
在我们要做数据分析之前,首先要了解数据分析有哪些步骤。
数据分析一般分为5个步骤:
一切的数据分析工作都是为了解决问题,所以在做数据分析之前,我们首先要搞懂要处理分析什么样的问题;在采集或者收集到数据信息后,我们要理解数据分别是代表什么信息;接着我们要进行数据清洗,一般我们拿到数据后,可能是杂乱无章的,很多脏数据或者重复数据,所以我们要给数据”洗白白”;然后我们就可以用各种方法对数据进行分析了;在最后分析完成之后,我们就可以用数据可视化的方式,利用图表的形式让大家看懂数据。
EXCEL作为数据分析工作中最常用的软件,是我们在入门数据分析首先要学的工具,今天我们就以EXCEL的使用为例,看看如何做到基础的数据分析工作。
一、数据分析第1步:明确问题
假设我们手头上有一份招聘网站的招聘数据,我们想要了解一些问题:
二、数据分析第2步:理解数据
我们在拿到收集数据的文件之后,需要养成良好的工作习惯,对原始数据文件进行备份,然后再在文档上对数据进行理解、清晰、分析等工作。

1.了解数据有什么信息
我们打开数据文件,我们会看到会有很多的列明(字段),例如城市、公司名称、职位福利、薪水等,而这些信息正是意味着我们可以通过这份数据可以让我们了解到什么情况,或者可以用来解决什么问题。

很多时候我们拿到一份EXCEL文档,会发现很多个格子的信息都显示不全,这种时候我们可以点击任意一个信息,然后键盘CTR+A全选数据,然后点击”开始”栏的自动换行。
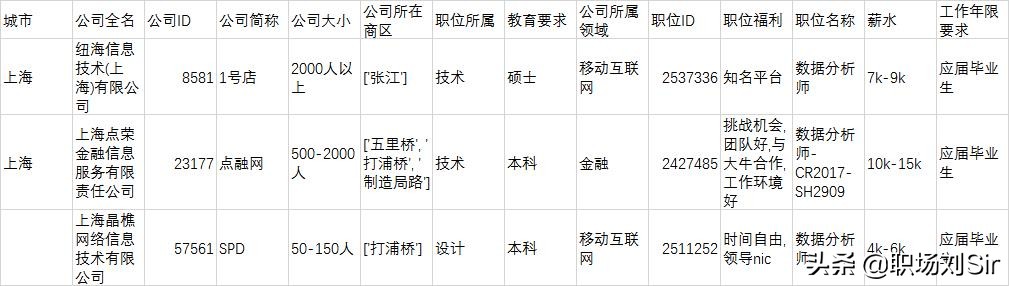
这时信息就显示全了,那么想要让表格更加美观一点呈现信息的话,我们可以点击表格的左上角的小三角形,这时候会全选整个表格,接着再列号位置点击右键(A/B/C/D……这种),然后点击列宽,试着设置为15,这时表格会变宽。
2.了解EXCEL的数据类型
EXCEL的数据类型主要分为三种类型,分别是字符串、数值、逻辑。
数字可以是两种类型,一种是字符串类型,字符串类型的数字不能用于计算,一般在表格中默认向左对齐;而数值类型的数字则可以用于计算,一般在表格中默认向右对齐。
三、数据分析第3步:数据清洗
数据清洗占用我们数据分析中大部分的时间,数据清洗相当于把数据改变我们喜欢的样子、符合我们需求的样子,为后续的分析工作做准备。
1.选择子集(选择我们准备进行数据分析工作中感兴趣或是需要的几个列数据。)
2.列名重命名(把列名改为符合自己命名喜好的名字。)
3.删除重复值(把重复的多余数据进行删除。)
4.缺失值处理(把缺失的数据进行删除或是补全等方式的处理。)
5.一致化处理(对数据列没有统一命名的值进行统一处理。)
6.数据排序(通过数据一定规律的排序便于发现价值信息。)
7.异常值处理(对数据异常的值进行处理。)
1.选择子集
选择子集主要是把对我们有用的信息留下,把对我们没用的信息隐藏掉,方便对数据进行处理。例如,我们要分析工作机会、薪酬水平等问题,像”公司ID”这种数据对于我们来说没什么用,我们就可以在该列的列号上点击右键,然后点击隐藏就可以了,如果字段信息在一行上,那就在行号上点击就可以了。
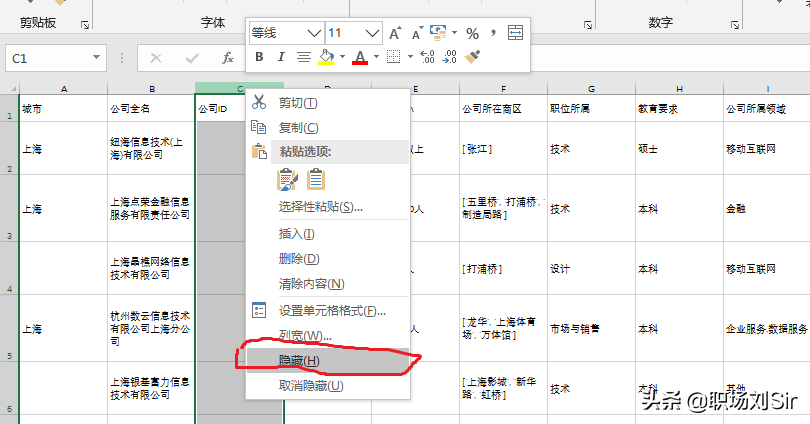
如果想要把隐藏的数据展开,可以在”开始”栏中的格式中,点击隐藏和取消隐藏,根据实际需要取消隐藏行或列。
2.列名重命名
在表格中,像”公司大小”这种,我习惯的表达方式是”公司规模”,那么我就会双击该格子,把文字改过来。

3.删除重复值
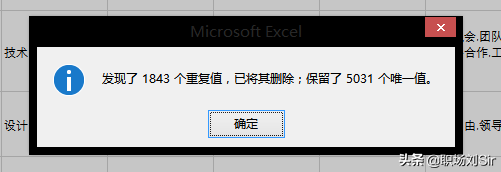
在招聘的表格中,有一项”职位ID”,因为在发布的职位中,每个职位都是有着唯一的一个ID号码的,就像身份证一样,如果出现重复的情况就意味着这个职位信息的数据重复了,我们需要进行删除。
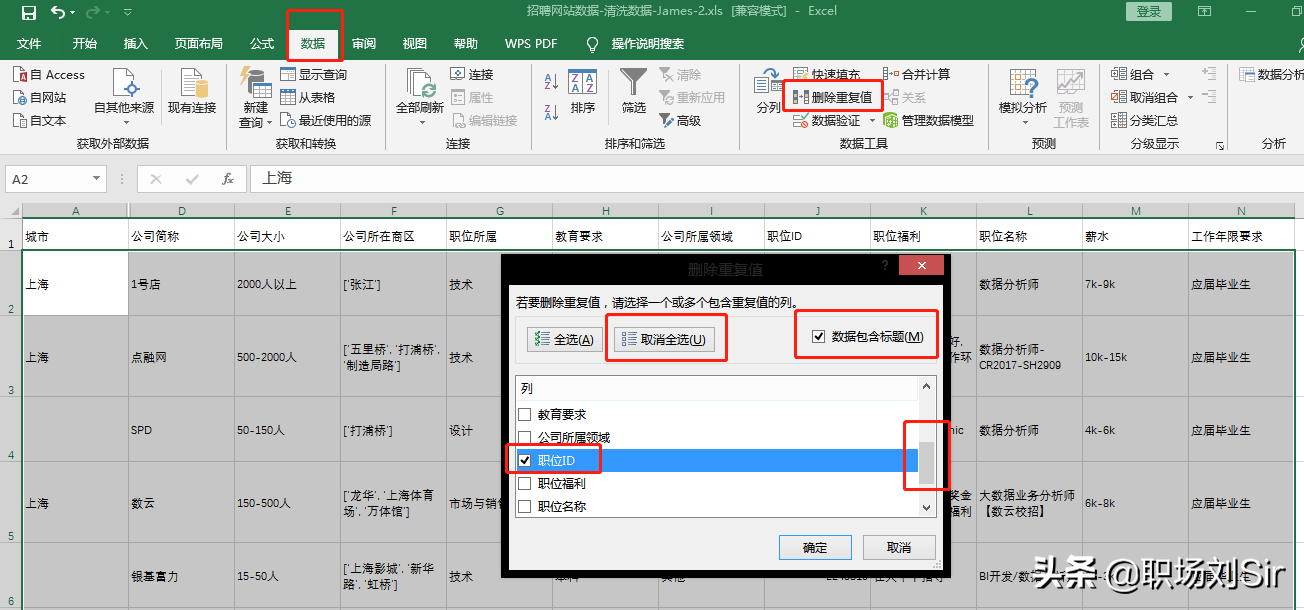
点击”数据”栏里的”删除重复值”,然后勾选”数据包含标题”,点击取消全选,找到我们要用来识别数据是否重复的”职位ID”,点确认,然后系统就进行自动删除处理了,方便快捷。
4.缺失值处理
在打开数据表格后,我们有时候可能会发现,有的数据格子是空白的,那么我们怎么找出这些缺失值呢?
我们可以通过每一列的数据总数进行查看,然后用简单的减法就可以算出缺失数量。
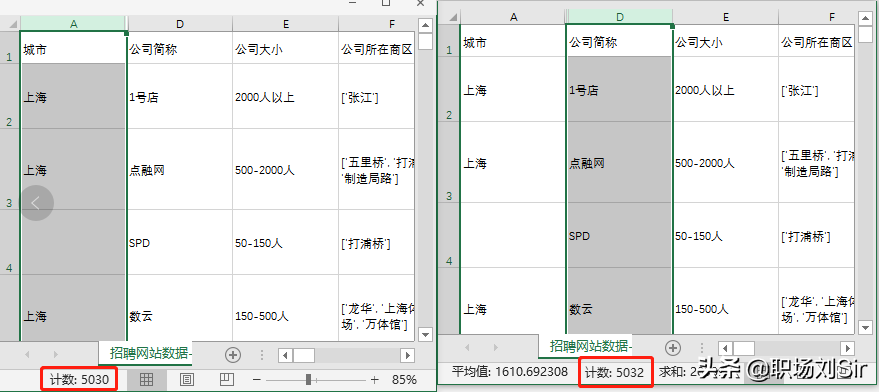
“城市”列缺失数量=”公司简称”数量-“城市”数量,即5032-5030=2。
如果数据比较少,我们就可以尝试进行补全,例如上图空白处,我们可以根据公司所在区域来核对公司是在哪个城市。
5.一致化处理
(1)分割
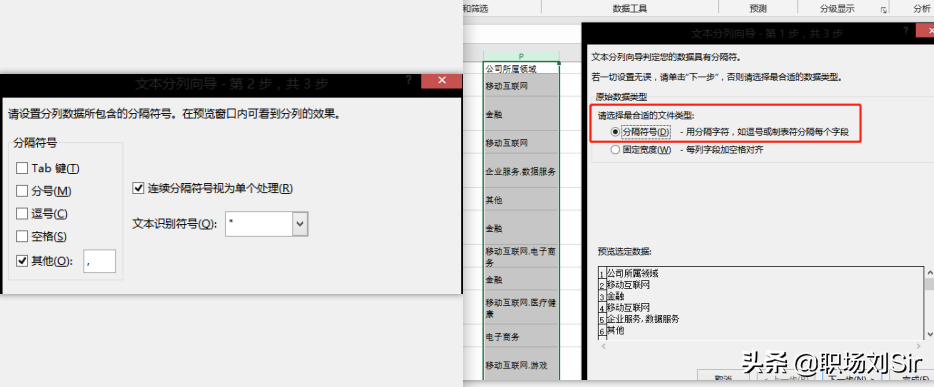
有时候我们的数据信息里,一个格子里可能会有几个信息,那么这时候,我们就可以用一致化处理的方式把他们分割开来。
例如,公司所属领域,会涉及几个领域,并且用逗号分割开来。我们点击”数据”栏里的”分列”,然后设置为根据分割符号进行分割,处理过后我们就会发现原来的那一列旁边自动生成了分割后的数据。但是我们在处理之前要把那一列的数据复制到表格最后处理,避免分割后的数据覆盖掉旁边的数据列。
(2)函数处理:
在一致化处理,我们还可以通过函数来对数据进行一致化处理,函数其实就是规则、公式,只要设定好,EXCEL的系统就会自动帮你处理信息,这样就不需要我们一个个选项去算、去选那么麻烦。
EXCEL里的函数非常丰富,函数的应用对于我们来说真是可以大大提高效率,那些成千上万的数据,要是一个个处理,那简直是苦力工作,但是函数却能让我们一件生成。
接下来我将用实战案例来展示函数的相关运用。
四、电商婴儿产品数据试手
通过天池平台,我手上获得了两份表,一份是购买产品信息表,一份是婴儿信息表。
1.明确问题
根据昨天的初步构想,准备主要分析每个季度哪些婴儿商品卖得最好的有哪些?并在这个过程中,附带一些其他一些探索性的分析。
2.理解数据
拿到表后,先看一下表内的各个列名都有些什么信息,好让我们知道我们可以拿这些数据信息分析什么。
3.数据清洗
(1)选择子集
由于商品属性有很多参数,而且每个商品不尽相同,对于我这次分析作用不大,因此先进行隐藏。
(2)列名重命名
首先我将表格中的字段休息修改为我习惯的表达方式,并且调整列宽和换行,让表格看起顺眼一些。
(3)删除重复值
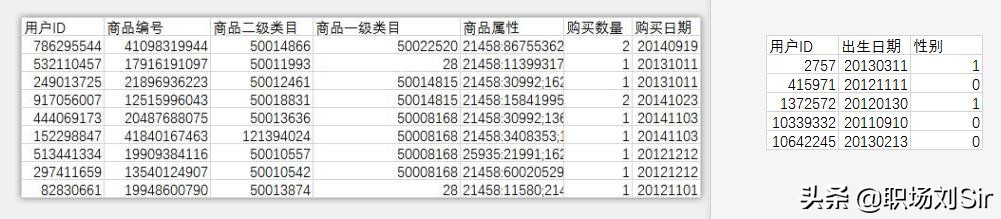
在婴儿信息表里,因为每个婴儿的ID都是唯一的,所以我们可以通过删除重复值,直接识别和删除,点击过后发现数据并无重复。
(4)缺失值处理
通过列的信息量计数得出,除了商品属性一列为29828行信息外,其余列均为29972,即商品属性列缺失了144个数据信息。但由于商品属性对于此次的分析无影响作用,所以可以后续再根据商品编号补充回对应的商品属性信息。
(5)一致化处理
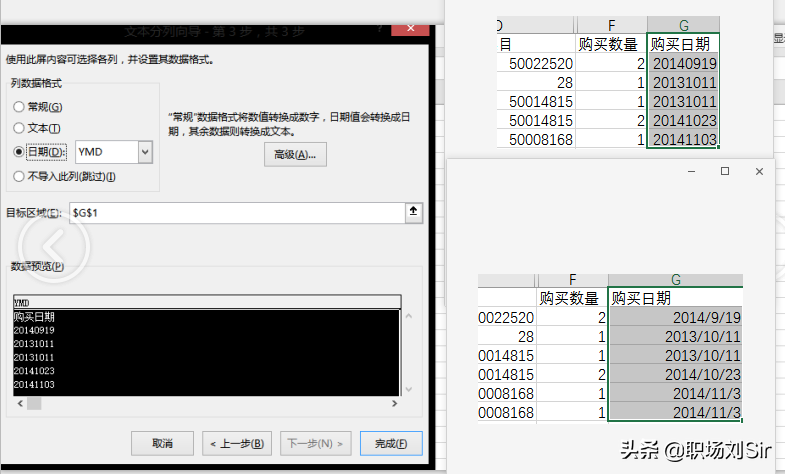
两个表格里的日期都是全数字的,不方便查阅,因此我们要通过分列的技巧,把日期全都改为标准日期形式,并通过设置单元格格式让日期进一步统一。
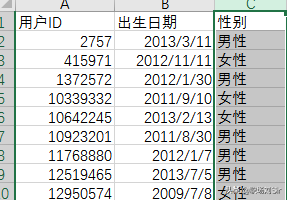
因为婴儿表中,都是用0来代表女性,1代表男性,2代表未知性别,为了方便识别,我将其通过替换改为中文表达方式。
4.数据分析
接下来,我通过数据透视表分析每个季度哪些婴儿商品卖得最好的有哪些?
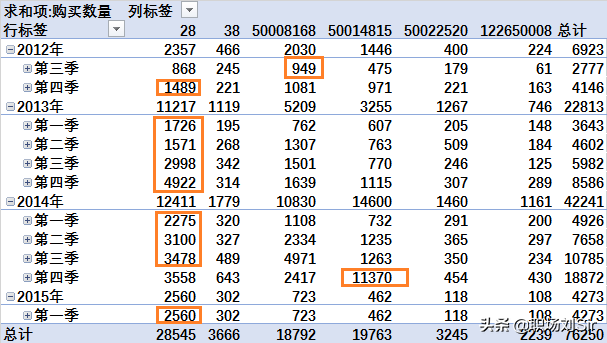
通过数据显示发现,类目编号为28的商品在11个季度中,有9个季度都是卖得最好的。
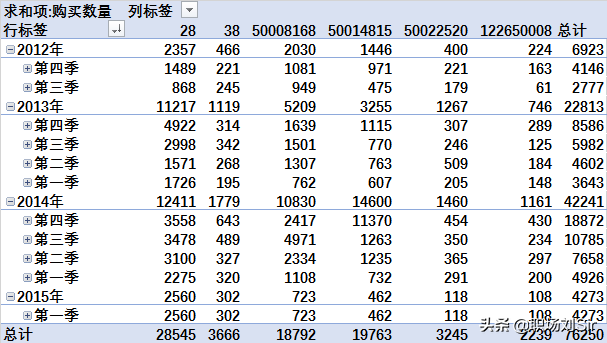
然后我们通过每个季度的总销量进行排序,发现季度的销量每年呈现第四季度>第三季度>第二季度>第一季度的规律。
接着,我试着用VLOOKUP函数进行多表关联,把收集到婴儿信息的用户ID跟购买用户ID进行匹配,识别出购买日期和购买数量。
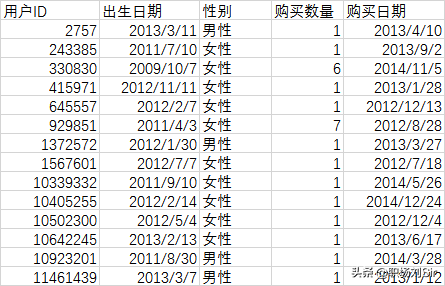
然后通过描述性统计分析发现,用户评价购买商品的数量为1.6个,而中位数和众数都为1,代表大部分用户购买数量都是1份。但是从最大值和最小值差距比较大可以看出,这份数据可能有异常,我们需要进一核查信息。
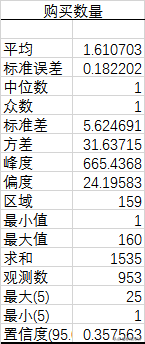
通过数据透视表我们可以发现,为女性婴儿购买产品的父母会多一点,但是实际上男女婴儿需求比例是差不多的。

通过分析策略的学习和软件的学习之后,因为都不够熟悉,导致在实战使用起来会比较生涩,或者是考虑因素不够周全,运用方式不够全面,需要多加练习,逐步进阶。
 关注微信
关注微信