
前言
学习一个新知识最好的方式就是上官网,所以我先把官网贴出来 MySQL官网 (点击查阅),如果大家有想了解我没有说到的东西可以直接上官网看哈~目前 MySQL 最新大版本为8.0,但是鉴于目前应用比较多的还是 5.7,所以今天在这里还是针对 5.7 来做讨论。
看了官网关于 MySQL 的介绍之后,我发现一个有趣的事情。在我身边的同事,很多都是把 MySQL 读错了,当然,也是因为大家已经约定俗成了,所以我卖的关子是,MySQL 大家一般会都成 my sequel,但是在官网上读法是这样的[ My Ess Que Ell ],即把 s q l 分开来读。当然这个不重要啦,这里只是跟大家唠嗑一下哈哈~想验证的伙伴可以点击这个What is MySQL#
下面开始进入正题:
下面是 MySQL 的发展过程,目前的系统基本上都是分布式微服务的了,由于支持事务的特性,所以 innodb 为默认的存储引擎,也是我们今天课程的主角。(MyISAM 和 Innodb 的区别在此不做赘述,想了解 MySQL 的引擎可至 MySQL 引擎链接查阅。
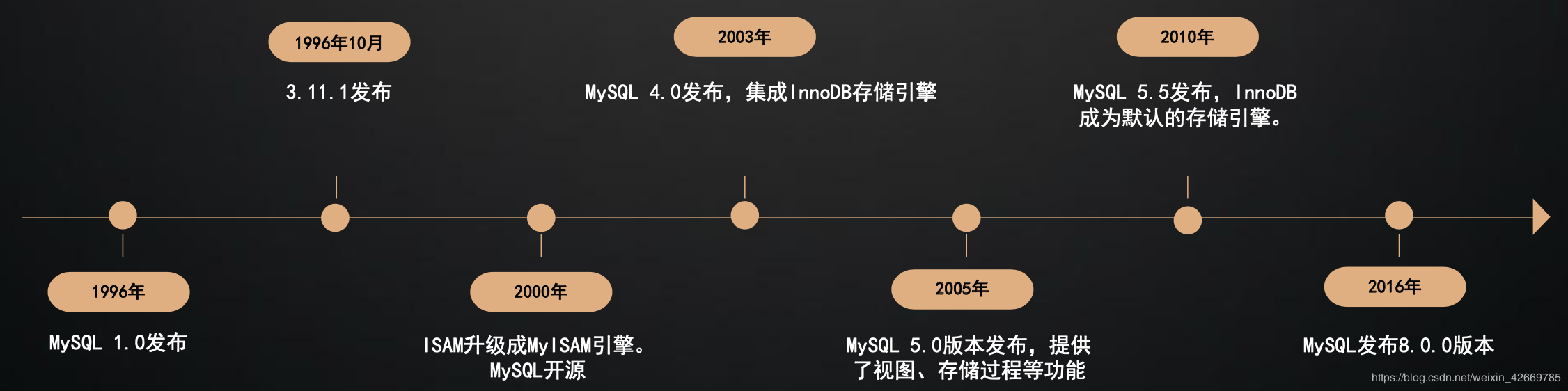
接下来我们会以这张脑图的一些知识点展开来讲,但是由于文章篇幅有限,有些点可能只会一笔带过,有兴趣的小伙伴可以到我的公众号下与我留言讨论。
我们今天的重点,在于将 MySQL 语句的执行流程给大家梳理一遍(如果文章哪里有疏漏的话,尽请大家批评指正)。
一条查询语句是如何执行的
查询语句的执行分为以下几步:
通过如下语句可查看缓存开关情况(默认关闭):
show variables like 'query_cache%';在 MySQL 中默认是关闭的,官方也建议关闭,将缓存交托给第三方如 redis 处理,为啥:
1.语法解析
语法解析是解析你的语句是不是满足 MySQL 语法标准,如果不对则会 :
ERROR 1064 (42000): You have an error in your SQL syntax … 关于错误码在官网有说明
2.词法解析
关于解析完生成的解析树类似下图,我以’select name from user_info where sex=1 and age>20’为例:
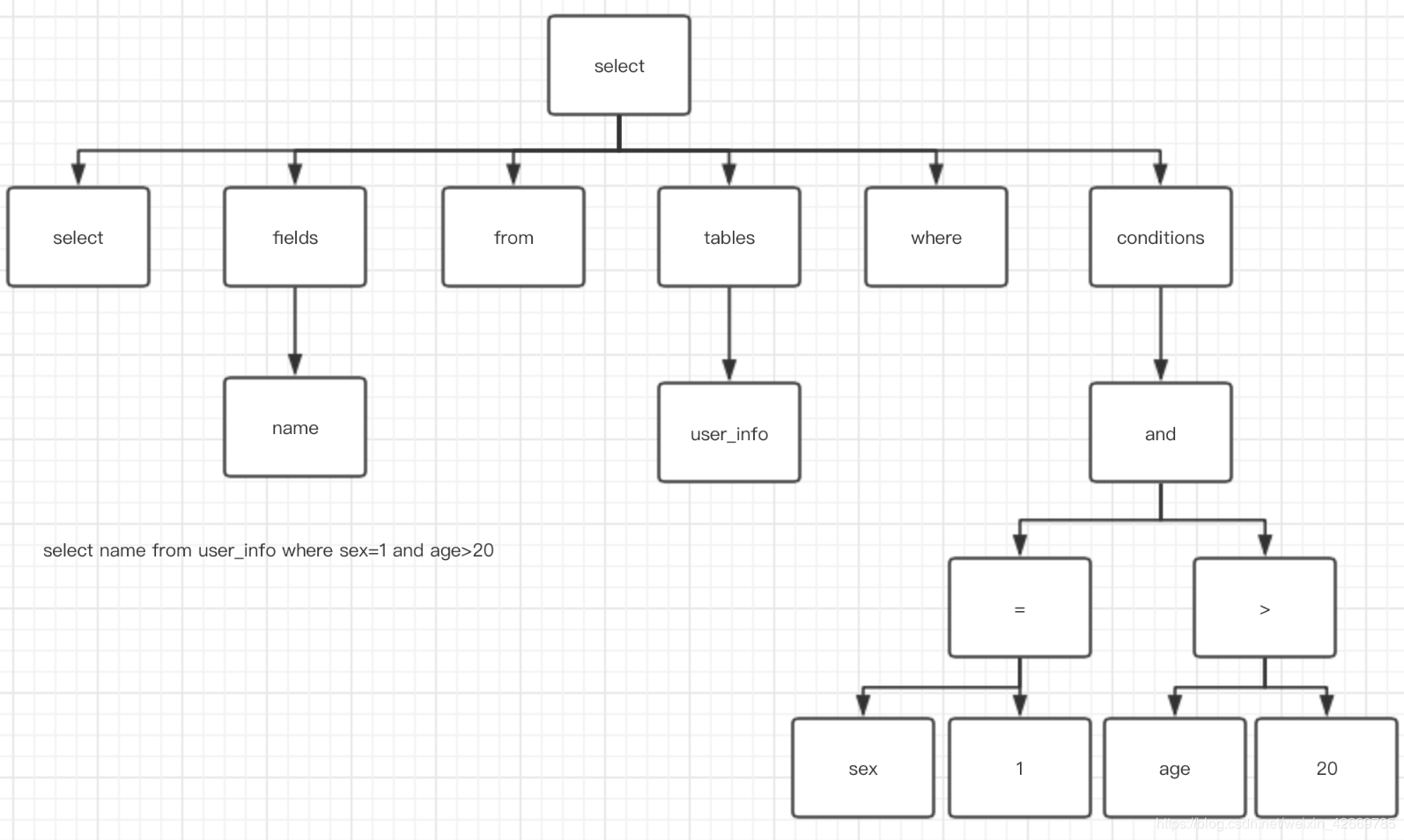
语义解析,在语法及词法解析完之后,进行预处理之后再次生成解析树。
在这一步将前面生成的解析树优化成一个执行计划。
在这步做的事情主要有:
顺便提一下,optimizer_trace 优化器追踪器,在 MySQL 中是默认关闭的(毕竟开启也会消耗性能嘛对吧),可以使用 set 语句修改一下 optimizer_trace的开关,感受一下:
set optimizer_trace='enabled=on '先查询优化器追踪的开关:
show variables like 'optimizer_trace%';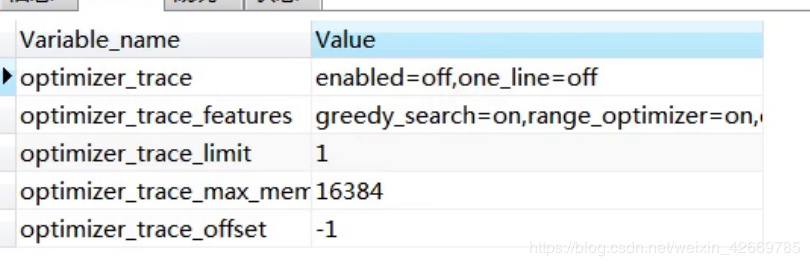
执行完一条语句之后执行下面语句查看优化器追踪:
select * from information_schema.optimizer_traceG可以看到一个 json 类型的字符串,主要是语句优化的三个阶段,篇幅有限,这里不展开,对照着看应该可以看懂。

查询最后一次查询的消耗,用以比较开销:
show status like 'Last_query_cost';在这一步选择开销最小的计划执行
这里执行器会先对权限做一个判断,如果有权限,才会执行以下步骤,否则跑出权限异常:
将查询数据的结果返回给查询的客户端,如果有缓存则返回缓存(前面已经说了默认关闭),可以说就大功告成了哈哈哈哈,真是曲折。
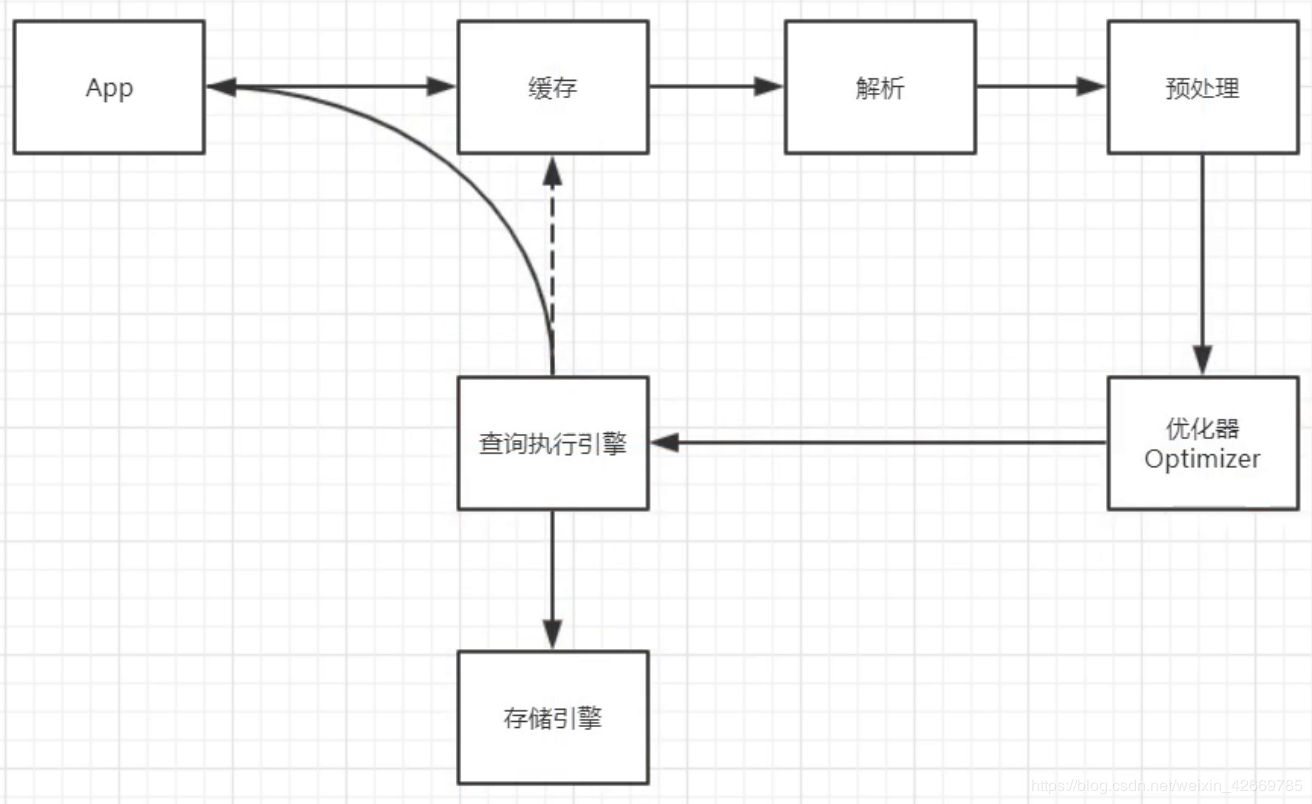
经过上面一系列的梳理,相信大家对 MySQL 查询语句的流程也有了一个大致的了解,下面是针对查询语句的流程做的一张图,方便大家记忆理解:
 关注微信
关注微信