
在移动互联网的应用中,经常需要根据用户的位置信息等做一些用户侧信息的统计分析。而要拿到用户的位置信息,一般有两个方法: GPS 定位的信息和用户 IP 地址。由于每个手机都不一定会打开 GPS,而且有时并不太需要太精确的位置(到城市这个级别即可),所以根据 IP 地址入手来分析用户位置是个不错的选择。 要做到这个功能得需要一个 IP 和地理位置的映射关系库,并依赖这个库启动一个 IP 转地理位置的服务。本文从需求入手,结合 Github 上拥有 8.4k 星的 ip2region 来分析映射关系库的设计以及 IP 如何快速转换成地理位置。
IP 定位服务很常见,而且很多公司都提供了类似的付费服务,比如阿里,高德,百度等,当然也有公开的免费服务,像 GeoIP,纯真IP等。这些服务要么通过 HTML 页面解析,要么通过接口请求,但不管怎样都离不开一次 http 请求,更不用说大部分服务都对 QPS 作了限制。下表枚举了一些常见的通过 IP 获取地址的方式。
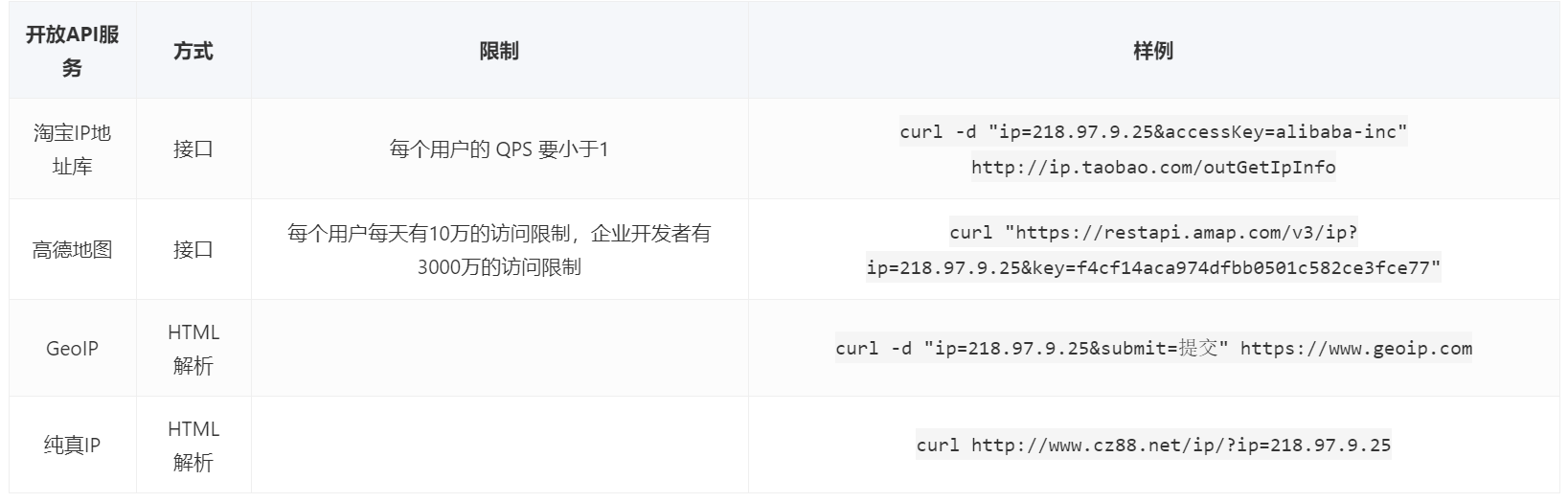
在日常工作通常需要将大量用户请求日志中 IP 转换成用户位置信息,用作后续的分析。这其中的关键是数据量大,处理要快。显然每次都通过请求 API 公共服务的方式无法满足我们的日常需求。
对于日常的需求,一种简单粗暴的做法就是提前通过 API 获取所有公网 IP 对应的位置信息,按照下面的 TIPS 中我们可以估算出如果通过访问淘宝IP地址库来遍历 3.3 亿的国内 IP 地址要 10 年。如果是高德的企业用户遍历国内 IP 地址大概要 11 天。感觉这个 11 天还是能够接受的。
TIPS: IPv4
目前所说的 IP 地址是指 IPv4,它是使用 32 位(4 字节)地址,因此地址空间约有 42.9 亿$2^32=4294967296$个, 不过一些地址是作为特殊用途所保留的,如专用网络(约 1800 万个)和多播地址(约 2.7 亿个),这些减少了可在互联网上路由的地址数量。 据 wiki 上统计,中国的 IPv4 数量达到 3.3 亿,而美国有 15.4 亿个。
这里我们约定一下位置信息的数据格式: 国家|区域|省份|城市|ISP,如果接口中返回的字段没有对应的信息,则对应的字段填充0。那么我们通过顺序请求 API 服务可以获取到如下文件数据(地址依次递增):
0.0.0.0|0|0|0|内网IP|内网IP
0.0.0.1|0|0|0|内网IP|内网IP
...
1.0.15.255|中国|0|广东省|广州市|电信
...
255.255.255.255|0|0|0|内网IP|内网IP
只要有了这个文件,可以将其读到内存中,使用字典保存,键为 IP 地址,值为位置信息。程序可以在 O(1) 时间复杂度内返回位置信息,不过该程序或文件占用的大小我们可以粗略的计算一下。 假定我们使用 utf-8 进行存储,一条记录最短的情况是 0.0.0.0|0|0|0|0|0,占用17个字节,IP 库文件的大小为 17*4294967296 = 73014444032 B = 71303MB = 71GB。这个大小是任意一个程序不能接受的。
从上面的文件数据发现大量的相邻 IP 拥有相同的位置信息(客户在申请一段 IP 地址都会尽量连在一起),所以我们可以将这样的记录合成一条记录。如下文件数据(地址段依次递增):
0.0.0.0|0.255.255.255|0|0|0|内网IP|内网IP
...
1.0.8.0|1.0.15.255|中国|0|广东省|广州市|电信
...
224.0.0.0|255.255.255.255|0|0|0|内网IP|内网IP
ip2region 库中最新的 ip.merge.txt 共有 658207 记录,文件大小 39 M。
从上面的文件数据发现大量的IP地址以字符串形式存储,而 IPv4 是使用 32 位地址。所以将其转换成整型进行存储可以大大节省空间,比如像最短的字符串 0.0.0.0 占据 7 字节,最长的字符串 111.111.111.111 占据 15 字节,如果将其转换成整型,他们都占据 4 字节。0.0.0.0 是 int(0), 111.111.111.111 是 int(1869573999)。
从上面的文件数据发现相同的位置信息会对应不同的 IP 段(客户可能在不同的时间段去申请 IP 段),所以还是有大量的位置信息在 IP 库文件中,在内存中我们可以只保留一份位置信息,并使用指针或者文件偏移量+数据长度来获取对应的位置信息。
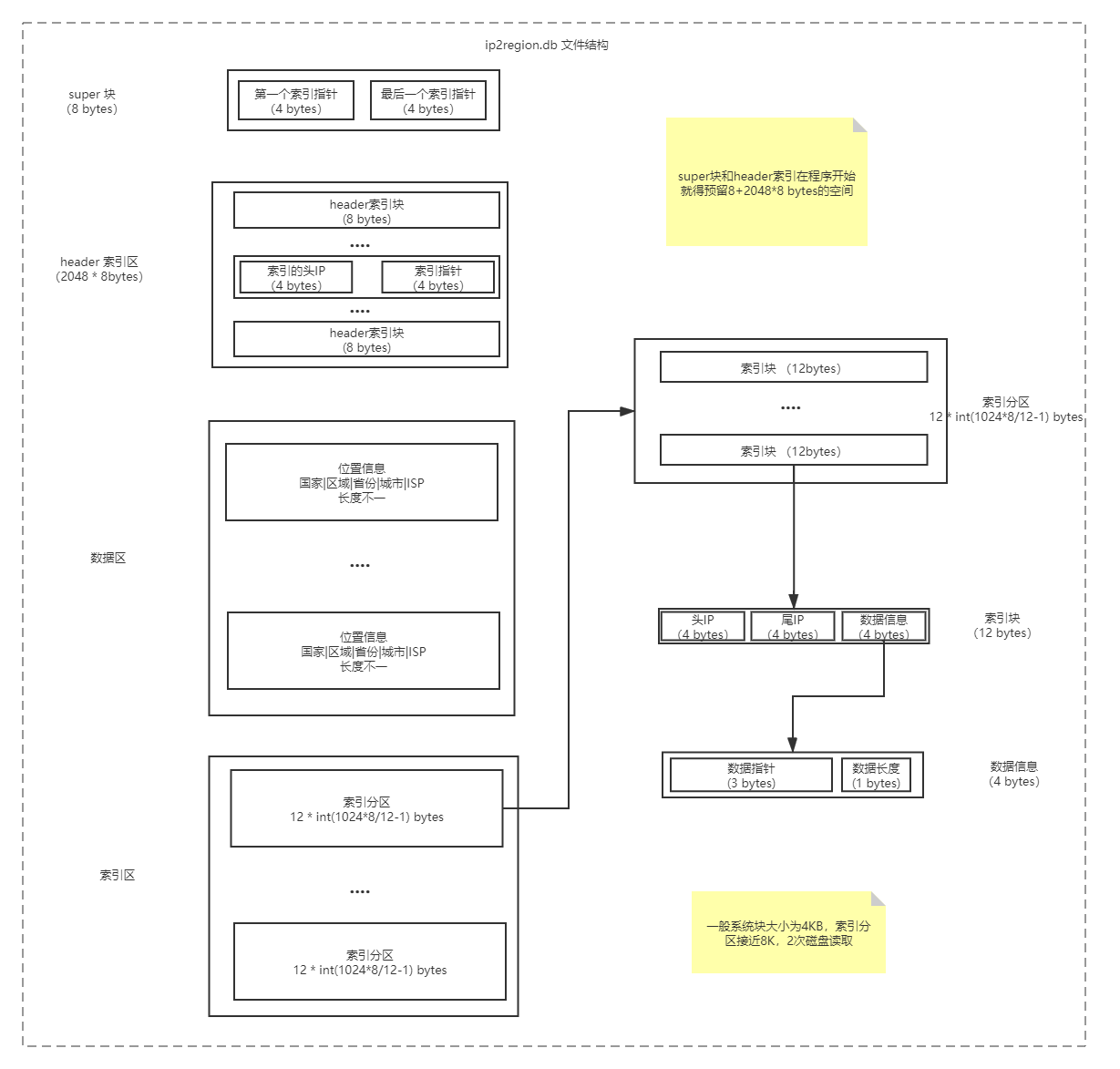
根据上面的优化,我们可以生成最终的IP库:ip2region.db,该文件只有8.1M。
IP 库文件ip2region.db的结构分为四个部分:super 块, header索引区,数据区,索引区。具体如下图所示:
ip2region 的 Github 仓库中提供了 ip2region.db 的生成过程,是用 JAVA 写的,其类图如下所示:
通过熟悉生成 ip2region.db 的源码,简述一下其生成过程如下:
TIPS: ip2region 仓库中还使用了 global_region.csv 数据,该文件有5列(行号,,区域,,邮政编码),对应着区域的具体信息,可以往数据区每个位置信息中填充。
ip2region 提供三种查询算法,最差的查询耗时都是ms级别的。分别是内存二分搜索,b+tree搜索,二分查找。耗时依次增加。其搜索结构图如下:
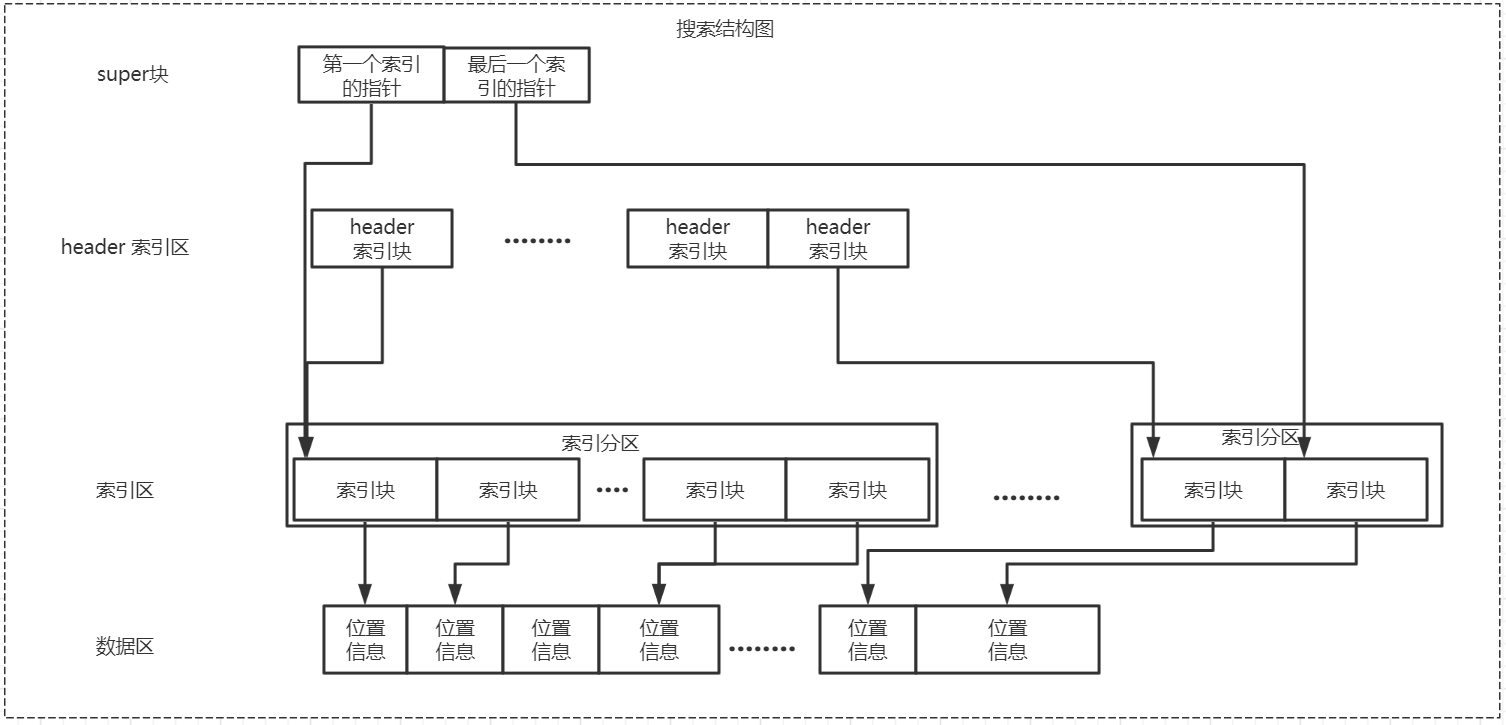
通过 super 块可以拿到索引区的起始位置和结束位置,而且每个索引块都是 12 bytes,其中的 IP 地址都是递增的,所以可以使用二分搜索来快速获取位置信息。其步骤如下:
b+tree 搜索用到了 header 索引区,第一步先在 header 索引区中使用二分搜索,定位到某个索引分区后,再在对应的索引分区中使用二分搜索。相比较二分搜索而言,它的速度更快,原因是读磁盘的次数远低于二分搜索。其步骤如下:
该方法和二分搜索方法类似,区别就是前者将 ip2region.db 全部读进内存中,后者则是通过不断读取 ip2region.db 文件。
ip2region 库只解决了一个非常常见的 IP 定位问题,但将这个服务做到了又小又快(当然还提供了多语言的客户端),从而在 Github 上获得了 8.4k 的 star。
支持 java、C#、php、c、python、nodejs、php扩展(php5和php7)、golang、rust、lua、lua_c, nginx。
 关注微信
关注微信