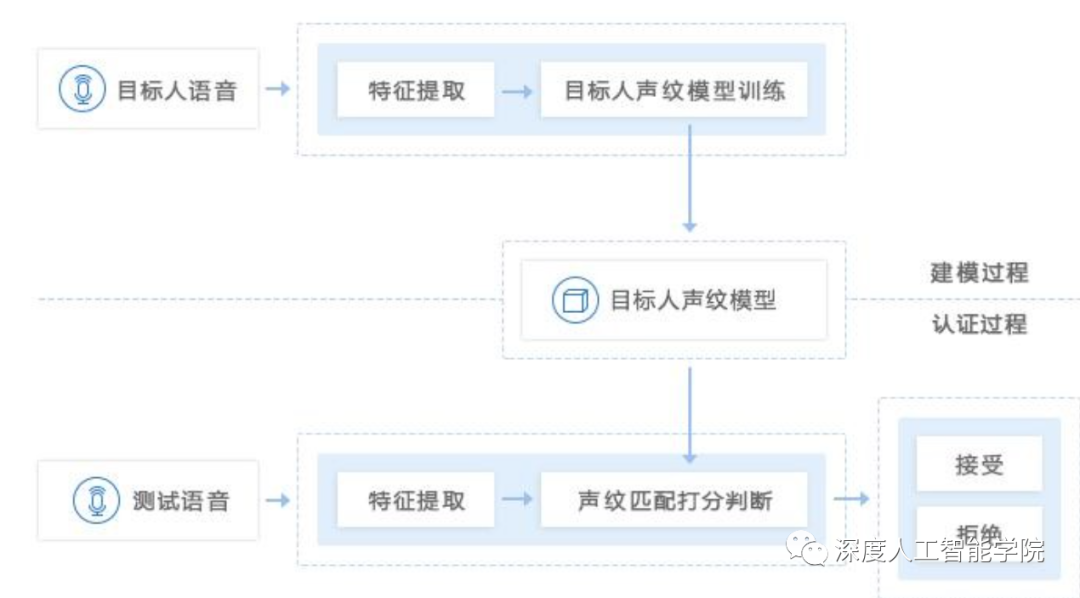
声纹识别是对一个人发出的声音和存留的声音进行匹配,声纹识别作为一种生物信息被应用在各种程序中作为识别密码。它和指纹识别、人脸识别一样,在识别前,首先需要对被识别人的识别信息进行采样存库,方便以后对比识别。在深度学习中,声纹识别和语音唤醒、语音命令等其他语音操作方式一样,都是先对接收到的声波进行转换,得到频谱图,进而使用梅尔频谱倒数分析,进行特征提取。
应用场景及商业价值
声纹识别的应用主要用在一些用户信息登录识别验证等敏感的场景,其作用和键盘输入识别验证、指纹识别验证、人脸识别验证的一样。声纹识别对环境的要求较高,一般来说比较安静的环境发声识别效果较好;反之,如果环境嘈杂,则识别验证的效果较差。另外一个人的声音是随着年龄、身体状况的变化而变化的,所以并不是很稳定。虽然声纹识别有一些缺点,但是也有其优点,主要是声音获取相对容易,只要环境较为安静,声音的验证也更方便,使用者接受程度较高。

技术思想及原理分析
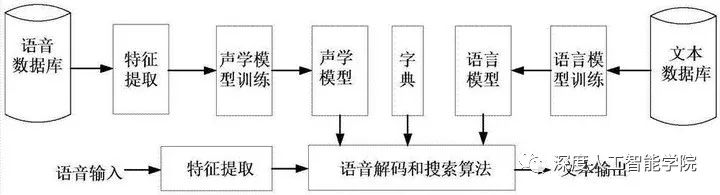
语音识别就是对发出的语音进行一系列的转换,从波形图最终翻译成对应的文字信息,这个过程中有一个中间的特征来对应两边的语音和文本。简单来说就是先把语音转成某种特征图,然后让特征图对应到文本信息上。由于是从声音转换成文本,也称为STT(speech to text)。语音转文本的具体技术和语音唤醒使用的技术一样,先要把波形图转成频谱图,然后根据梅尔频率倒谱系数进行特征提取,有了特征就可以对应指定的文本信息了。
应用场景及商业价值
语音识别的好处是,可以代替键盘快速输入文本信息。比如在某些聊天软件上和对方沟通时,想要发送给对方的是文字信息,但是又不方便键盘输入,这个时候就可以使用语音识别技术来自动将语音转换成文字后再发送。此外,广义的语音识别包括了所有的语音操作技术,包括语音唤醒、语音命令等一系列和语音相关的技术。
技术思想及原理分析
语音合成与语音识别的应用方向刚好相反,语音识别是STT(speech to text),而语音合成是TTS(text to speech),从二者的名称中就可以看出,语音合成的输入是文本信息,输出是声音信息。在技术上可以看成是STT的逆向操作。目前的语音合成方法主要有拼接合成语音和参数合成语音两种。
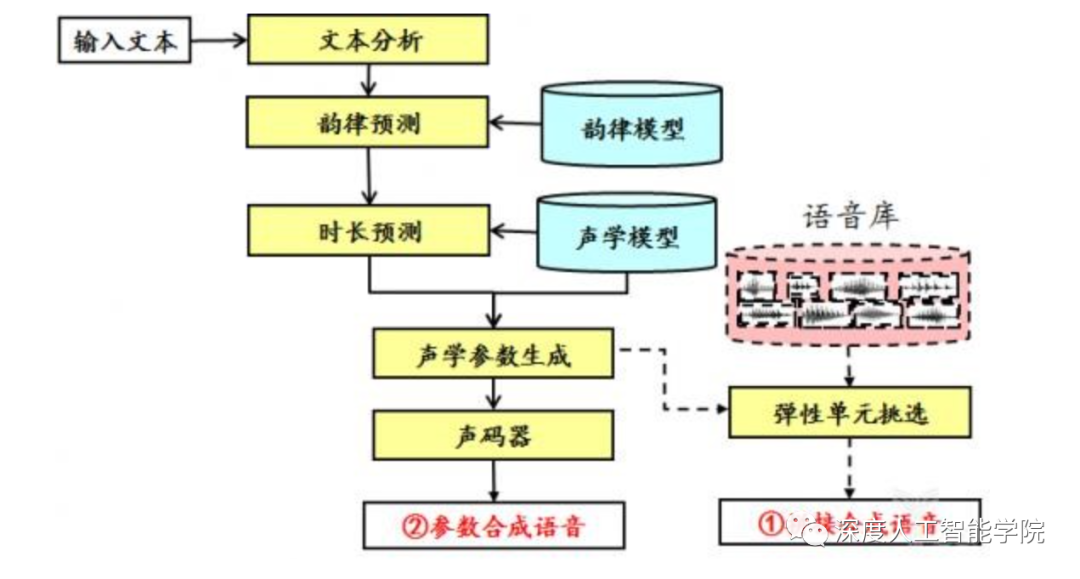
应用场景及商业价值
虽然目前的语音合成技术还不是非常成熟,但是在一些要求不太高的应用中已经开始应用了。目前语音合成的应用主要在新闻广播行业较为广泛,比如搜狗AI合成主播,有了AI合成主播,就可以帮助新闻机构做一些简单的广播了。当然国外有人拿这个技术配合上图像合成技术,造了一段总统讲话的视频,表情和声音还都挺像的,不仔细甄别,还真看不出来。

 关注微信
关注微信