
流数据处理,同时提供与批处理对应物相比的诸如新鲜度和更顺畅的资源消耗的益处,历史上与不可靠且具有近似结果的缺点相关。然而,这些缺点不是流媒体数据处理本身的固有特征,而是如何实现它们先前已经实现的文物。如Google Cloud DataFlow和Apache Beam近年来所示,流处理可以与批处理一样稳健。在本博客文章中,我们将讨论如何使流媒体数据处理强大。这里有很多想法都是基于磨机,据说谷歌云数据流建立。
人们对流媒体数据处理的鲁棒性的主要担忧似乎围绕分布式系统中的公共部分失败情景居中,例如机器故障和网络中断。对于批处理,我们可以在部分故障时始终重新运行整个操作,最终重试后批处理将成功。但在流化处理中,重试看起来像什么?它会丢弃数据或创建重复数据吗?它会伤害流化处理的可扩展性和性能吗?
要回答这些问题,我们可以放大单个计算步骤。流数据处理可以被认为是由许多步骤组成的管道。如果我们可以保证单个计算步骤的稳健性,我们可以概括为整个管道。请注意,我们还需要一个跟踪所有计算并监视整个流水线的逻辑上集中控制服务。但我们不会有时间进入细节。
让我们看一下抽象级别的单个计算步骤,以便我们的讨论的结论可以应用于流媒体数据处理中的任何类型的工作。禁止,计算从上游输入,计算结果,并在下游发送结果,如图1所示。
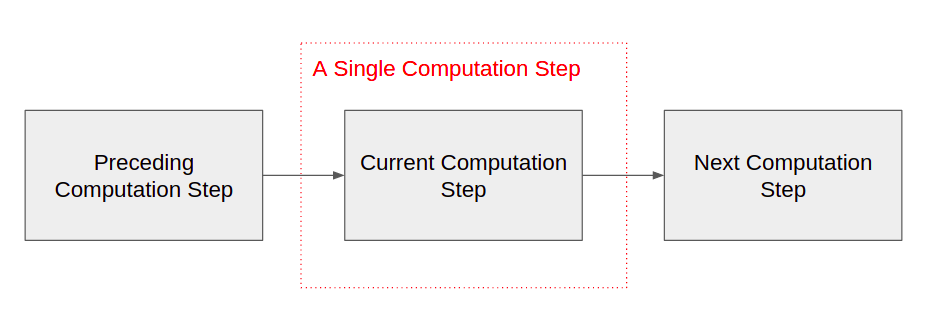
> Figure-1
我们首先假设计算没有外部副作用,如发送电子邮件,递增外部计数器等。否则我们无法保证流媒体处理本身的鲁棒性,因为我们必须能够在失败时重新运行计算。如果存在这样的外部副作用,则通常是一个糟糕的设计标志。有时,这是必要的,在这种情况下,用户需要在流处理外部进行副作用。现在我们已经确定了计算可以根据我们想要的多次重试,我们只需要重新运行它,直到我们知道它成功。
接下来,我们需要确保我们不会在旧数据上重新运行它,因为它将产生重复的结果。我们为每个数据点分配唯一ID。计算存储处理后的数据点ID。每当计算执行时,它将首先检查其存储,以确保它以前没有看到数据点。如果计算已经看到了数据点,则会立即确认上游,以发信号点已处理数据点。显然,我们必须清理旧数据点ID以保存存储空间。我们稍后会得到那么一点。作为延迟优化,我们可以依赖于绽放过滤器来检查以前的计算是否已看到此数据点。如果数据点ID不在盛开过滤器中,我们知道它是一个新的数据点。Bloom过滤器会大大减少对存储的查询。请注意,计算需要根据重新启动时基于其存储重新填充绽放过滤器。
最后,我们需要确保我们可靠地在下游交付结果。一旦计算完成处理数据点,它将在其存储中存储结果。请注意,计算检查数据点ID和原子统一地将数据点ID和结果一致至关重要。之后,它在上游确认并将结果下游发送。计算重试,按顺序发送结果,直到下游确认。
有关一个计算的整体生命周期和潜在的故障情景,请参阅图2。
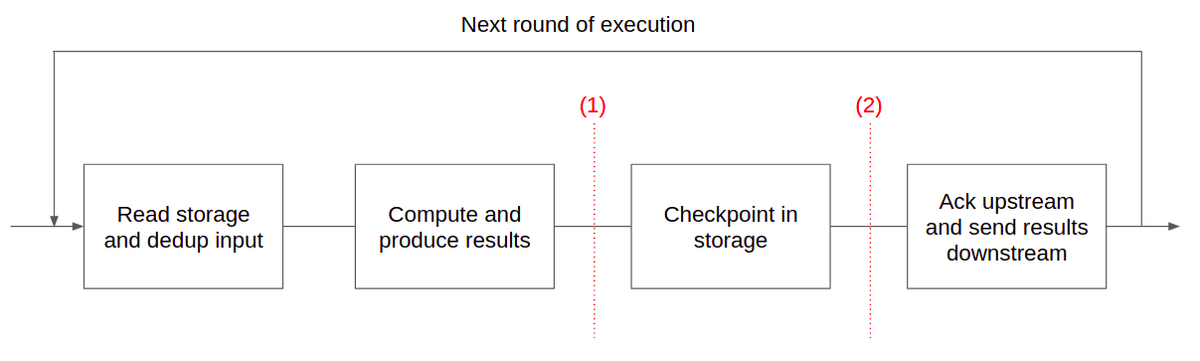
> Figure-2. If the computation fails before (1), it starts overs. The write to storage is atomic so the next potential failure point is (2). After that, the checkpoint is persisted, the computation can restart by reading the checkpoint into memory, and proceed from (2).
有一点值得注意的是,在分布式系统中,没有可靠地检测失败的东西。因此,即使将计算视为失败,也可能发生这种情况,它实际上仍然是活动的,以可能与新启动的实例冲突的方式写入存储。处理此操作的一种方法是使用写入租赁来调解对存储的访问。控制服务为每个计算分配租约。如果控件服务认为计算已死亡,则它使租赁使租赁失效并为新实例生成新的。由于无效租约,僵尸计算的残余写入将被击落。
作为吞吐量优化,我们可以拨入数据点信息的处理和存储。无需单独做。至于底层存储系统,Bigtable会符合良好。在Bigtable中写入单行是原子的。我们可以将单个计算的所有内容作为单个文档写入。Bigtable并不能提供强烈的一致性。但无论如何,我们都不需要。我们只需要读写的写一致性,因为计算不需要从其他人的存储内容中读取。签出此博客文章[链接]如果您想了解有关分布式系统的一致性的更多信息。
我们之前提到过,我们不想无限期地存储检查点(数据点ID和结果)。所以我们需要一种机制来清理它们。结果清理很简单。一旦计算从下游接收到ACK,它就可以丢弃相应的结果。数据点ID清理有点棘手。
要管理数据点ID的生命周期,我们需要在流流程管道中建立时间戳的概念。每个数据点都与时间戳固有相关。它可能是来自外部来源的时间。例如,当流流管线正在将日志文件作为输入进行拖尾时,可以使用日志条目的时间戳。如果我们在流流程管线中生成数据点,它也可能是从内部的时间。例如,当计算产生结果数据点时,它可以将当前壁时间分配为时间戳。
只是为了把炸弹伸出右:无论我们愿意等待多久,都可能总是有延迟数据点。想想从手机收集日志的用例,用户可以在发送所有本地日志之前打开飞机模式。我们何时无法预测,最后一架飞机将降落。
因此,在流媒体管道的摄取侧,我们必须使用启发式来确定我们是否已经看到所有数据到达某个时间戳。我们称之为低水印。例如,我们说我们将等待3天Max,在这种情况下,当前时间减去3天是管道摄入的低水印。对于每个计算步骤,低水印是前一步的低水印的最小值和当前步骤中未处理数据点的最旧的时间戳。有关插图,请参见图-3。
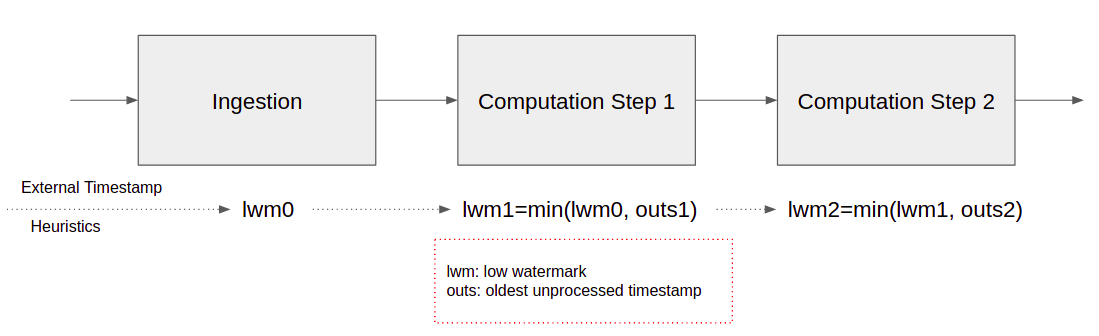
> Figure-3
一旦低水印通过了商店数据点ID的时间戳,就可以清理那些数据点ID。这里的含义是我们还需要将时间戳存储为每个数据点ID。请注意,无需额外的写入清除存储。一旦计算对存储的数据点ID和结果有更新,它可以将其滚动到下一轮执行检查点。
即使对于单个计算步骤,我们也需要扩展到多台机器。在我们可以将上述单个计算扩展到在多台机器上并行运行之前,存在一些实际的考虑因素。
首先,我们需要一种方法来确定/发送数据点到当前计算步骤的实例。否则,前面步骤中的重传可以使数据点在不同的当前步骤实例中多次处理数据点,从而导致结果。这可以通过拍摄数据点ID的一致哈希来完成。显然,前面的计算步骤的每个实例需要知道能够适当地路由数据点的当前步骤的所有实例的地址。
当前步骤的每个实例都在一致哈希空间中的一系列值负责。如果特定范围的值变得过于流行,则相应的实例将在重负载下。让我们来看看拆分炎热实例的程序。有关插图,请参见图-4。
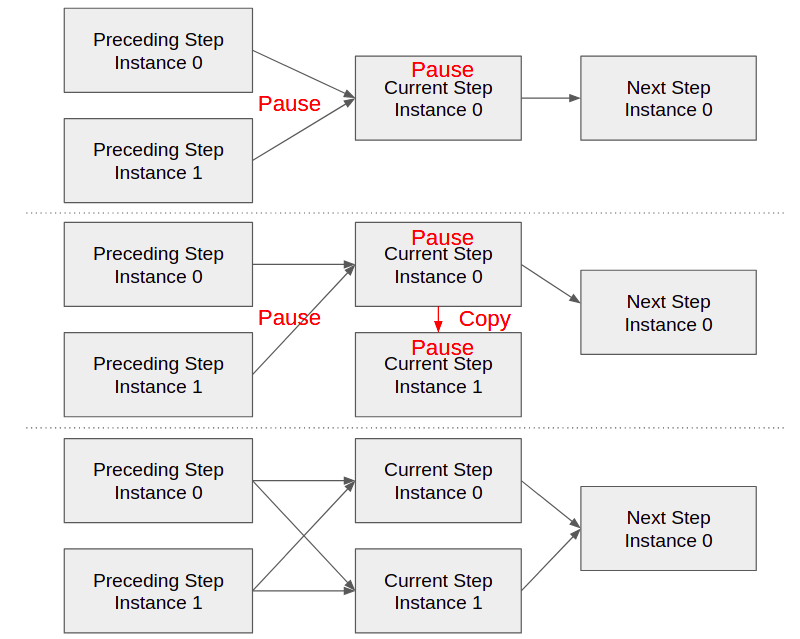
> Figure-4
如果上述任何过程未能完成,则控制服务重试直至成功。它应该简单看出,可以以几乎相同的方式完成添加更多实例或减少实例。
希望流媒体数据处理现在较少。而且你现在至少打开了可以使流数据处理可以稳健的想法。有关更多系统设计理念,请查看此列表[链接]。
 关注微信
关注微信