

ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childOption(ChannelOption.TCP_NODELAY, true)
.childAttr(AttributeKey.newInstance("childAttr"), "childAttrValue")
.handler(new ServerHandler())
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ch.pipeline().addLast(new AuthHandler());
//..}});
ChannelFuture f = b.bind(8888).sync();
f.channel().closeFuture().sync();
复制代码netty初始化线程,创建一个 boss线程池,一个work线程池,并且给new了一个channel处理注册线程的连接,并且为这个channel 添加了一个 ServerBootstrapAcceptor的channel。
新连接的建立可以分为三个步骤 1.检测到有新的连接 2.将新连接注册到work线程组 3.注册新连接的读事件
BOSS线程组的 NioEventLoop.run() 不断检查所有的管道,当管道状态为可读或者连接的时候就会读取管道。
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
unsafe.read();
}
复制代码然后就按 Channel 的责任链传递下去
DefaultEventExecutorChooserFactory.java
用线程个数取余来分配
@Override
public EventExecutor next() {
return executors[Math.abs(idx.getAndIncrement() % executors.length)];
}
AbstractChannel.java
@Override
public final void register(EventLoop eventLoop, final ChannelPromise promise) {
// 重点!!! 这个线程就永远被挂靠在channel上面了
AbstractChannel.this.eventLoop = eventLoop;
// 监听读事件 NIO底层的注册
register0(promise);
}
}
复制代码ChannelInboundHandler.channelRead
ChannelInboundHandler.channelRead
总结:Netty通过开始注册一个Boss线程池(通常情况都是一个),来监听(NioEventLoop,run)连接的channel,如果有channel来进行连接,就通过责任链找到
ServerBootstrapAcceptor.channelRead() 分配给channel一个线程(NioEventLoop),这个线程(NioEventLoop)就会通过run()去不断的 去读Channel里面的,处理命令。
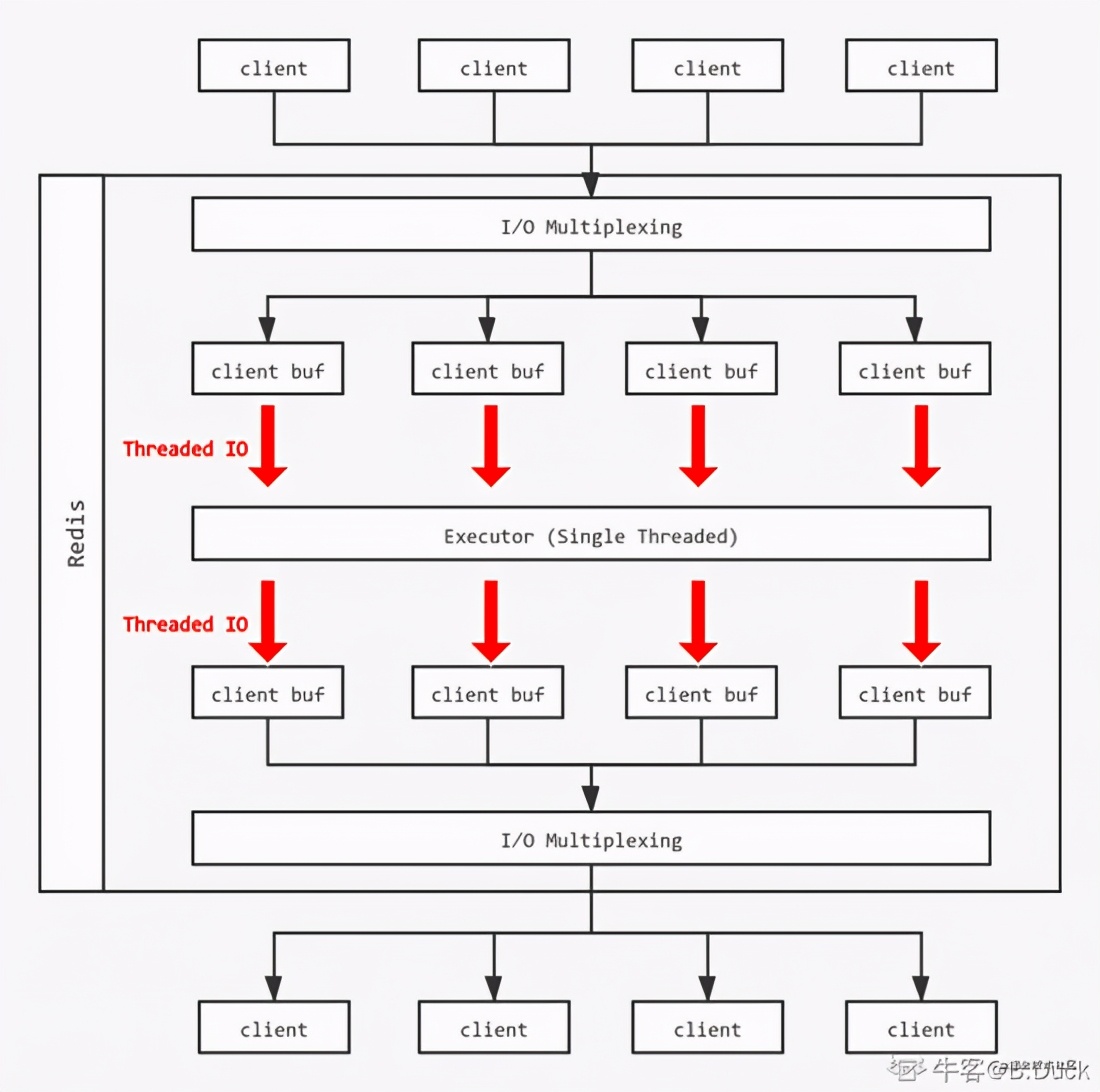
首先,如果用户没有开启多线程IO,也就是 io_thread_num ==1,按照单线程处理; 如果超过线程数IO_THREADS_MAX_NUM上限则异常退出。
创建io_threads_num个线程(listCreate),并且对除主线程(id==0)以外的线程进行处理: (listCreate 创建一个线程)
/* Initialize the data structures needed for threaded I/O. */
void initThreadedIO(void) {
io_threads_active = 0; /* We start with threads not active. */
/* Don't spawn any thread if the user selected a single thread:
* we'll handle I/O directly from the main thread. */
// 如果用户没有开启多线程IO直接返回 使用主线程处理
if (server.io_threads_num == 1) return;
// 线程数设置超过上限
if (server.io_threads_num > IO_THREADS_MAX_NUM) {
serverLog(LL_WARNING,"Fatal: too many I/O threads configured. "
"The maximum number is %d.", IO_THREADS_MAX_NUM);
exit(1);
}
/* Spawn and initialize the I/O threads. */
// 初始化io_threads_num个对应线程
for (int i = 0; i < server.io_threads_num; i++) {
/* Things we do for all the threads including the main thread. */
io_threads_list[i] = listCreate();
if (i == 0) continue; // Index 0为主线程,跳过
/* Things we do only for the additional threads. */
// 非主线程则需要以下处理
pthread_t tid;
// 为线程初始化生成对应的锁
pthread_mutex_init(&io_threads_mutex[i],NULL);
// 线程等待状态初始化为0
io_threads_pending[i] = 0;
// 初始化后将线程锁住
pthread_mutex_lock(&io_threads_mutex[i]);
if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize IO thread.");
exit(1);
}
// 将index和对应线程ID加以映射
io_threads[i] = tid;
}
}
复制代码Redis需要判断是否满足 Thread IO 条件,执行 postponeClientRead,执行后会将 Client放到等待读取的队列,并将Client设置为等待读取的状态。
// 读取到一个客户端的请求
int postponeClientRead(client *c) {
if (io_threads_active && // 线程是否在不断(spining)等待IO
server.io_threads_do_reads && // 是否多线程IO读取
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ)))
{//client不能是主从,且未处于等待读取的状态
// 将Client设置为等待读取的状态Flag
c->flags |= CLIENT_PENDING_READ;
// 把client加入到等待读列表
listAddNodeHead(server.clients_pending_read,c);
return 1;
} else {
return 0;
}
}
复制代码这时server维护了一个 clients_pending_read,包含所有的读事件 pending的客户端列表。
首先,Redis检查有等待的读Client listLength(
server.clients_pending_read)
如果是长度不为0,进行while循环,将每个等待的client分配给线程,当等待长度超过线程时, 每个线程分配给到的client可能超过1个;
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 在线程组取余
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
并且修改每个线程需要完成的数量(初始化为0):
// 所有线程
for (int j = 1; j < server.io_threads_num; j++) {
// 拿出当前线程需要处理多少个客户端
int count = listLength(io_threads_list[j]);
// 设置当前线程需要多少客户端
io_threads_pending[j] = count;
}
等待处理直到没有剩余任务:
while(1) {
unsigned long pending = 0;
// 拿出所有线程,查看线程是否还有需要的客户端
// 这里主要是监听子线程是否完全处理好任务
for (int j = 1; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
当本次IO的所有(读/写)线程处理完毕之后,清空client_pending_read:
主线程会在这里处理命令
listRewind(server.clients_pending_read,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_READ;
if (c->flags & CLIENT_PENDING_COMMAND) {
c->flags &= ~ CLIENT_PENDING_COMMAND;
processCommandAndResetClient(c);
}
processInputBufferAndReplicate(c);
}
listEmpty(server.clients_pending_read);
复制代码在上面过程中,当任务分发完毕后,每个线程按照正常流程将自己负责的Client的读取缓冲区的内容进行处理,和原来的单线程没有太大差异。
Redis为每个客户端分配了输入缓冲区,它的作用是将客户端发送的命令临时保存,同时Redis从会输入缓冲区拉取命令并执行,输入缓冲区为客户端发送命令到Redis执行命令提供了缓冲功能。
Redis的 Thread IO 模型中,每次所有的线程都只能进行或者 写/读 操作,通过 io_threads_op控制。 同时每个线程负责的client一次执行:
// io thread主函数,在各个子线程执行
void *IOThreadMain(void *myid) {
// 线程 ID,跟普通线程池的操作方式一样,都是通过 线程ID 进行操作
long id = (unsigned long)myid;
while(1) {
/*
*这里的等待操作比较特殊,没有使用简单的 sleep,
*避免了 sleep 时间设置不当可能导致糟糕的性能,
*但是也有个问题就是频繁 loop 可能一定程度上造成 cpu 占用较长
*/
for (int j = 0; j < 1000000; j++) {
if (io_threads_pending[id] != 0) break;
}
// 根据线程 id 以及待分配列表进行 任务分配
listIter li;
listNode *ln;
listRewind(io_threads_list[id],&li);
// 有可能分配了两个客户端连接
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
if (io_threads_op == IO_THREADS_OP_WRITE) {
// 当前全局处于写事件时,向输出缓冲区写入响应内容
writeToClient(c,0);
} else if (io_threads_op == IO_THREADS_OP_READ) {
// 当前全局处于读事件时,从输入缓冲区读取请求内容
readQueryFromClient(c->conn);
} else {
serverPanic("io_threads_op value is unknown");
}
}
listEmpty(io_threads_list[id]);
io_threads_pending[id] = 0;
if (tio_debug) printf("[%ld] Donen", id);
}
复制代码readQeuryFromClient()->processInputBuffer(c)->processCommand() 进行command的分发和处理。
这里的readQueueFromClient只做写入客户端的输入缓存区:
// 复制到 Client 缓存区
else if (c->flags & CLIENT_MASTER) {
c->pending_querybuf = sdscatlen(c->pending_querybuf,
c->querybuf+qblen,nread);
}
void processInputBuffer(client *c) {
while(c->qb_pos < sdslen(c->querybuf)) {
// 如果我们在 IO线程(子线程)的时候
// 我们不能直接执行命令,flags设置为CLIENT_PENDING_COMMAND
// 然后让主线程执行
if (c->flags & CLIENT_PENDING_READ) {
c->flags |= CLIENT_PENDING_COMMAND;
break;
}
}
}
复制代码每个线程执行readQueryFromClient,将对应的请求放入一个队列,单线程执行(从输入缓存区读取内容),线程将结果写入客户端的buff中。
void startThreadedIO(void) {
if (tio_debug) { printf("S"); fflush(stdout); }
if (tio_debug) printf("--- STARTING THREADED IO ---n");
serverAssert(io_threads_active == 0);
for (int j = 1; j < server.io_threads_num; j++)
// 解开线程的锁定状态
pthread_mutex_unlock(&io_threads_mutex[j]);
// 现在可以开始多线程IO执行对应读/写任务
io_threads_active = 1;
}
复制代码void stopThreadedIO(void) {
// 需要停止的时候可能还有等待读的Client 在停止前进行处理
handleClientsWithPendingReadsUsingThreads();
if (tio_debug) { printf("E"); fflush(stdout); }
if (tio_debug) printf("--- STOPPING THREADED IO [R%d] [W%d] ---n",
(int) listLength(server.clients_pending_read),
(int) listLength(server.clients_pending_write));
serverAssert(io_threads_active == 1);
for (int j = 1; j < server.io_threads_num; j++)
// 本轮IO结束 将所有线程上锁
pthread_mutex_lock(&io_threads_mutex[j]);
// IO状态设置为关闭
io_threads_active = 0;
}
复制代码总结:Threaded IO将服务读Client的输入缓存区和将执行结果写入输出缓冲区的过程改为了多线程模型, 同时保持同一时间全部线程均处于读或写的状态。但是命令的具体执行以单线程(队列)的形式。 因为Redis希望保持坚定结果避免锁和竞争问题,并且读写缓存占用命令执行声明周期的比重比大 ,处理这部分IO模型给性能带来来显著的提升。
netty:当Boss监听到连接事件,netty会给一个channel分配一个线程。这个线程专门负责这条channel的读写事件,可以是解析也可以是执行命令
redis6:每当接收到一个读事件,Client放到等待读取的队列。在执行处理事件之后,主线程会 统一给线程池的线程分配client。线程把client要读buffer都放到client的缓存。主线程等待所有 io线程执行完毕,主线程再执行client的缓存变成命令
netty:在子线程执行,读写完直接执行逻辑 redis6:在子线程执行,读写完放在client的缓冲区
netty:在子线程执行,直接执行逻辑 redis6:在主线程执行,主线程遍历等待队列读取缓冲区编译成命令再执行

 关注微信
关注微信