
官网定义:Apache IoTDB(物联网数据库)是一体化收集、存储、管理与分析物联网时序数据的软件系统。Apache IoTDB采用轻量式架构,具有高性能和丰富的功能,并与Apache Hadoop、Spark和Flink等进行了深度集成,可以满足工业物联网领域的海量数据存储、高速数据读取和复杂数据分析需求。
当前5G技术正当时,“福报厂长”马云曾经对5G技术大加赞赏:5G催化了IoT的发展,80%的5G利好体现在物联网领域。现在这已经成为一个现实,中国和美国的工业物联网,德国的工业4.0都在快速起步或者发展阶段。
在第四次工业革命的背景下,大数据成为了关键的生产资料。工业物联网的本质就是:数据 模型。而机器设备产生的时序数据构成了工业大数据的主体。
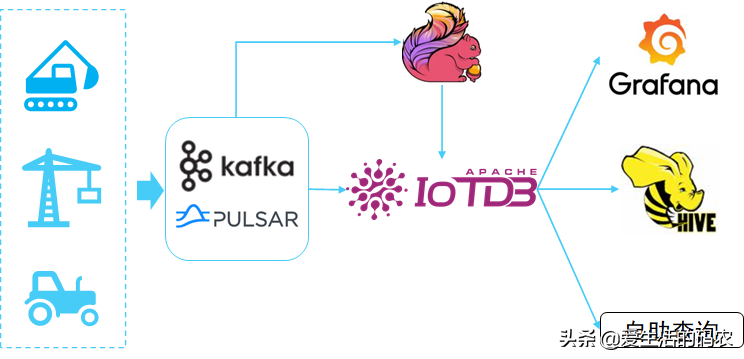
Apache IoTDB 套件由若干个组件构成,共同形成“数据收集-数据写入-数据存储-数据查询-数据可视化-数据分析”等一系列功能。如图1-1 展示了使用 IoTDB 套件全部组件后形成的整体应用架构。下文称所有组件形成 IoTDB 套件,而 IoTDB 特指其中的时间序列数据库组件。
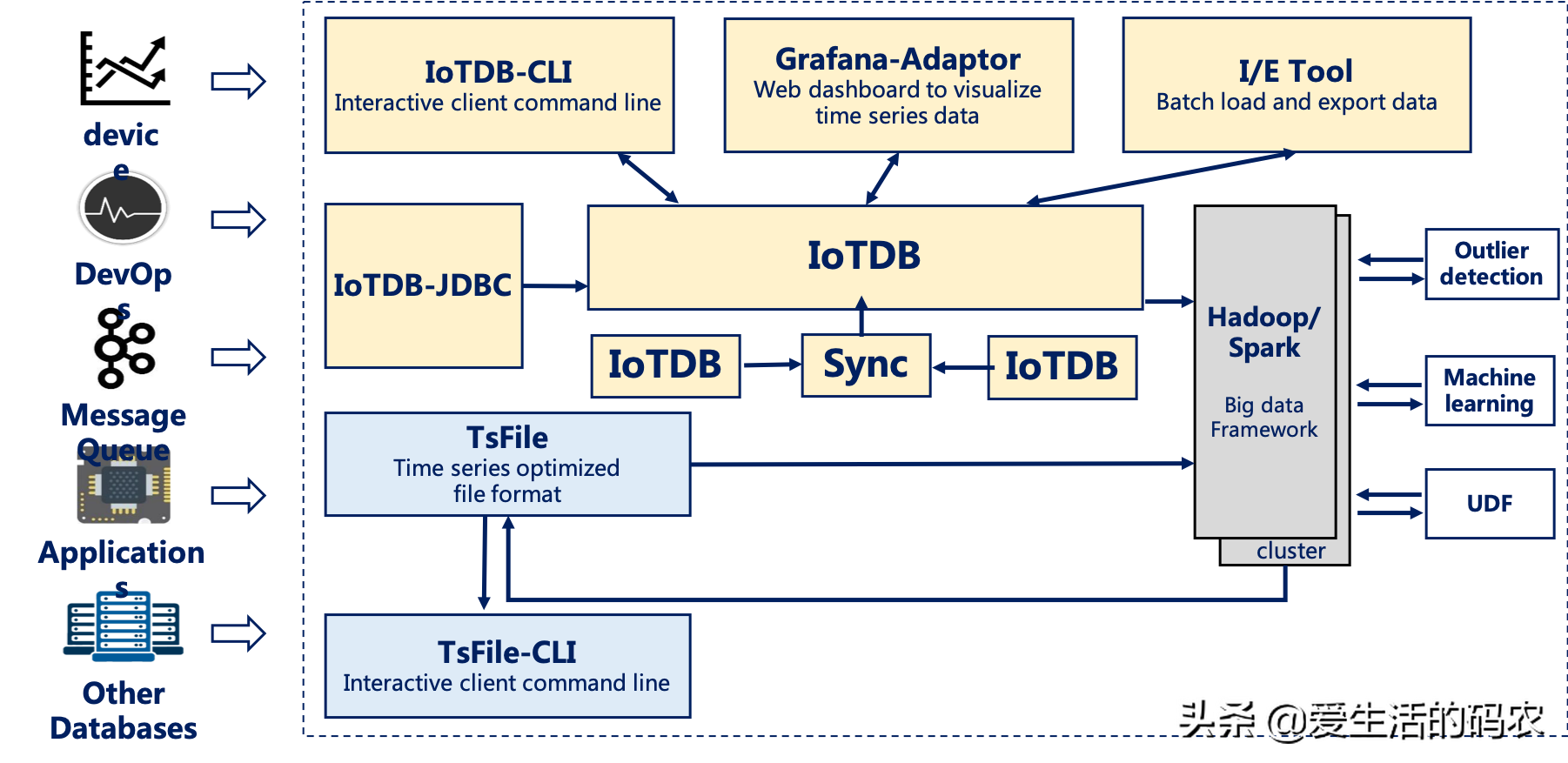
图1-1 Apache IoTDB
在上图中,用户可以通过 JDBC 将来自设备上传感器采集的时序数据、服务器负载和 CPU 内存等系统状态数据、消息队列中的时序数据、应用程序的时序数据或者其他数据库中的时序数据导入到本地或者远程的 IoTDB 中。用户还可以将上述数据直接写成本地(或位于 HDFS 上)的 TsFile 文件。
目前时序数据库有30多个,从架构的角度又可以分为三大类:
基于关系的时序数据库是建立在B tree的数据结构之上的,在写入上有先天的局限。基于KV的时序数据库在索引的建立上存储弊端,导致查询能力受限。那么基于LSMTree的InfluxDB和IoTDB在架构上都解决了高吞吐写入问题,如果从基础功能上比对,IoTDB没有什么过人之处,相比InfluxDB的一个最重要的好处是,开源版本支持集群部署;而InfluxDB的集群版本没有开源。
下面我们重点看一下官网是如何测试这些场景时序数据库的性能的。
我们从两个方面来测试写性能:batch size 和 client num。存储组的数量是 10。有 1000 个设备,每个设备有 100 个传感器,也就是说一共有 100K 条时间序列。
10 个客户端并发地写数据。IoTDB 使用 batch insertion API,batch size 从 1ms 到 1min 变化(每次调用 write API 写 N 个数据点)。如图1-2 所示是写入吞吐率测试对比报告。
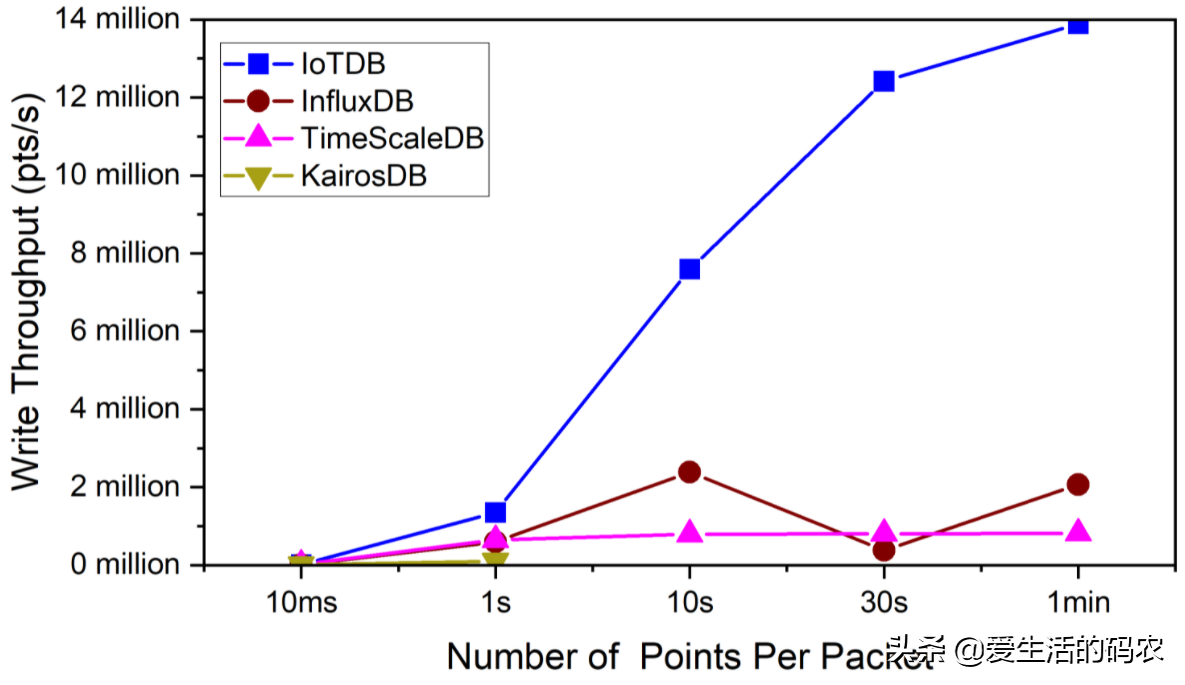
图1-2 写入吞吐率对比
如图1-3 所示是写入延迟(ms)对比报告:
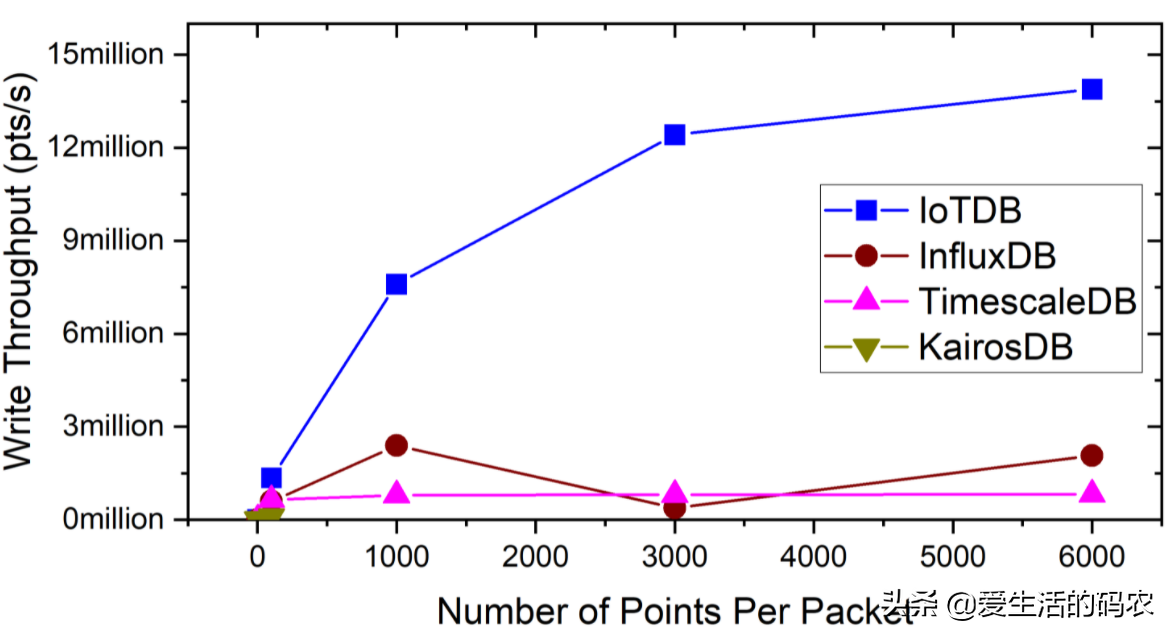
图1-3 写入延迟比对
client num从1到50变化。IoTDB使用 batch insertion API,batch size是100(每次调用 write API 写 100 个数据点)。
写入吞吐率(points/second)如图1-4 所示:
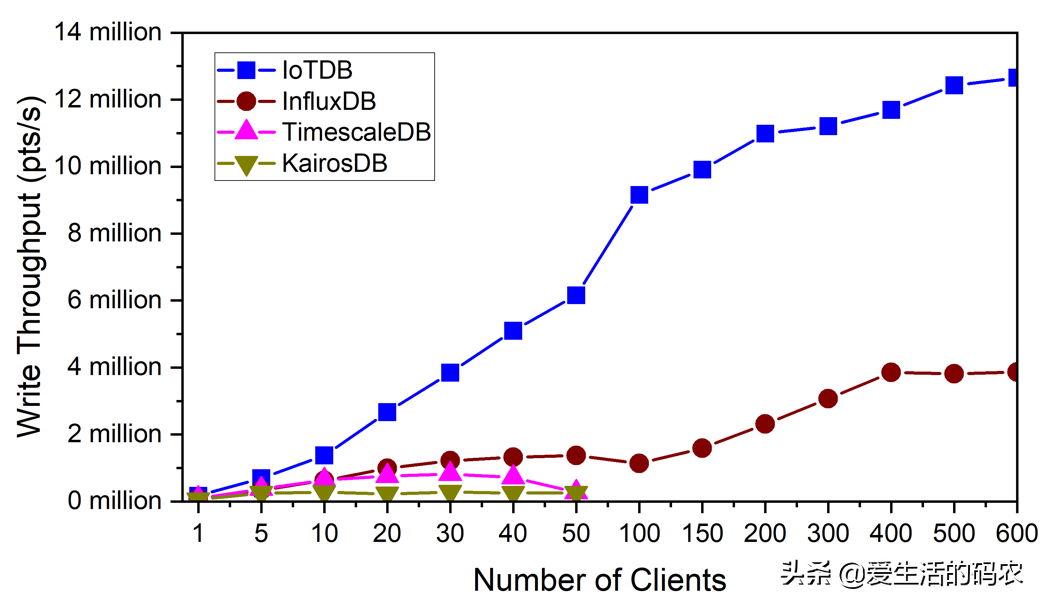
图1-4 写入吞吐率比对
10个客户端并发地读数据。存储组的数量是10。有10个设备,每个设备有10个传感器,也就是说一共有100条时间序列。
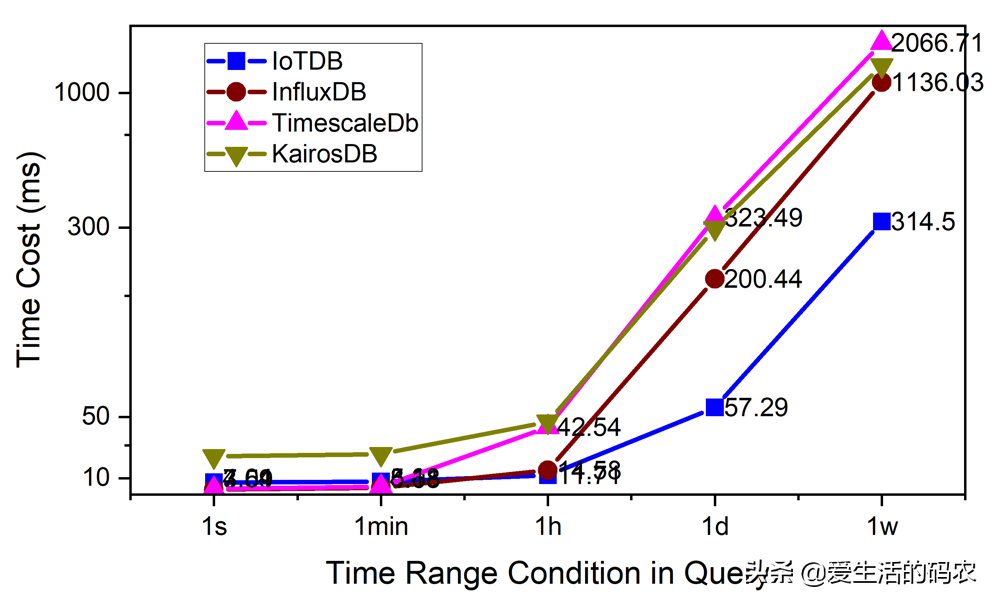
可以看出,无论是数据写入还是查询,IoTDB明显优于其他竞品。
这属于Apache IoTDB的第一篇文章,主要接触时间不长,肯定有很多需要改进的地方,希望大家多提宝贵意见。
 关注微信
关注微信