
Object类是所有类的父类,即每个类都直接或间接继承自该类。所以一个Object类型的变量可以引用任何对象,不论是类实例还是数组。
在不明确给出父类的情况下,Java会自动把Object作为要定义类的父类。
Object类有一个默认构造方法public Object(),在构造子类实例时,都会先调用这个默认构造方法。
Object类共13个方法
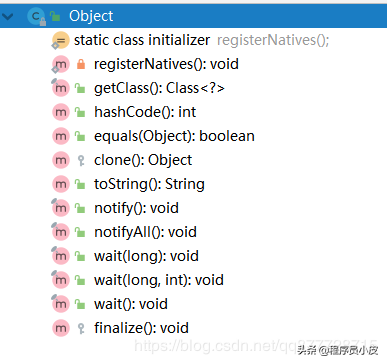
如图可知,Object类有12个成员方法,按照用途可以分为以下几种
hashCode和equale函数用来判断对象是否相同,
wait(),wait(long),wait(long,int),notify(),notifyAll() 多线程场景使用
toString()和getClass, 打印类信息/获取类信息
clone() 克隆对象
finalize()用于在垃圾回收
常用方法预览
Object()
默认构造方法
clone()
protected native Object clone() throws CloneNotSupportedException;创建并返回此对象的一个副本(复制对象),用于实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出
CloneNotSupportedException异常。
主要是JAVA里除了8种基本类型传参数是值传递,其他的类对象传参数都是引用传递,我们有时候不希望在方法里将参数改变,这是就需要在类中重写clone方法
equals(Object obj)
用于比较两个对象是否相等,底层用==实现,比较的还是内存地址,子类想要比较两个对象是否相等需要重写equals()方法
finalize()
当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法,该方法用于释放资源。很少使用
Java允许在类中定义一个名为finalize()的方法。它的工作原理是:一旦垃圾回收器准备好释放对象占用的存储空间,将首先调用其finalize()方法。并且在下一次垃圾回收动作发生时,才会真正回收对象占用的内存。
getClass()
返回一个对象的运行时类,获得类型的信息。返回一个Class对象,经常用于java反射机制
hashcode()
该方法将对象的内存地址进行哈希运算,返回一个int类型的哈希值(返回该对象的哈希码值)。
功能:是相等对象拥有相同的哈希码,尽量让不等的对象具有不同的哈希码。该方法用于哈希查找,可以减少在查找中使用equals的次数,重写了equals方法一般都要重写hashCode方法。这个方法在一些具有哈希功能的Collection中用到。
一般必须满足obj1.equals(obj2)==true。可以推出obj1.hash- Code()==obj2.hashCode(), 但是hashCode相等不一定就满足equals。不过为了提高效率,应该尽量使上面两个条件接近等价。
如果不重写hashcode(),在HashSet中添加两个equals的对象,会将两个对象都加入进去。
notify()
该方法唤醒在该对象上等待的某个线程。
notifyAll()
该方法唤醒在该对象上等待的所有线程。
toString()
返回该对象的字符串表示。以便用户能够获得一些有关对象状态的基本信息。简单说就是利用字符串来表示对象。不重写toString()返回的是对象的类路径 + @ + 内存地址hash后的16进制字符串(如下所示源码)
public String toString() {
return getClass().getName() + “@” + Integer.toHexString(hashCode());
}
wait()
导致当前的线程等待,直到其他线程调用此对象的notify()方法或notifyAll()方法。
wait(long timeout)
wait方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait()方法一直等待,直到获得锁或者被中断。wait(long timeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。
调用该方法后当前线程进入睡眠状态,直到以下事件发生。
其他线程调用了该对象的notify方法。
其他线程调用了该对象的notifyAll方法。
其他线程调用了interrupt中断该线程。
时间间隔到了。
此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常。
hash 算法,又被成为散列算法
基本上,哈希算法就是将对象本身的键值,通过特定的数学函数运算或者使用其他方法,转化成相应的数据存储地址的。
而哈希法所使用的数学函数就被称为 『哈希函数』又可以称之为散列函数。
如果我们能在数组存放的时候就按一定的规则放入元素,在我们想找某个元素的时候在根据之前定好的规则,就可以很快的得到我们想要的结果了。换句话说之前我们在数组中存放元素的顺序可能是依照添加顺序进行的,但是如果我们是按照一种既定的数学函数运算得到要放入元素的值,和数组角标的映射关系的话。那么我们在想取某个值的元素的时候就使用映射关系就可以找到对应的角标了。
在常见的 hash 函数中有一种最简单的方法交「除留余数法」,操作方法就是将要存入数据除以某个常数后,使用余数作为索引值。
下面看个例子:将 323 ,458 ,25 ,340 ,28 ,969, 77 使用「除留余数法」存储在长度为11的数组中。我们假设上边说的某个常数即为数组长度11。 每个数除以11以后存放的位置如下图所示:
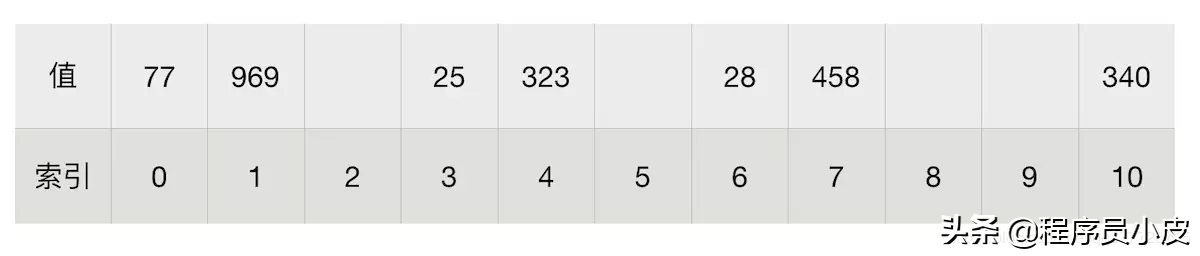
试想一下我们现在想要拿到 77 在数组中的位置,是不是只需要arr[77%11] = 77 就可以了。
但是上述简单的 hash 算法,缺点也是很明显的,比如 77 和 88 对 11 取余数得到的值都是 0,但是角标为 0 位置已经存放了 77 这个数据,那88就不知道该去哪里了。上述现象在哈希法中有个名词叫碰撞:
碰撞:若两个不同的数据经过相同哈希函数运算后,得到相同的结果,那么这种现象就做碰撞。
如果两个对象相同,那么它们的hashCode值一定要相同;
如果两个对象的hashCode相同,它们并不一定相同(这里说的对象相同指的是用equals方法比较)。
equals()相等的两个对象,hashCode()一定相等;equals()不相等的两个对象,却并不能证明他们的hashCode()不相等。
 关注微信
关注微信