
在正文开始前,先说说正则表达式是什么,为什么要用正则表达式?正则表达式在我个人看来就是一个程序可以识别的规则,有了这个规则,程序就可以帮我们判断某些字符是否符合我们的要求。但是,我们为什么要使用正则表达式呢?下面来看个正则业务场景,来验证一串字符是否为合法QQ号。示例如下:
/**
* 要求:一个合法的QQ号必须满足:1、5-15位;2、全是数字;3、不以0开头
*/
//1.在不使用正则表达式的时候,我们可能会这样判断QQ号的合法性
var qq="6666666a6666";
if(qq.length>=5&&qq.length<=15&&!isNaN(qq)&&qq.charCodeAt(0)!=48){
alert("QQ合法");
}else{
alert("QQ不合法")
}
//2.使用正则表达式
var qq="066336";
var reg=/^[1-9][0-9]{4,14}$/;
if(reg.test(qq)){
alert("QQ合法");
}else{
alert("QQ不合法");
}从上面这个例子可以看出来使用了正则表达式的时候,我们的代码量变少了,而且比较直观。如果遇到非常的复杂的匹配,正则表达式的优势就更加明显了。

那什么是正则表达式呢?
也就是创建正则表达式对象,可通过字面量形式或RegExp构造函数两种形式来定义,如下所示:
// 字面量定义
const pattern=/d/g
//或 构造器定义
const pattern = new RegExp('d','g')一般使用字面量形式,构造函数形式用在正则表达式在运行时才能确定下的情况,例如
function hasClass(ele, classname) {
const pattern = new RegExp('(^|\s)' + classname + '(\s|$)')
return pattern.test(ele.className)
}注意:字符串中反斜杠有别的含义,要想表示d等要使用两个反斜杠来转义\d* 。
第一种通过“/正则表达式/修饰符“这种形式直接写出来;
第二种通过“new RegExp(‘正则表达式’,’修饰符’)”创建一个RegExp对象。
其中修饰符为可选项,有三个取值分别为:g为全局匹配;i指不区分大小写;m指多行匹配。
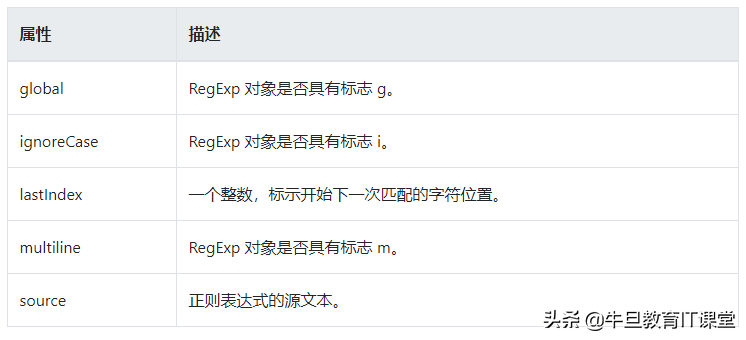
通过上述方式,就创建了正则表达式对象。说到RegExp对象,下面要说一下RegExp对象自带的属性,并不复杂,这里我就列一下,不做展开。

1)反斜杠
在正则表达式中反斜杠有重要的含义
/.com/.test('.com')而在字符串中反斜杠同样是一个转义字符,比如结合n r t来表示换行、回车、制表位等
要想在字符串中表示出一个,则表达式中需要两个 ,示例如下:
new RegExp("[\w\.]").toString()=='/[w.]/'2)()、[]与|
[]:集合操作符,表示一系列字符的任意一个
例如:/[abc]/ 表示a、b、c中的任意一个能匹配就可以了
关于/[a|b]/
一个常见的误区是感觉/[a|b]/表示要匹配a或者b,其实是a、b或者|中的任意一个
/[a|b]/.test('|') === true
/(a|b)/.test('|') ===false关于括号()
从上面可以看到,圆括号中的|是或的意思,表示要匹配()以|分割的两边的整体(两边其中之一),注意是整体。
例子:
/(abc|abd)/.test('ab') ===false
/(abc|abd)/.test('abc') ===true
/(abc|abd)/.test('abd') ===true3)分组与捕获
上面只是介绍了圆括号中存在|时需注意的点,这里重点说一下圆括号(英文状态下的小括号())
在正则中,圆括号有两种含义,一是用来分组,一是用来捕获想要的值
()结合* ? + {} 使用时,是对圆括号内的整体进行repeat
/(ab)+/ 匹配一个或多个ab
/(ab)+|(cd)+/ 匹配一个或多个 ab或cd捕获是一个强大的功能,也是很多时候我们使用正则的原因,同样以()来表示
例子:找出样式中的透明度值
<div id="opacity" style="opacity:0.5;filter:alpha(opacity=50);">
function getOpacity(elem) {
var filter = elem.style.filter;
if(filter){
return filter.indexOf("opacity=") >= 0 #(parseFloat(filter.match(/opacity=([^)]*)/)[1]) / 100) + " : "
}
return elem.style.opacity
}捕获主要结合exec()、match() 和 g标记使用,下面会介绍
需要强调的是,因为分组和捕获一样使用(),所以,在一个正则表达式中既有用于分组的(),也有用于捕获的()时,对于分组部分,可以加上#:,这样,结果集就只包含我们想要捕获的部分。
示例如下:
'<div>hahahahah<div>'.match(/(<[^>]+>)([^<]+)/)
> [ <div>hahahahah , <div> , hahahahah ] //两个捕获
如果我们只对标签内的文本感兴趣
'<div>hahahahah<div>'.match(/(#:<[^>]+>)([^<]+)/)
> [ <div>hahahahah , hahahahah ] //对于<div>,我们不关心,就不要了说到#: 就要提一下长得差不多的 #= 和 #!
#= 表示后面必须跟着某些东西,并且结果中不包含#=指定的部分,并且不捕获
#! 表示后面必须不跟着某些东西
对比看一下
/a(#:b)/.exec('abc')
> ["ab", index: 0, input: "abc"] //注意匹配的是"ab"
/a(#=b)/.exec('abc')
> ["a", index: 0, input: "abc"] //注意匹配的只是"a"
/a(#!b)/.exec('abc')
> null //没有匹配的,返回的是null再看个例子,数字字符串转千分位
function formatNumber(str) {
return str.replace(/B(#=(d{3})+$)/g, ',')
}
formatNumber("123456789")
> 1,234,567,890解释:
4)exec()、match()与g标记
exec()和match()都是返回数组,结果集中包含捕获的内容
在正则中不包含g时,exec()和match()返回的结果集是一样的,数组中依次是 整个匹配的字符串、依次的()指定的要捕获的部分

在有g的时候,match()返回的数组中的每一项是依次匹配到的整体字符串,不包含每个匹配中捕获到的内容
对比来看
"p123 q123".match(/b[a-z]+(d+)/)
> ["p123", "123", index: 0, input: "p123 q123"]
"p123 q123".match(/b[a-z]+(d+)/g)
> ["p123", "q123"]
可以看到加上g后,返回的数组就只有匹配项了
那么,即想匹配全部,又想获取到捕获怎么办呢?
while与exec()结合
let pattern=/b[a-z]+(d+)/g
let str='p123 q123'
let match
while((match=pattern.exec(str)) !=null){
console.log(match)
}
> ["p123", "123", index: 0, input: "p123 q123"]
["q123", "123", index: 5, input: "p123 q123"]5)replace()
对于字符串的replace方法,重点说一下,其第二个参数,可是一个函数。
对于str.replace(/xxxxx/g,function(){})
函数在每次前面的正则匹配成功时都会执行,函数的参数依次是,完整的匹配文本、依次的捕获部分、当前匹配的索引、原始字符串
"border-bottom-width".replace(/-(w)/g,function(match,capture){
return ";"+capture.toUpperCase()
})
> "border;Bottom;Width"注意,有人可能把其中的第二个函数参数改写成箭头函数,如(..)=>{..}则可能会出错,需要当心。
有了上面的认知和解析,这里再总结一下正则对象(包括两种方式创建的对象)的主要方法。
检索字符串中指定的值。返回 true 或 false。这个是我们平时最常用的方法。
var reg=/hello w{3,12}/;
alert(reg.test('hello js'));//false
alert(reg.test('hello javascript'));//true检索字符串中指定的值。匹配成功返回一个数组,匹配失败返回null。
var reg=/hello/;
console.log(reg.exec('hellojs'));//['hello']
console.log(reg.exec('javascript'));//nullcompile() 方法用于改变正则。compile() 既可以改变检索模式,也可以添加或删除第二个参数。
var reg=/hello/;
console.log(reg.exec('hellojs'));//['hello']
reg.compile('Hello');
console.log(reg.exec('hellojs'));//null
reg.compile('Hello','i');
console.log(reg.exec('hellojs'));//['hello']除了RegExp对象提供方法之外,String对象也提供了四个方法来使用正则表达式,在使用JavaScript时,也常用到。
在字符串内检索指定的值,匹配成功返回存放匹配结果的数组,否则返回null。这里需要注意的一点事,如果没有设置全局匹配g,返回的数组只存第一个成功匹配的值。
var reg1=/javascript/i;
var reg2=/javascript/ig;
console.log('hello Javascript Javascript Javascript'.match(reg1));
//['Javascript']
console.log('hello Javascript Javascript Javascript'.match(reg2));
//['Javascript','Javascript','Javascript']在字符串内检索指定的值,匹配成功返回第一个匹配成功的字符串片段开始的位置,否则返回-1。
var reg=/javascript/i;
console.log('hello Javascript Javascript Javascript'.search(reg));//6替换与正则表达式匹配的子串,并返回替换后的字符串。在不设置全局匹配g的时候,只替换第一个匹配成功的字符串片段。
var reg1=/javascript/i;
var reg2=/javascript/ig;
console.log('hello Javascript Javascript Javascript'.replace(reg1,'js'));
//hello js Javascript Javascript
console.log('hello Javascript Javascript Javascript'.replace(reg2,'js'));
//hello js js js把一个字符串分割成字符串数组。
var reg=/1[2,3]8/;
console.log('hello128Javascript138Javascript178Javascript'.split(reg));
//['hello','Javascript','Javascript178Javascript']第一次接触正则表达式同学们,可能被这个正则表达式的规则弄得迷迷糊糊的,根本无从下手。小编我第一次学这个正则表达式的时候,也是稀里糊涂,什么元字符、量词完全不知道什么东西,云里雾里的。后面小编细细研究了一下,总结一套方法,希望可以帮助大家。
关于正则表达式书写规则,可查看w3school,上面说的很清楚了,我就不贴出来了。我就阐述一下我写正则表达式的思路。
其实正则表达式都可以拆成一个或多个(取值范围+量词)这样的组合。针对每个组合我们根据JS正则表达式的规则翻译一遍,然后将每个组合重新拼接一下就好了。下面我们举个例子来试一下,看看这个方法行不行。
合法qq号规则:1、5-15位;2、全是数字;3、不以0开头
根据QQ号的验证规则,我们可以拆成两个(取值范围+量词)的组合。分别是:
1.(1~9的数字,1个);2.(0~9的数字,4~14个)
1.(1~9的数字,1个) => [1-9]{1}或者[1-9]
2.(0~9的数字,4~14个) => [0-9]{4,14}
初学者可能在拼接这一步会犯一个错误,可能会组合拼接成这个样子/[1-9]{1}[0-9]{4,14}/或者简写翻译成/[1-9] [0-9]{4,14}/这些都不对的。调用test()方法的时候,你会发现只要一段字符串中有符合正则表达式的字符串片段都会返回true,童鞋们可以试一下。
var reg=/[1-9][0-9]{4,14}/;
alert(reg.test('0589563'));
//true,虽然有0,但是'589563'片段符合
alert(reg.test('168876726736788999'));
//true,这个字符串长度超出15位,达到18位,但是有符合的字符串片段正确的写法应该是这样的:
/^[1-9][0-9]{4,14}$/(用^和$指定起止位置)
下面我们看一个复杂点的例子:
0555-6581752、021-86128488
这里会拆成两个大组合:
1、(数字0,1个)+(数字0~9,3个)+("-",1个)+(数字1~9,1个)+(数0~9,6个)
2、(数字0,1个)+(数字0~9,2个)+("-",1个)+(数字1~9,1个)+(数0~9,7个)
1、([0-0],{1})+([0-9],{3})+"-"+([1,9],{1})+([0,9],{6})
2、([0-0],{1})+([0-9],{2})+"-"+([1,9],{1})+([0,9],{7})
这里我们先拼接一个大组合,然后再将大组合拼接起来
1、0[0-9]{3}-[1-9][0-9]{6}
2、0[0-9]{2}-[1-9][0-9]{7}
最后拼接为:
/(^0[0-9]{3}-[1-9][0-9]{6}$)|(^0[0-9]{2}-[1-9][0-9]{7}$)/正则表达式并不难,懂了其中的道道和套路——所谓的核心和精要之后,一切都会变得简单。
另外,说点题外话——网上不乏一些文章记录一些常用的正则表达式,然后新手前端在使用正则表达式的时候都会直接拿来就用。在这里我想说一下自己的看法,这些所谓记录常用的正则表达式文章并非完全都是正确的,有不少都是错的,也可能是无心的,就像我们经常在网上看到的示例,你怎么也跑不通。所以同学们在日后使用的过程尽量自己写正则表达式,多写写练练和总结,实在不会了可以去参考一下,但真的不要照搬下来。咱不说这种会影响自己成长的话,咱就说你抄的一定都是对的吗?多动手,多思考一下,总没有坏处的。
 关注微信
关注微信