
通过前面的学习,我们知道了调用Requests库可以爬取HTML页面,调用Beautiful Soup库可以解析HTML页面。但是通常一个HTML页面拥有非常多的信息,你总不能全部拿过来再手动修改吧,所以就需要使用Re正则表达式来提取页面的关键信息。
Re:Regular expression,可以简洁、优雅的表达一组字符串的表达式。
举个例子:
"Py"
"Pyt"
"Pyth"
"Pytho"
"Python"以上这组字符串有什么相似之处呢?没错,就是它们都是以”Py”开头的。
我们用了五行才把所有的字符串枚举一遍,如果换成使用Re呢?一行OK!
Py(t|th|tho|thon)#N这只是五行字符串,如果是成千上万行呢?那正则表达式用起来岂不是特别的爽。
正则表达式最最本质的特征就是:简洁、优雅、一行胜千言。
在我看来,就像是跟苹果LOGO似的,极简之美环绕其周。
还有一个词:求同存异。
下面来看看正则表达式的语法:
正如上面所展示的,正则表达式由字符和操作符构成。
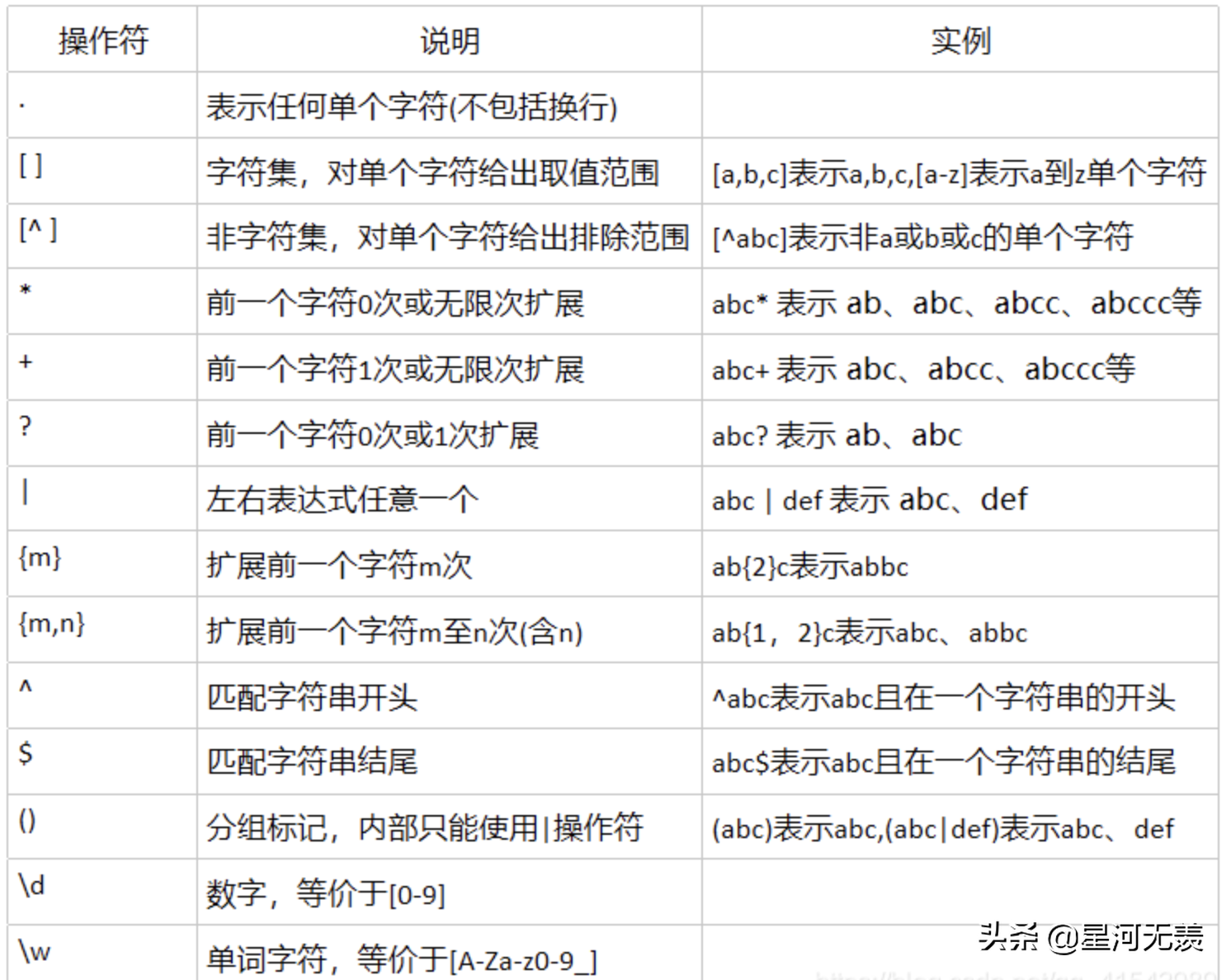
常用操作符
来看一些经典的正则表达式例子:
^[A-Za-z]+$ 由26个字母组成的字符串
^-#d+$ 整数形式的字符串
[1-9]d{5} 中国境内邮政编码
d{3}-d{8}|d{4}-d{7} 国内电话号码Python为正则表达式提供了标准库Re,用于匹配字符串。
调用Re库:
import re正则表达式的表示类型:
例如:r'[1-9]d[5]’
raw string 类型是原生字符串类型,不能对转义字符进行再次转义。
例如:'[1-9]\d{5}’
前一个”是转义字符。
当正则表达式包含转义字符时,更推荐使用raw string类型。
Re库的基本方法:
先来介绍一下Match对象:
Match对象是一次匹配的结果,包含很多的匹配信息。
和response对象一样,Match对象也有一些属性和方法。
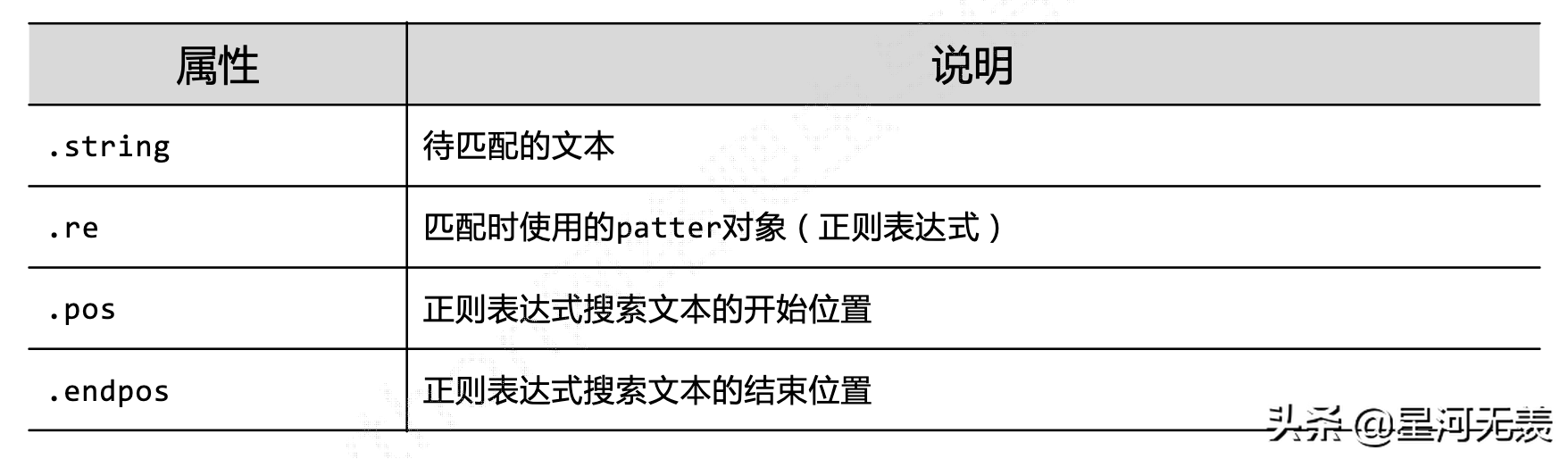
Match对象的属性

Match对象的方法
前面已经介绍过如何调用对象的属性和方法了,这里就不再赘述,可以百度做深入了解。

Re库的六个基本方法
下面着重讲解一下search方法:
re.search(pattern, string, flags=0)在一个字符串中搜索匹配正则表达式的第一个位置,返回Match对象。

flags标记取值
# 使用search方法匹配字符串
match = re.search(r'[1-9]d{5}', 'A100001', flags=re.I)
# 匹配成功则返回匹配后的字符串
if match:
print(match.group(0))注意:Match对象返回匹配结果,所以说Match返回值是bool型变量,故用条件语句判断。
Re库的方法使用起来并没有太大的难度,下面给出剩余方法总结:
re.match(pattern, string, flags=0)从一个字符串的开始位置起匹配正则表达式,返回Match对象。
参数同上。
re.findall(pattern, string, flags=0)搜索字符串,以列表类型返回全部能匹配的子串。
参数同上。
re.split(pattern, string, maxsplit=0, flags=0)将一个字符串按照正则表达式匹配结果进行分割,返回列表类型。
re.finditer(pattern, string, flags=0)搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素都是Match对象。
参数同上。
for m in re.finditer(r'[1-9]d{5}', 'A100001 B100002'):
if m:
print(m.group(0))re.sub(pattern, repl, string, count=0, flags=0)在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串。
sub = re.sub(r'[1-9]d{5}', ',hello', 'A100001 B100002')
print(sub)上面讲解了Re库六种基本方法的函数式用法,下面介绍另一种等价的面向对象的用法:
match = re.search(r'[1-9]d{5}', 'A100001')cmp = re.compile(r'[1-9]d{5}')
match = cmp.search('A100001')第一种是函数式用法,一次操作可以完成任务;第二种是面向对象用法,先将正则表达式的字符串形式编译成正则表达式对象,再进行方法操作。两种方法都是可以的,了解即可。
在实际使用过程中,我们会遇上一个问题,如下:
match = re.search(r'PY.*N', 'PYANBNCN')对这样一个字符串,原则上是可以返回三个子串,即’PYAN’,’PYANBN’,’PYANBNCN’。但是我们调用match.group(0)查看时,该返回哪一个呢?
Re库默认采用贪婪匹配机制,返回匹配中最长的子串,也就是返回’PYANBNCN’了。
那又有一个问题了,当我们想要输出最短的子串该怎么办呢??
我们只需在操作符后面添加?即可输出最小匹配了:

最小匹配
match = re.search(r'PY.*#N', 'PYANBNCN')
if match:
print(match.group(0))本章讲解了Python中正则表达式Re库的入门级使用,正则表达式并不是Python所独有的,很多地方都可以使用,在学习完Re库后对其他语言和任务也都有一定的帮助。
 关注微信
关注微信