
语法: create table if not exists 表名 ( 字段名 数据类型(null | not null,default | auto_increment,primary key,comment,varchar,), 字段名 数据类型 … ) engine=存储引擎 charset=字符编码
| 数据类型 | 含义 |
| null,not null | 是否为空 |
| default | 默认值 |
| auto_increment | 自动增长,默认1开始,每次递增1 |
| primary key | 主键 |
| comment | 备注 |
| varchar | 字符串 |
| engine | 引擎,有myisam、innodb |
如果表名和字段名用了关键字,特殊符号,要用反引号括起来。 例:



小结:
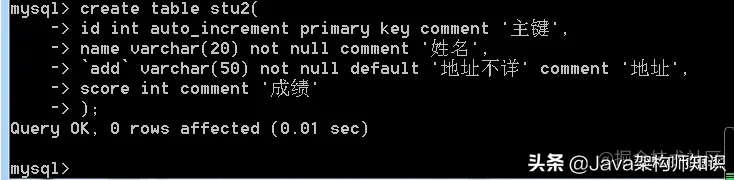

一个数据库对应一个文件夹,一个表对应两个个或多个文件,主要取决与引擎,引擎是innodb,生成一个文件。引擎是myisam生成3个文件:
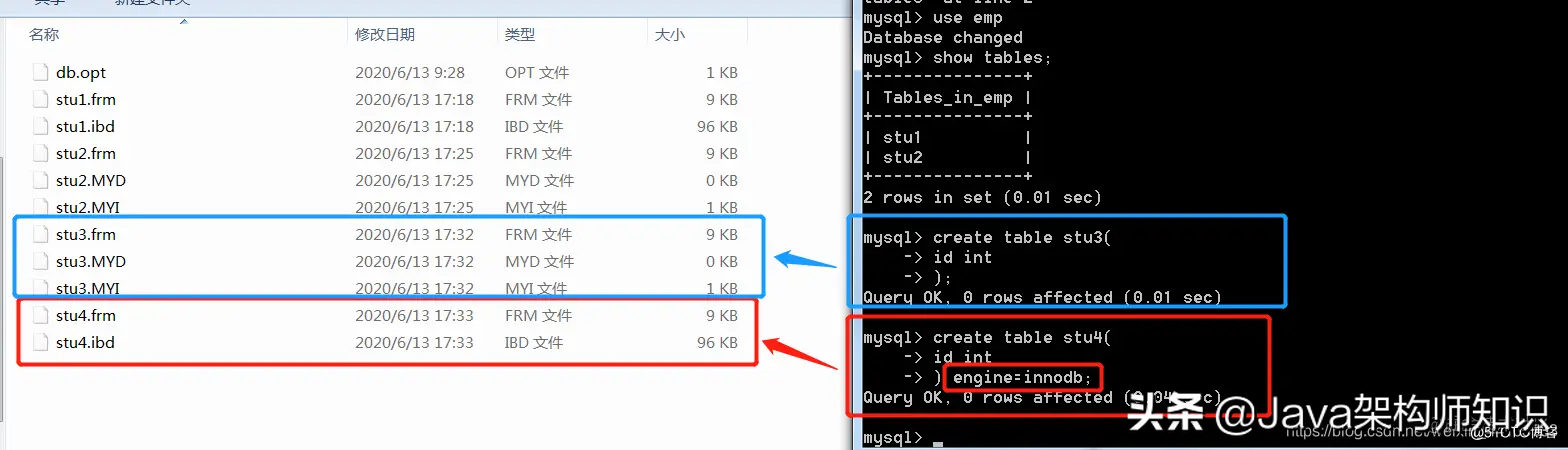

innodb和myisam的区别:
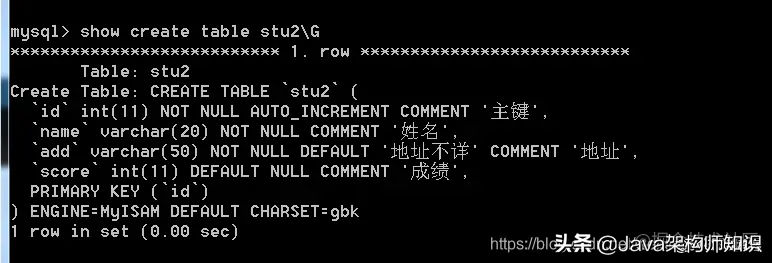
语法: show create table stu2;
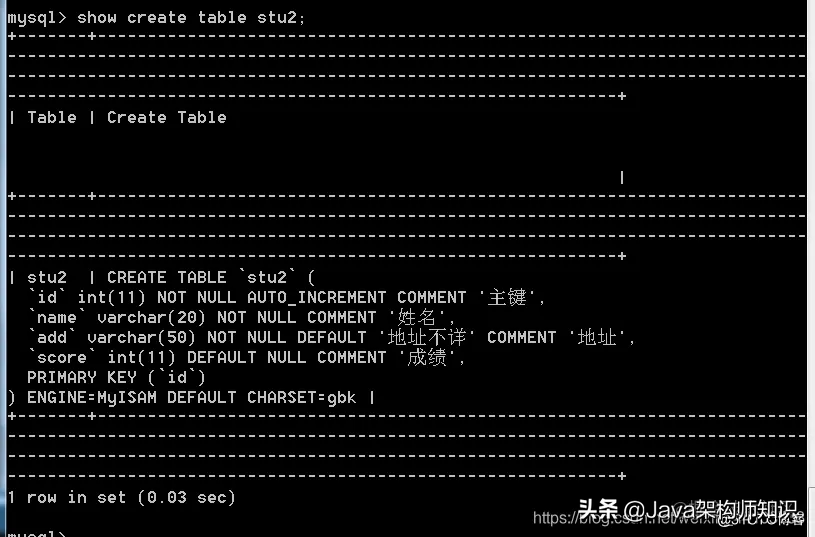

还可以 show create table stu2G 查询:

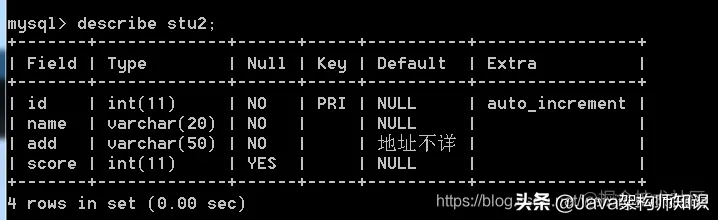
语法: describle 表名;

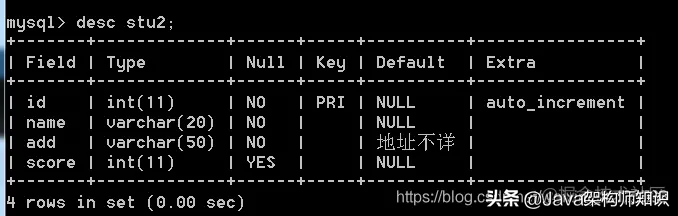
可以简写为: desc 表名;

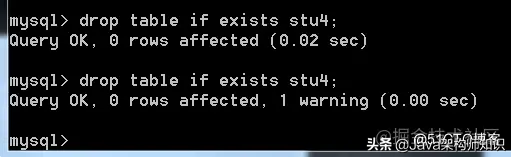
语法: drop table if exists 表1,表2,…;

语法一: create table 新表 select 字段 | * from 旧表; 特点:不能复制父表的键,能够复制父表的数据。不写字段,写*号代表复制所有字段。


但是注意主键没有复制。
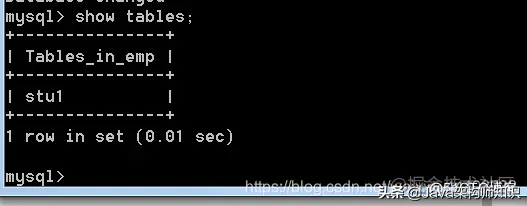
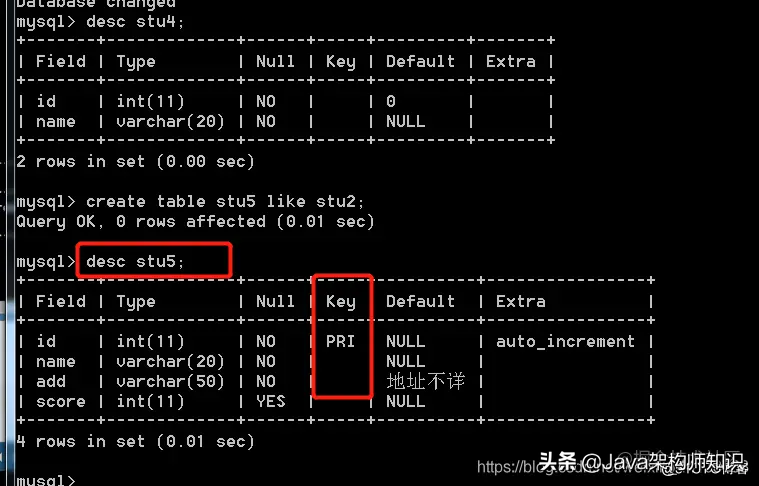
语法二: create table 新表 like 旧表; 特点: 只能复制表结构,不能复制表数据。


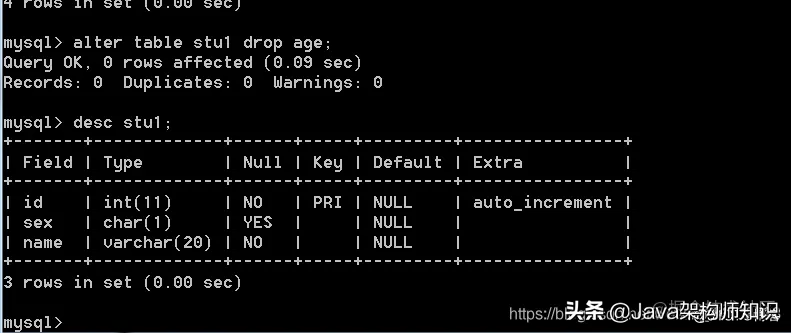
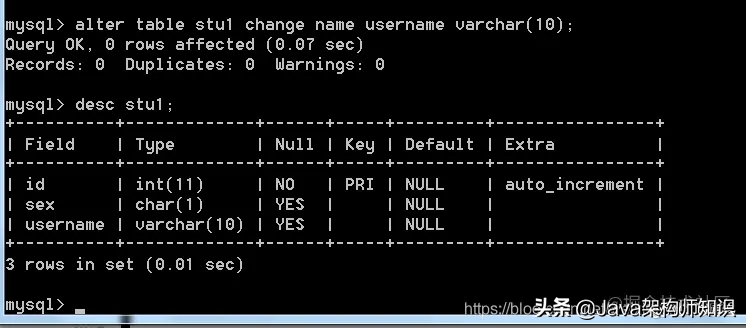
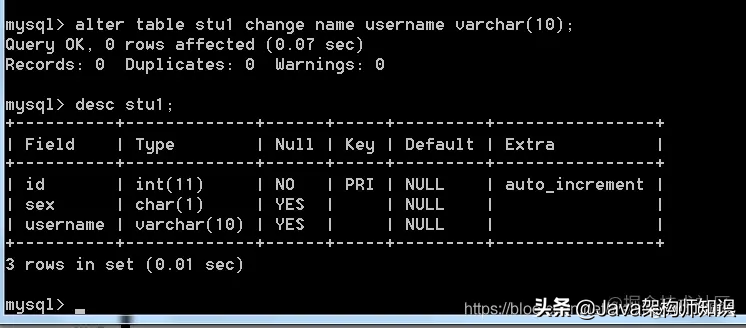
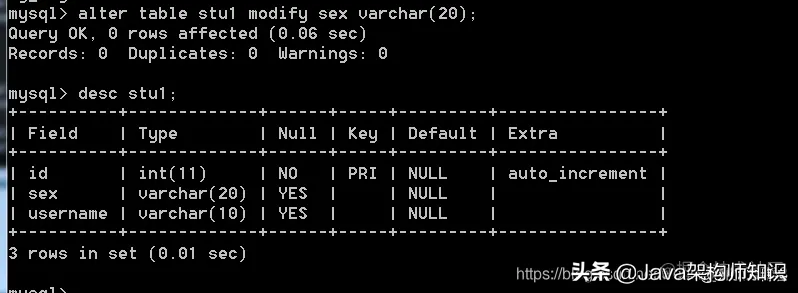
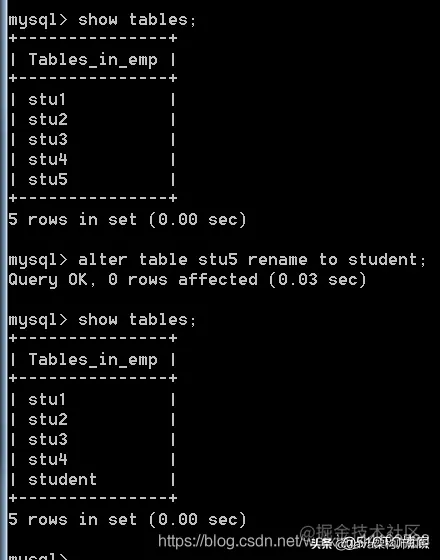
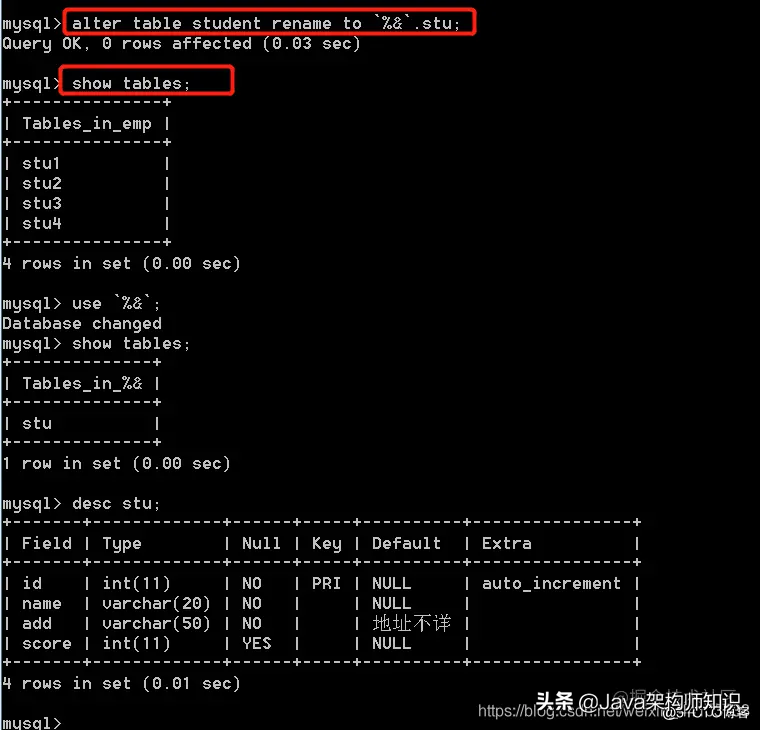
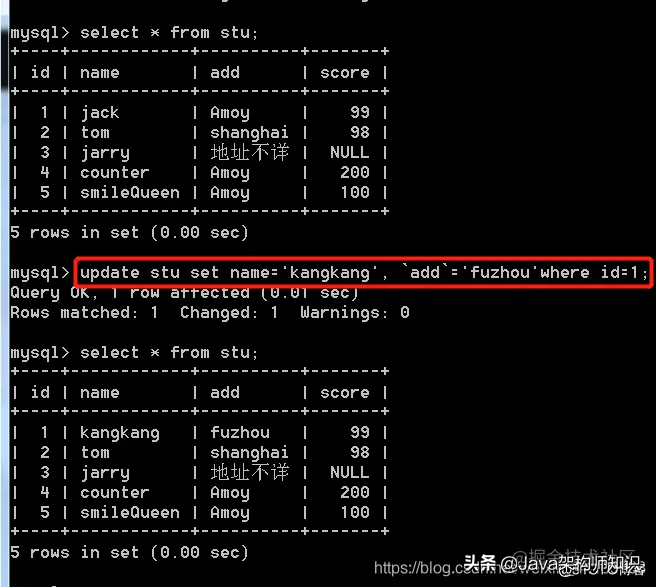
语法: alter table 表名;
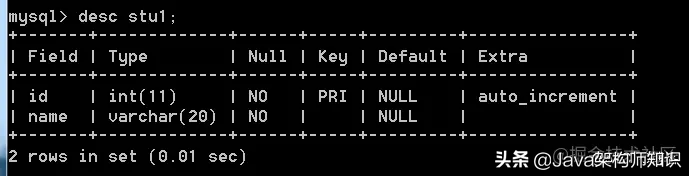

我们以stu1为例,进行修改:
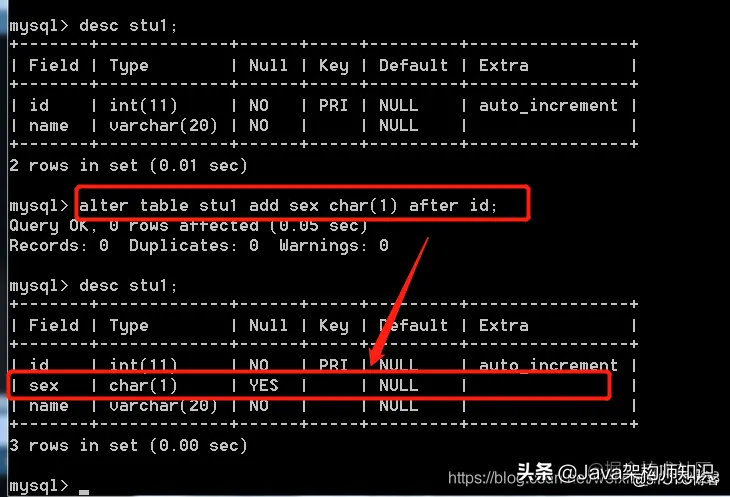

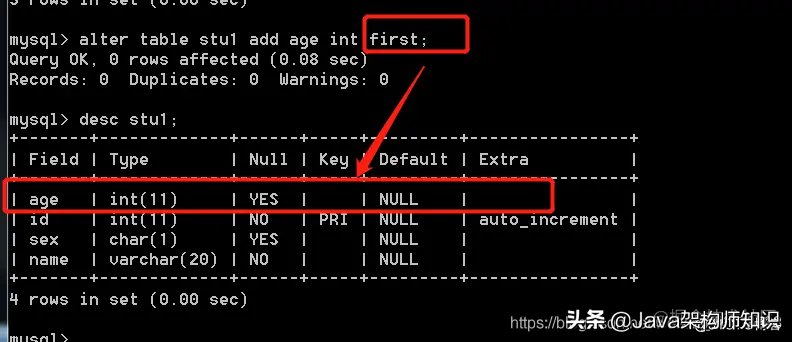


就两个位置关键字,after ,first。





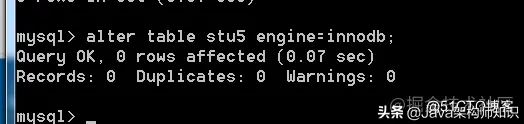
现在stu5的引擎为myisam,现在给他修改为innodb。






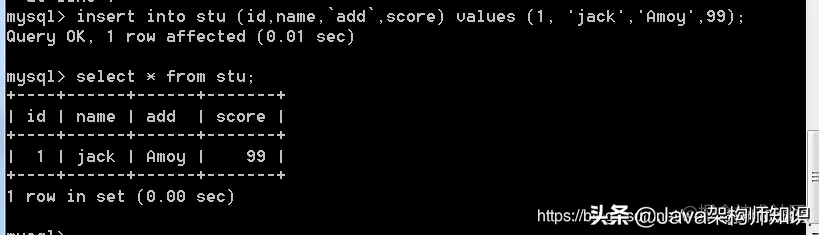
语法: insert into 表名(字段名,字段名,…) values(值1,值2,…);
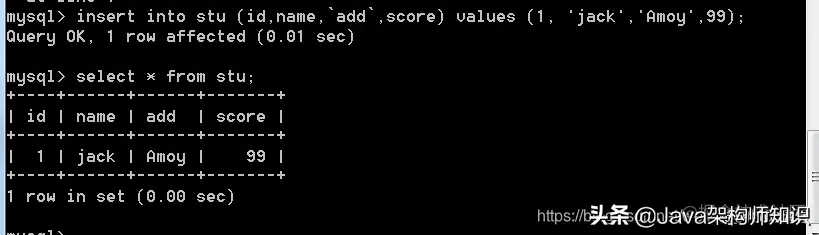

字段名可以省略,代表全有字段有需要插入,不过在values值那里,必须要与字段关系一一对应:
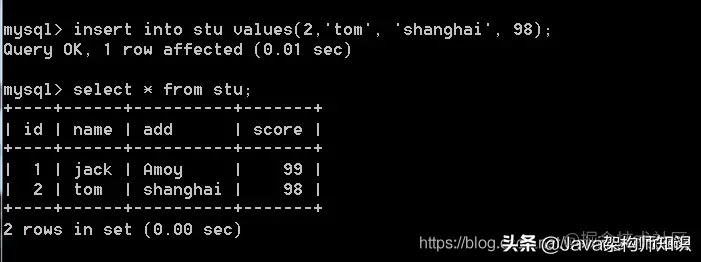

当字段为空值时,写null,为默认值时写default:
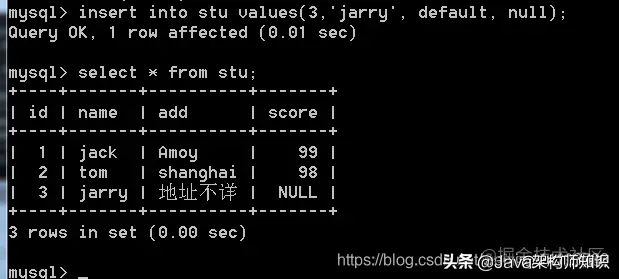

插入多个数据:
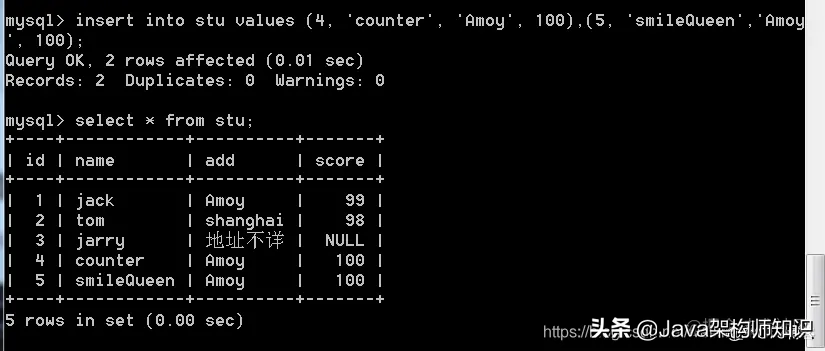

语法:select 列命 | * from 表名;

语法: update 表名 set 字段=值 [where 条件]
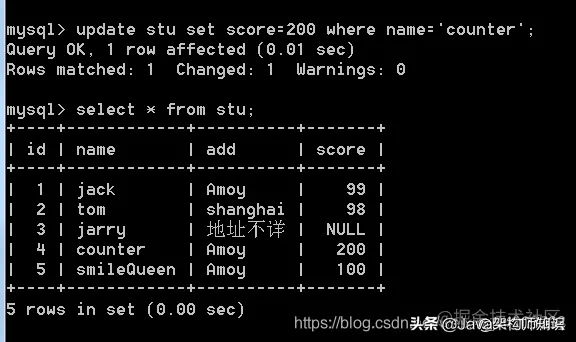

更新多个:

语法:delete from 表名 [where 条件];


删除表中所有数据:delete from 表名 ; 或者 truncate table 表名;
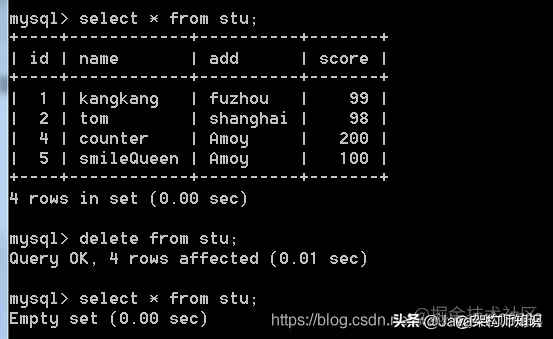

两者区别:delete from 表:遍历表记录,一条一条的删除,truncate table:将原表销毁,在创建一个同结构的新表,就情空表而言,这种方法效率高。
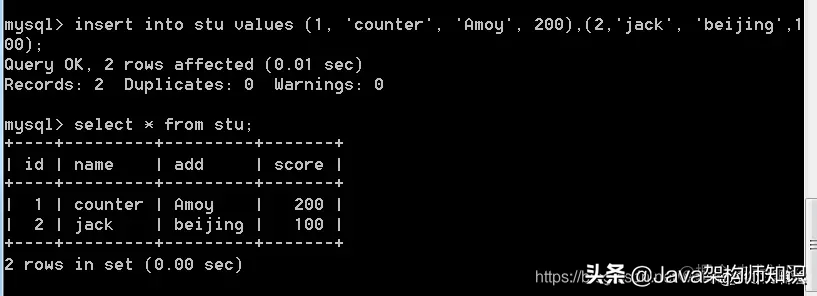
我们再插入几条数据:

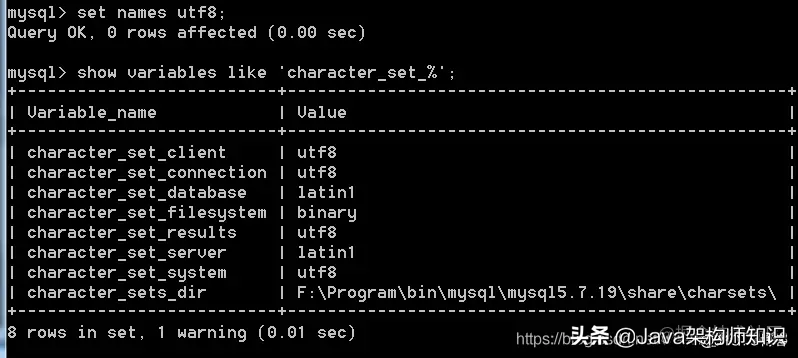
在插入数据的时候,如果插入中文,如果报错了,或者中文无法插入。 查看客户端发送的编码:
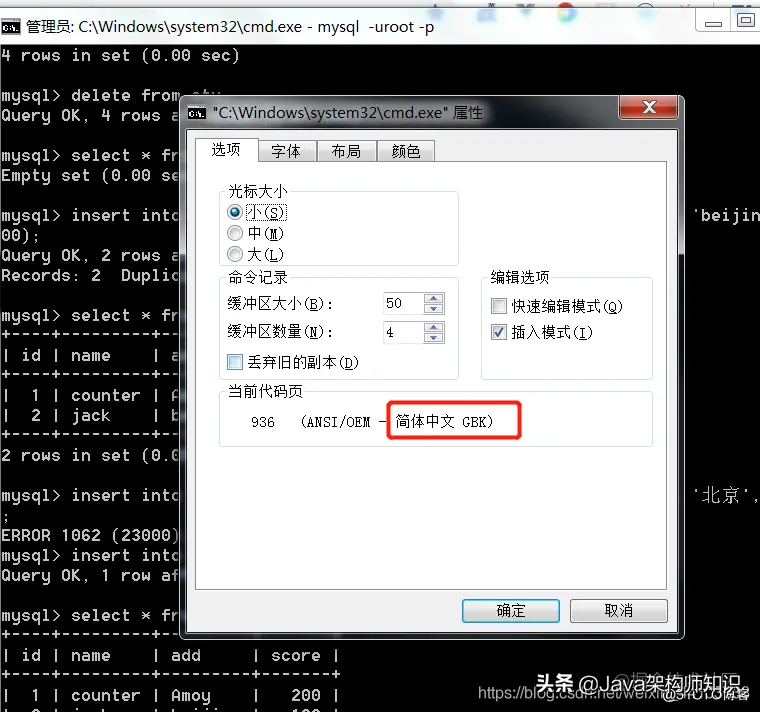

当前默认是gbk。
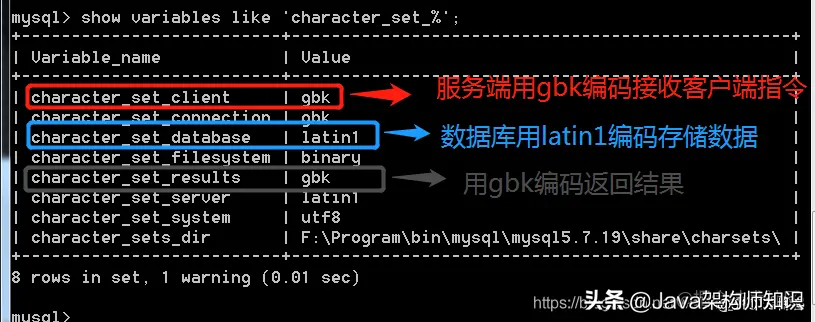
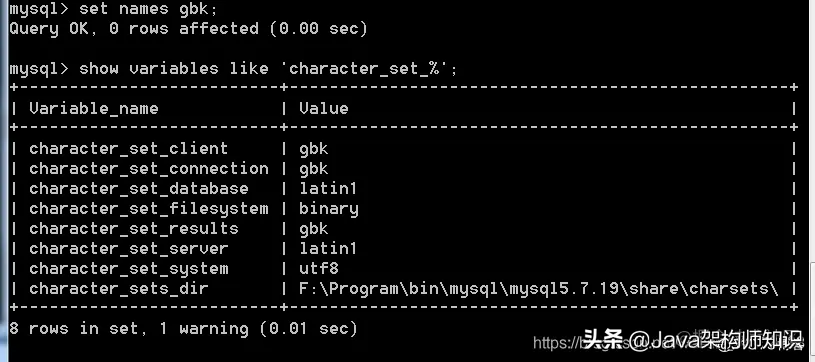
查看服务器接收返回的编码: show variables like ‘character_set_%’;

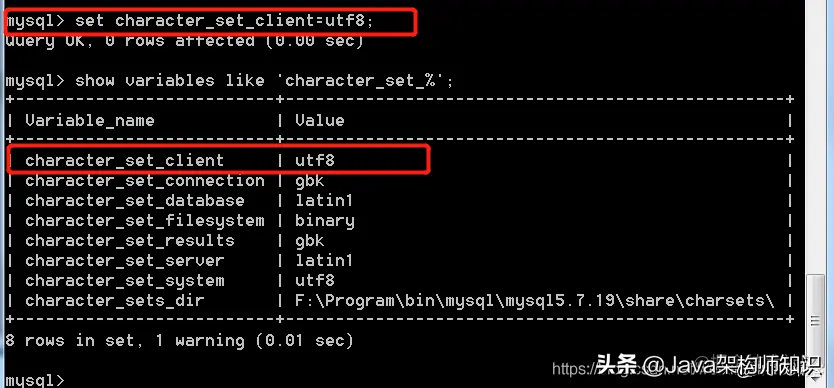
更改接收客户端指令编码: set character_set_client=编码格式; :

接着我们去存入中文:
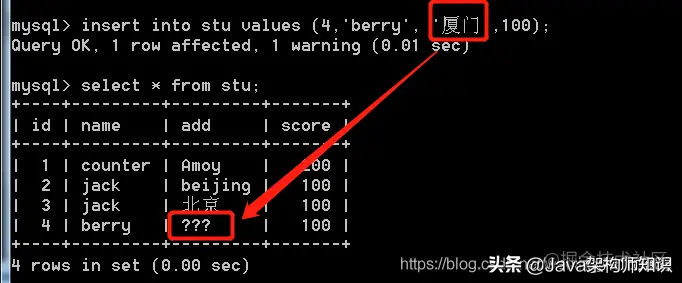

会发现已经乱码了,因为客户端发送的编码和服务端接收的编码不一致。如果将来有发现这个问题的话,就要注意编码要一致。
可以使用命令 set names gbk; 将服务端,所有编码全部都以gbk的编码形式。

 关注微信
关注微信