
首先我们来看看维基百科对负载均衡的说明:
负载平衡(Load balancing)是一种计算机技术,用来在多个计算机(计算机集群)、网络连接、CPU、磁盘驱动器或其他资源中分配负载,以达到最优化资源使用、最大化吞吐率、最小化响应时间、同时避免过载的目的。使用带有负载平衡的多个服务器组件,取代单一的组件,可以通过冗余提高可靠性。负载平衡服务通常是由专用软件和硬件来完成。主要作用是将大量作业合理地分摊到多个操作单元上进行执行,用于解决互联网架构中的高并发和高可用的问题。
下图中,一群人在银行排队办理业务,假设只有一个服务窗口,那么一个服务窗口来处理所有人员业务办理,人少的时候,肯定是能够办理完的,如果人特别多的时候恩?一个服务窗口肯定是没有办法处理完这么多业务办理的。于是就出现如下图这样,一大堆人排队。

这时候银行就会多开几个窗口来办理业务,将原本堆积在一个窗口上处理的业务,分配到几个窗口上,这样业务办理就会加快了,但是仅仅是多开几个窗口是不够的。
为什么?因为没办法保证让某个人在某个窗口办理业务。大家可能还是会乱套(举个极端例子:假设A窗口的小姐姐特别的漂亮,会不会她那里会有很多的男客户排队办理业务恩?),因此银行除了多开几个窗口以外,还会设置一个排号,你拿到排号在哪个窗口,你就在哪个窗口进行办理业务。
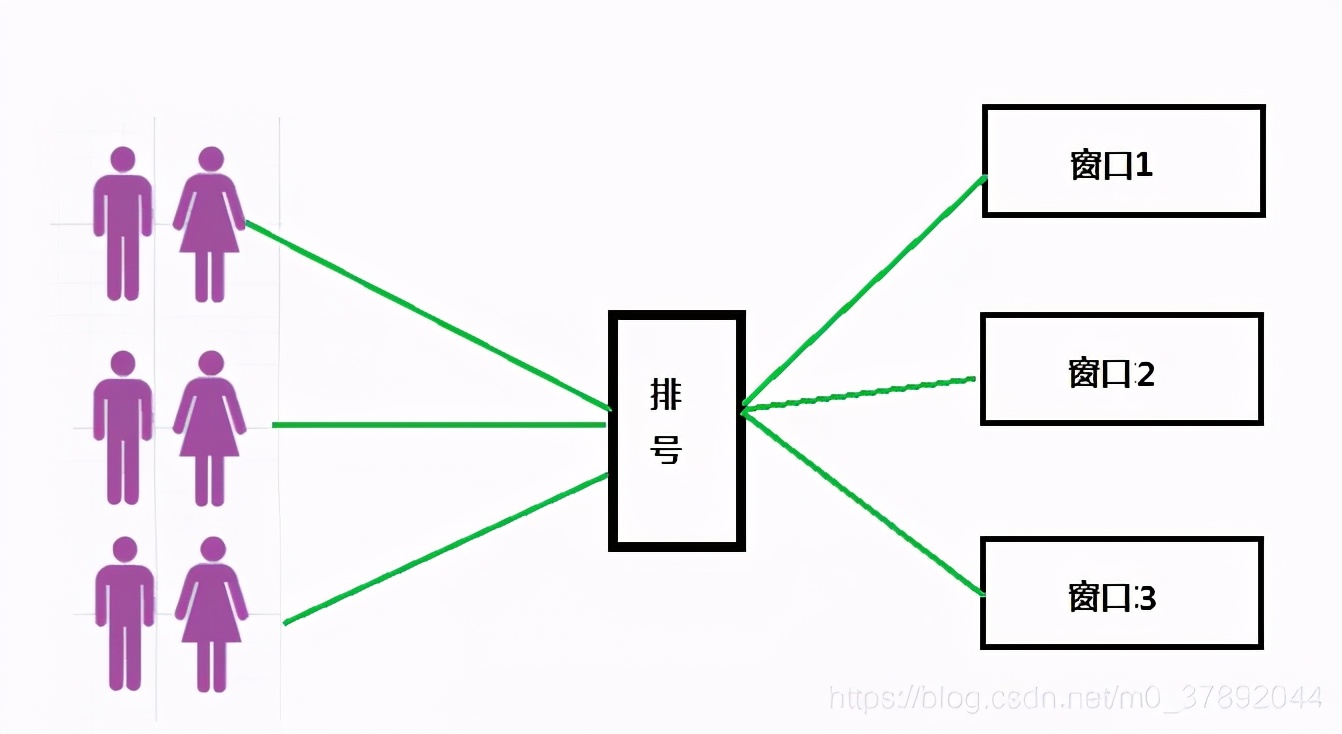
在我们负载均衡中 ,客户端(PC/移动/第三方)发起请求,就好比办理业务的人员。负载均衡器(load balancer)就好比取号机,当他接收到一个请求的时候,负载均衡器就会给这个请求,分配一个服务来处理请求。就像取号机一样,负载均衡器按照一定规则分配一个窗口来办理业务。
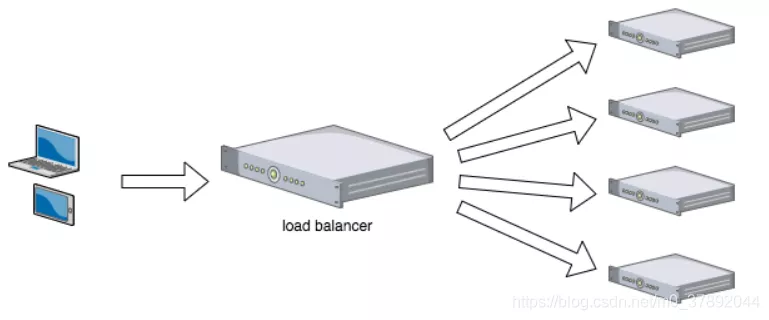
因此,在Spring cloud中,如果我们只提供一个服务,那么很可能会出现我们上面所说的一个窗口处理业务,处理不完的情况,导致大量人员排队等候。
在微服务Spring Cloud快速入门中,如果我们的商品服务一个不够用的话,根据负载均衡的理论,那我们就可以多注册几个服务。防止一个服务无法承载高并发时的情况。
启动注册中心、商品服务,订单服务,登录注册中心,查看我们当前的服务

此时,我们的商品服务和订单服务都只是一个服务,那么如何注册多个商品服务呢?
以同样的项目代码,设定端口为8091,其余配置均和之前的商品服务保持一致,然后启动商品服务。
server:
port: 8091 #服务端口
spring:
application:
name: hutao-microservice-item #指定服务名
eureka:
client:
registerWithEureka: true #是否将自己注册到Eureka服务中,默认为true
fetchRegistry: true #是否从Eureka中获取注册信息,默认为true
serviceUrl: #Eureka客户端与Eureka服务端进行交互的地址
defaultZone: http://127.0.0.1:9090/eureka/
instance:
prefer-ip-address: true #将自己的ip地址注册到Eureka服务中
点击如下所示,可以看到我们启动了1个注册中心,1个订单服务,2个商品服务

这时我们可以访问一下注册中心,我们可以发现,注册中心里面,商品服务有两个,一个是8081端口,一个是8091端口,并且他们的服务ID都是:HUTAO-MICROSERVICE-ITEM,这个服务ID和我们在配置文件中,配置的服务ID(spring.application.name)是保持一致的。
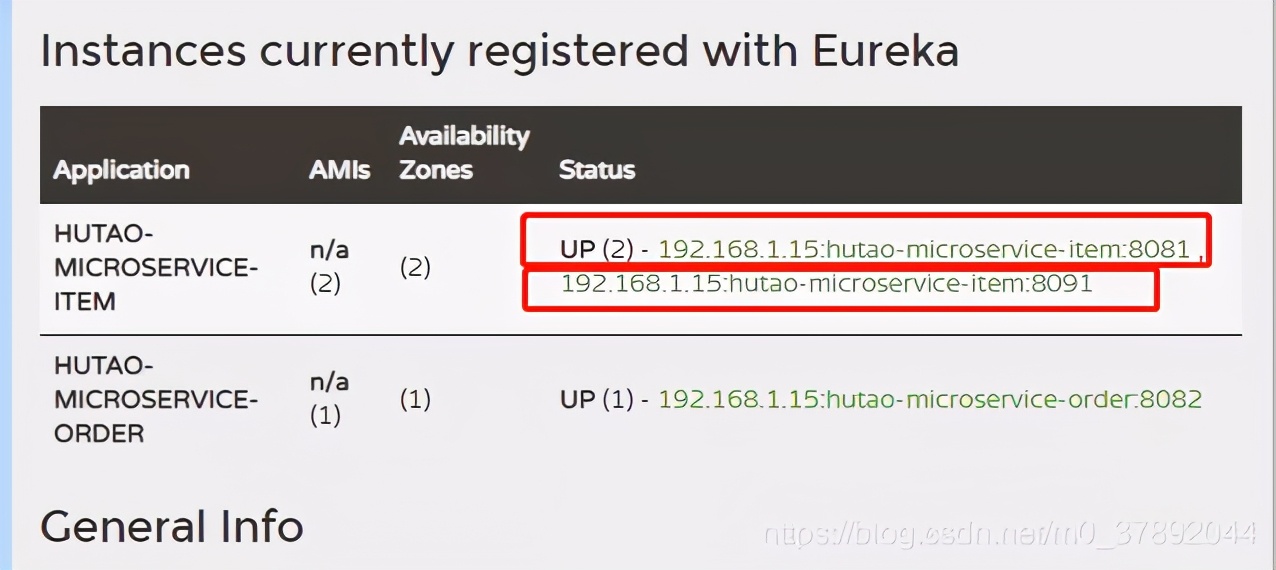
也就是说,我们通过服务ID:hutao-microservice-item在注册中心里面,能够找到两个服务
在微服务Spring Cloud快速入门中我们定义了如下Feign接口,在这个接口上面,我们添加了一个注解@FeignClient,指定了服务ID:hutao-microservice-item。这个Feign接口会给我发起Http调用。当然在这里我们可能无法看到负载均衡的效果,因此我们需要稍微深入下底层代码。
@FeignClient(value = "hutao-microservice-item")
@RequestMapping("/itemservice")
public interface FeignOrderService {
/**
* @Description:使用声明式HTTP客户端发起请求:根据ID查询订单
* @author hutao
* @mail hutao_2017@aliyun.com
* @date 2020年8月30日
*/
@GetMapping(value = "item/{itemId}")
Items queryItem(@PathVariable("itemId")String itemId);
}
大家应该还记得,我们的商品服务和订单服务,注册到注册中心的时候,我们在启动类上面添加了一个注解:@EnableDiscoveryClient。
现在我们来看下DiscoveryClient这个接口
DiscoveryClient接口源码如下,他是用来发现服务的,比如发现Netflix服务,其中有个方法List getInstances(String serviceId)是根据服务ID获取服务实例集合。
/**
* Represents read operations commonly available to discovery services such as Netflix
* Eureka or consul.io.
*
* @author Spencer Gibb
* @author Olga Maciaszek-Sharma
*/
public interface DiscoveryClient extends Ordered {
/**
* Default order of the discovery client.
*/
int DEFAULT_ORDER = 0;
/**
* A human-readable description of the implementation, used in HealthIndicator.
* @return The description.
*/
String description();
/**
* Gets all ServiceInstances associated with a particular serviceId.
* @param serviceId The serviceId to query.
* @return A List of ServiceInstance.
*/
List<ServiceInstance> getInstances(String serviceId);
/**
* @return All known service IDs.
*/
List<String> getServices();
/**
* Default implementation for getting order of discovery clients.
* @return order
*/
@Override
default int getOrder() {
return DEFAULT_ORDER;
}
}
我们可以看到DiscoveryClient 有4个实现,当然这里我们用的肯定是Eureka。
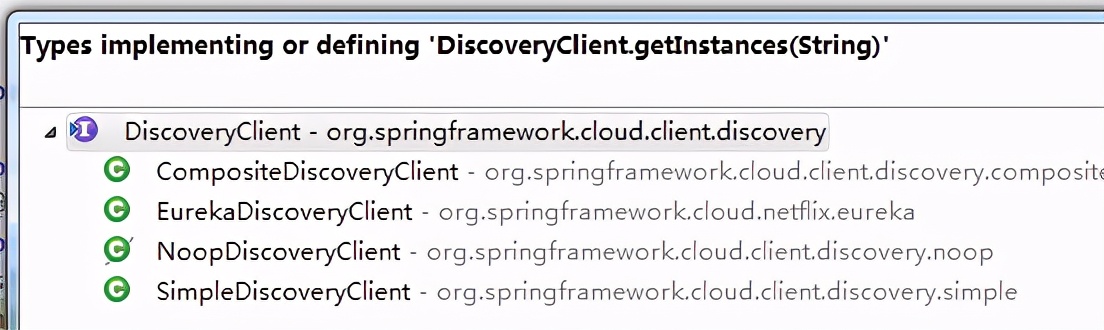
现在我们来使用下DiscoveryClient 这个接口
首先把这个接口依赖注入到我们的Controller中,我们看下能获取到什么
@Autowired
private DiscoveryClient discoveryClient;
@GetMapping(value = "order/{orderId}")
public Order queryOrderById(@PathVariable("orderId") String orderId) {
String serviceId = "hutao-microservice-item";
List<ServiceInstance> instances = discoveryClient.getInstances(serviceId);
System.out.println(instances);
return null;
}
通过调试代码,我们发现如我们之前所说,我们可以通过服务ID:hutao-microservice-item,找到两个服务实例。
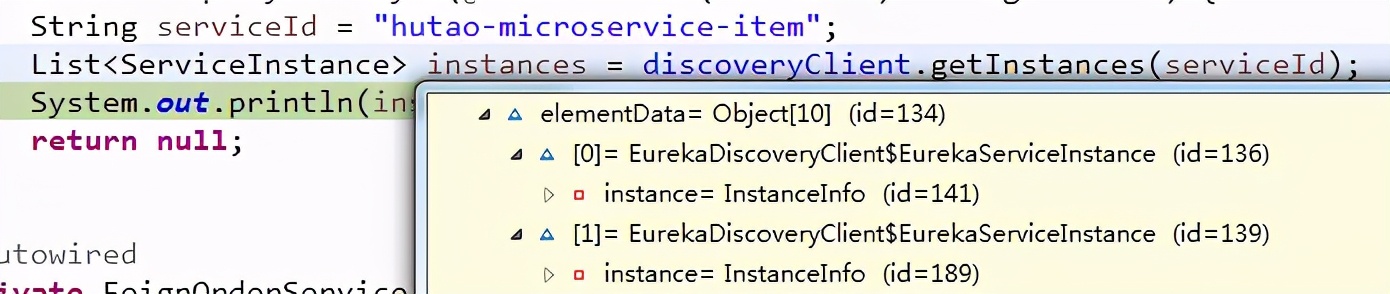
查看每个实例,我们发现我们能够看到每个服务的地址,端口等信息
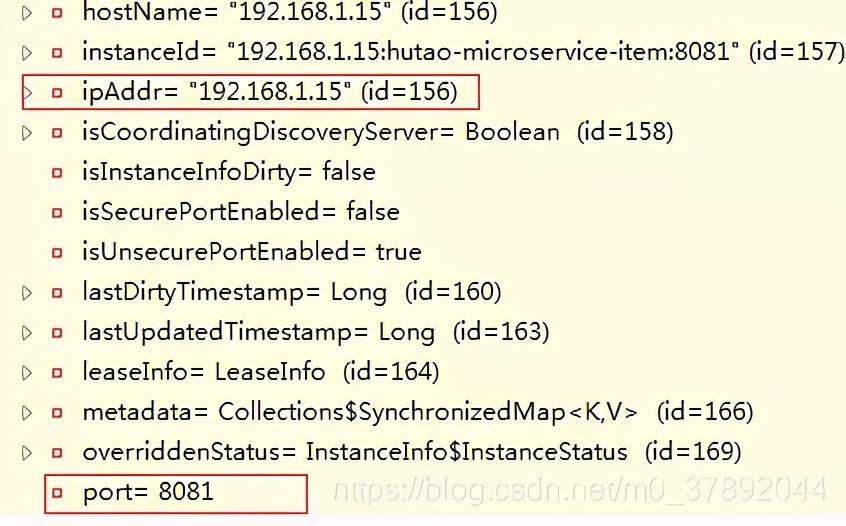
如果不使用Feign这种声明式的调用Http请求,那我们来如何调用?
那么这个时候,我们怎么去发起请求恩?很简单,就是从服务实例中,获取到服务信息后,将接口的请求地址拼接出来。然后使用restTemplate发起Http请求
@Autowired
private RestTemplate restTemplate;
@GetMapping(value = "order/{orderId}")
public Order queryOrderById(@PathVariable("orderId") String orderId) {
String serviceId = "hutao-microservice-item";
List<ServiceInstance> instances = discoveryClient.getInstances(serviceId);
ServiceInstance serviceInstance = instances.get(0);
String url = serviceInstance.getHost() + ":" + serviceInstance.getPort();
Items items = restTemplate.getForObject("http://" + url + "/itemservice/item/1" , Items.class);
System.out.println(items);
return null;
}
可以看到我们的请求是能正常访问的。当然也有问题存在,那就是我们拿到的是多个服务,程序怎么知道我要调用的是哪一个服务呢?
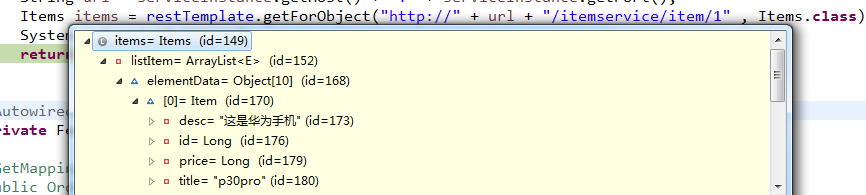
上述案例中,我们获取到的实例是两个,那么每次调用的时候,我们怎么来确定,我要调用的是哪一个服务?,因为这时候我们拿到的两个服务,也就是两个不同的IP地址,这时候就需要一个负载均衡器来帮我们选择一个IP进行访问。
在Spring Cloud中,netfix提供一个负载均衡器Ribbon,该负载均衡器是声明式的,其用法如下所示,在我们注入到Spring容器中的RestTemplate添加注解@LoadBalanced,这时候我们的RestTemplate就具备了负载均衡的功能。
注意:RestTemplate底层默认使用的jdk的标准实现,如果我们想让RestTemplate的底层使用okhttp,可以替换实现的。如下源码所示,RestTemplate提供了三个构造方法。
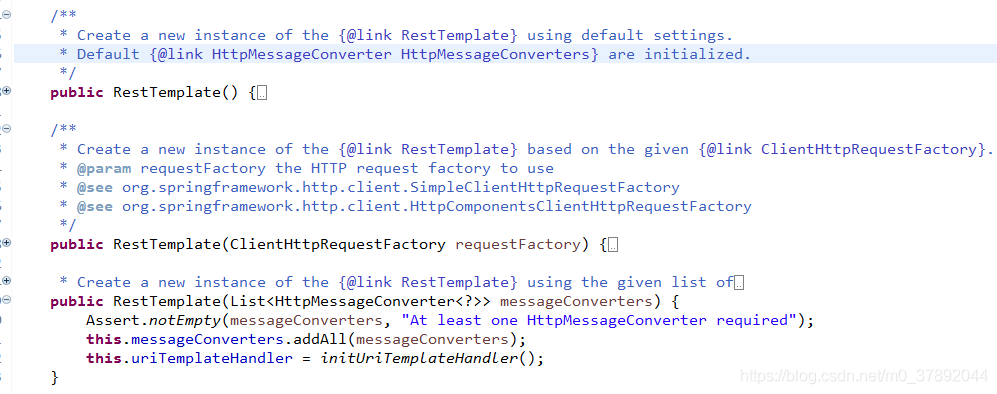
我们可以使用上述的第二个构造方法,使用Okhttp。

@SpringBootConfiguration
public class RestTemplateConfig {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
在上面的一个案例中,我们通过从服务实例中,获取到服务,然后再从服务中心获取具体的IP地址信息,发起请求。
String url = serviceInstance.getHost() + ":" + serviceInstance.getPort();
Items items = restTemplate.getForObject("http://" + url + "/itemservice/item/1" ,
但是,现在我们不需要这么做了,因为我们对restTemplate声明了是需要负载均衡的,因此我们发起请求的时候,就不需要指定IP地址了,我们可以用服务ID来代替IP地址,然后由restTemplate来帮我选择需要调用的IP。因此上述代码会被简化为如下所示,被注释掉的代码就是被优化的代码。
@GetMapping(value = "order/{orderId}")
public Order queryOrderById(@PathVariable("orderId") String orderId) {
String serviceId = "hutao-microservice-item";
//List<ServiceInstance> instances = discoveryClient.getInstances(serviceId);
//ServiceInstance serviceInstance = instances.get(0);
//String url = serviceInstance.getHost() + ":" + serviceInstance.getPort();
//Items items = restTemplate.getForObject("http://" + url + "/itemservice/item/1" , Items.class);
Items items = restTemplate.getForObject("http://" + serviceId + "/itemservice/item/1" , Items.class);
System.out.println(items);
return null;
}
重启服务后,商品服务仍然可用,那么这时候怎么来验证我们的负载均衡成功了?
其实最简单的验证方式就是,在商品服务中,添加日志,看看哪个服务记录了日志或者debug调试,看走哪一个服务的代码。即可验证我们的负载均衡是否成功。
当然这里我们就不做上述方式的演示,来做一点高难度的代码分析。
1、首先看org.springframework.web.client.RestTemplate类。
当我们执行如下代码时
restTemplate.getForObject("http://" + serviceId + "/itemservice/item/1" , Items.class);
最终会执行到如下方法
doExecute(URI, HttpMethod, RequestCallback, ResponseExtractor<T>)
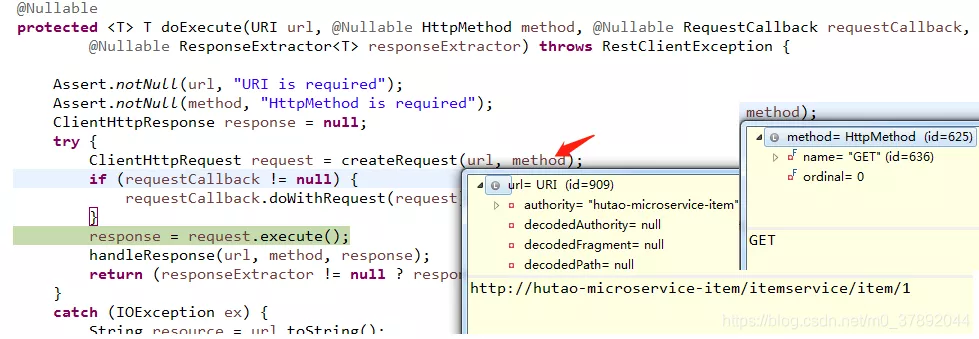
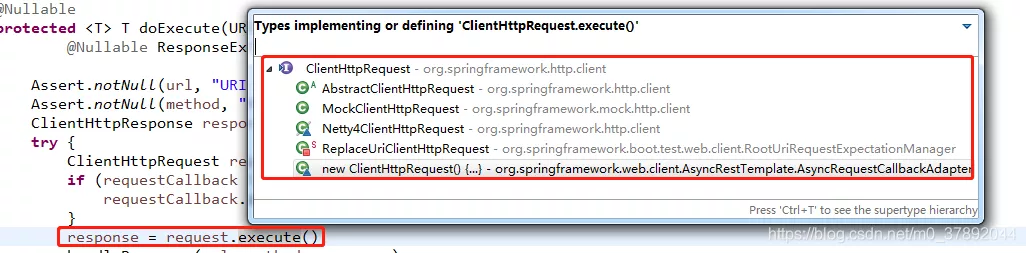
如上代码根据我们的提供的信息,创建了ClientHttpRequest请求, 我们发现doExecute有如下几个实现,这里由于我们使用的是默认的RestTemplate,因此我们查看org.springframework.http.client.AbstractClientHttpRequest这个类的org.springframework.http.client.AbstractClientHttpRequest.execute()方法。
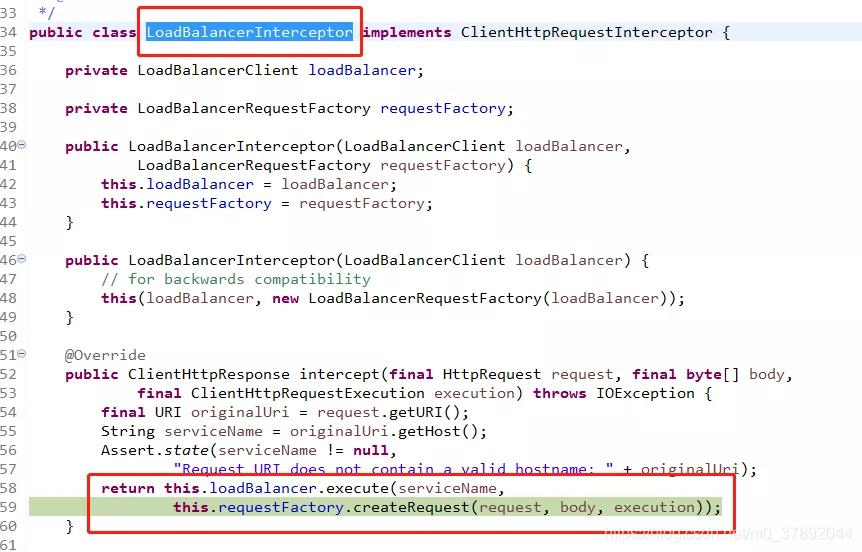
逐步深入代码,我们找到了如下的拦截器。LoadBalancerInterceptororg.springframework.cloud.client.loadbalancer.LoadBalancerInterceptor
继续深入代码,我们找到了RibbonLoadBalancerClient这个类org.springframework.cloud.netflix.ribbon.RibbonLoadBalancerClient通过查看代码,我们发现了getLoadBalancer(String)这个方法通过serviceId找到了两个服务实例,
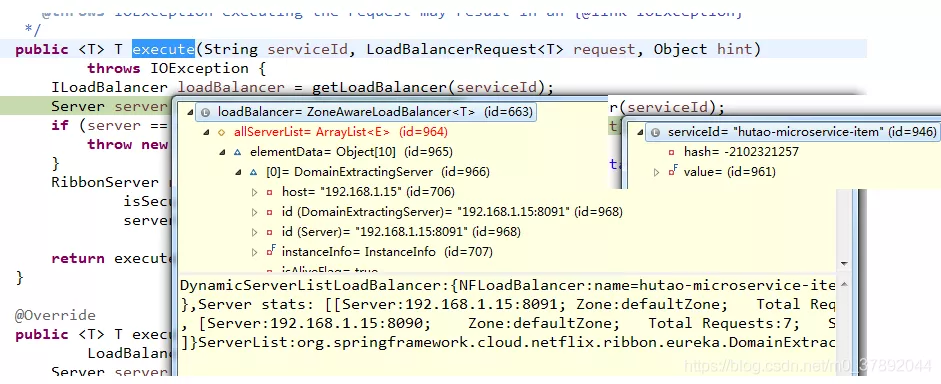
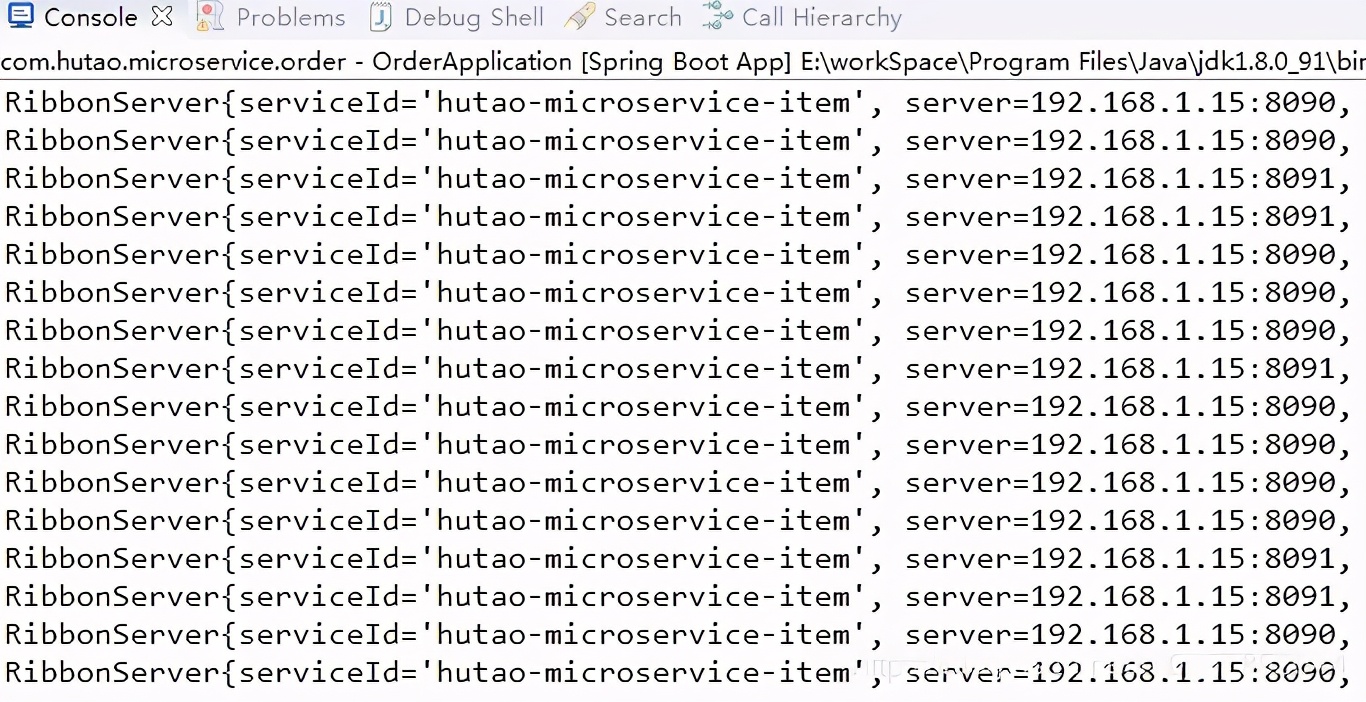
接着执行完毕getServer这个方法后,我们发现,只有一个服务实例了为8090。第二次调试代码后发现获取的是8091.多次调试后发现是8090和8091是轮询出现的,
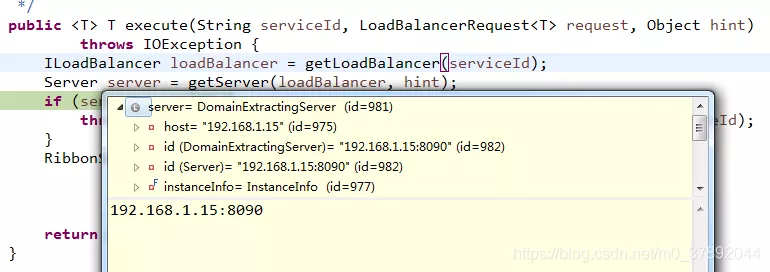
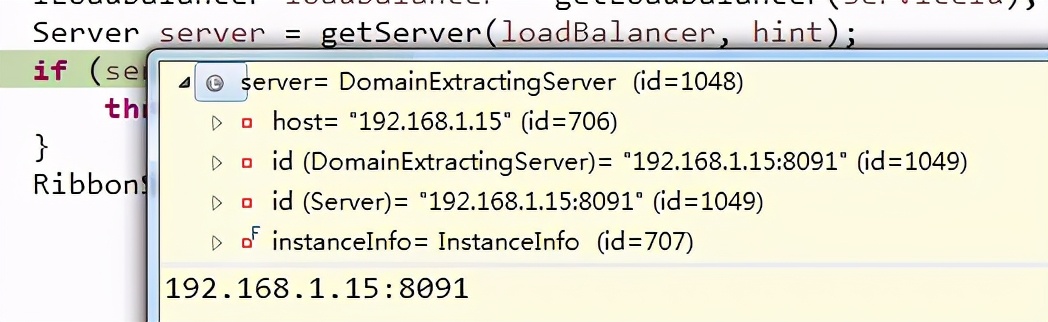
也就是说getServer这个方法给我们实现了负载均衡。看源代码知道,如果未设置负载均衡参数,就使用default。否则就根据配置的参数选择服务。
protected Server getServer(ILoadBalancer loadBalancer, Object hint) {
if (loadBalancer == null) {
return null;
}
// Use 'default' on a null hint, or just pass it on#
return loadBalancer.chooseServer(hint != null # hint : "default");
}
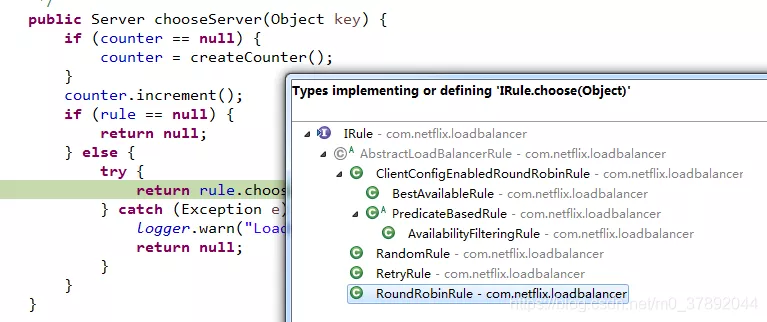
具体的实现的负载均衡算法,本文不做讨论。
通过上述源码分析,我们发现如果我们开启了负载均衡,但是没有配置负载均衡参数,则会采用默认的配置,也就是轮询算法来实现负载均衡。
通过上述的debug阅读,我们参照getServer这个方法来写代码测试下负载均衡
@Autowired
private LoadBalancerClient loadBalancerClient;
@GetMapping(value = "order/{orderId}")
public Order queryOrderById(@PathVariable("orderId") String orderId) {
String serviceId = "hutao-microservice-item";
for(int i = 0 ; i < 10 ; i++) {
ServiceInstance choose = loadBalancerClient.choose(serviceId);
System.out.println(choose);
}
//List<ServiceInstance> instances = discoveryClient.getInstances(serviceId);
//ServiceInstance serviceInstance = instances.get(0);
//String url = serviceInstance.getHost() + ":" + serviceInstance.getPort();
//Items items = restTemplate.getForObject("http://" + serviceId + "/itemservice/item/1" , Items.class);
//System.out.println(items);
return null;
}
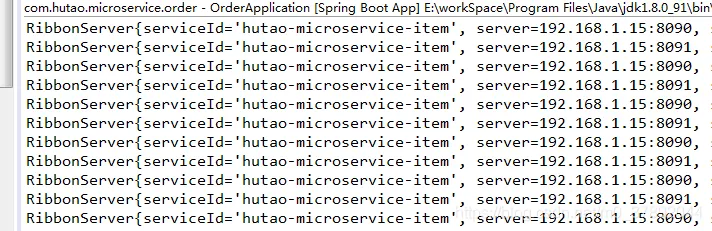
在我们之前调试代码的时候我们发现源码中定义了IRule.choose(Object objet)这个接口,并且如下几个实现。
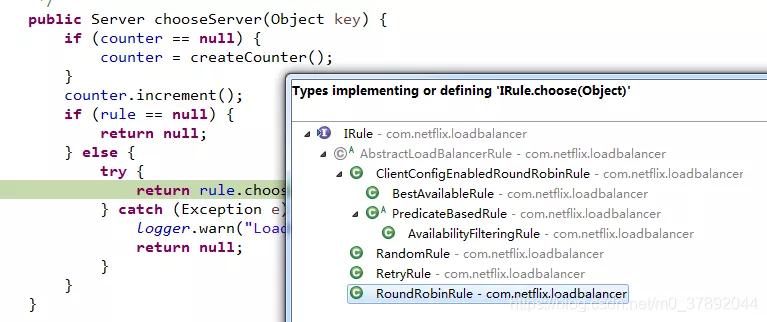
各个实现如下所示。
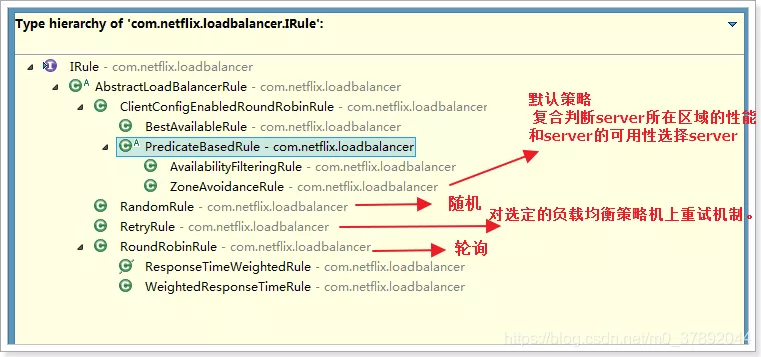
如果我们不想要默认的轮询机制,我们可以采用如上实现中的任何一种
比如,我们设置为随机策略。
hutao-microservice-item:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
重启服务后,再看我们的负载均衡,是随机的,而不是轮询的。
 关注微信
关注微信